 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads
Jun 04, 2026LLM agents are increasingly deployed on long-horizon tasks requiring sustained reasoning over extended interaction histories. Realizing this at scale requires agents to persistently store, retrieve, and update their own memory across sessions. A rich ecosystem of agent memory systems has emerged spanning flat retrieval, LLM-mediated extraction, consolidating fact stores, and agentic control flows. Yet, their system-level behavior remains uncharacterized. We present the first systems characterization of agent memory. First, we introduce a system-oriented taxonomy classifying agent memory systems along four axes. Second, we build a phase-aware profiling harness attributing cost to construction, retrieval, and generation. Third, we characterize ten representative systems across two benchmark suites, uncovering how design choices shift cost across the write and read paths. Finally, we derive 10 system recommendations covering construction scheduling, capability floors, amortization via query volume, freshness-latency tradeoffs, and fleet-scale management.
Vision-Language Alignment from Compressed Image Representations using 2D Gaussian Splatting
Sep 26, 2025Modern vision language pipelines are driven by RGB vision encoders trained on massive image text corpora. While these pipelines have enabled impressive zero shot capabilities and strong transfer across tasks, they still inherit two structural inefficiencies from the pixel domain: (i) transmitting dense RGB images from edge devices to the cloud is energy intensive and costly, and (ii) patch based tokenization explodes sequence length, stressing attention budgets and context limits. We explore 2D Gaussian Splatting (2DGS) as an alternative visual substrate for alignment: a compact, spatially adaptive representation that parameterizes images by a set of colored anisotropic Gaussians. We develop a scalable 2DGS pipeline with structured initialization, luminance aware pruning, and batched CUDA kernels, achieving over 90x faster fitting and about 97% GPU utilization compared to prior implementations. We further adapt contrastive language image pretraining (CLIP) to 2DGS by reusing a frozen RGB-based transformer backbone with a lightweight splat aware input stem and a perceiver resampler, training only about 7% of the total parameters. On large DataComp subsets, GS encoders yield meaningful zero shot ImageNet-1K performance while compressing inputs 3 to 20x relative to pixels. While accuracy currently trails RGB encoders, our results establish 2DGS as a viable multimodal substrate, pinpoint architectural bottlenecks, and open a path toward representations that are both semantically powerful and transmission efficient for edge cloud learning.
Win Fast or Lose Slow: Balancing Speed and Accuracy in Latency-Sensitive Decisions of LLMs
May 26, 2025Large language models (LLMs) have shown remarkable performance across diverse reasoning and generation tasks, and are increasingly deployed as agents in dynamic environments such as code generation and recommendation systems. However, many real-world applications, such as high-frequency trading and real-time competitive gaming, require decisions under strict latency constraints, where faster responses directly translate into higher rewards. Despite the importance of this latency quality trade off, it remains underexplored in the context of LLM based agents. In this work, we present the first systematic study of this trade off in real time decision making tasks. To support our investigation, we introduce two new benchmarks: HFTBench, a high frequency trading simulation, and StreetFighter, a competitive gaming platform. Our analysis reveals that optimal latency quality balance varies by task, and that sacrificing quality for lower latency can significantly enhance downstream performance. To address this, we propose FPX, an adaptive framework that dynamically selects model size and quantization level based on real time demands. Our method achieves the best performance on both benchmarks, improving win rate by up to 80% in Street Fighter and boosting daily yield by up to 26.52% in trading, underscoring the need for latency aware evaluation and deployment strategies for LLM based agents. These results demonstrate the critical importance of latency aware evaluation and deployment strategies for real world LLM based agents. Our benchmarks are available at Latency Sensitive Benchmarks.
ItDPDM: Information-Theoretic Discrete Poisson Diffusion Model
May 08, 2025
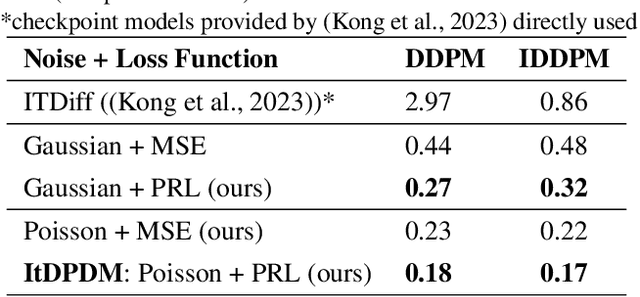


Existing methods for generative modeling of discrete data, such as symbolic music tokens, face two primary challenges: (1) they either embed discrete inputs into continuous state-spaces or (2) rely on variational losses that only approximate the true negative log-likelihood. Previous efforts have individually targeted these limitations. While information-theoretic Gaussian diffusion models alleviate the suboptimality of variational losses, they still perform modeling in continuous domains. In this work, we introduce the Information-Theoretic Discrete Poisson Diffusion Model (ItDPDM), which simultaneously addresses both limitations by directly operating in a discrete state-space via a Poisson diffusion process inspired by photon arrival processes in camera sensors. We introduce a novel Poisson Reconstruction Loss (PRL) and derive an exact relationship between PRL and the true negative log-likelihood, thereby eliminating the need for approximate evidence lower bounds. Experiments conducted on the Lakh MIDI symbolic music dataset and the CIFAR-10 image benchmark demonstrate that ItDPDM delivers significant improvements, reducing test NLL by up to 80% compared to prior baselines, while also achieving faster convergence.
Universal Discrete Filtering with Lookahead or Delay
Jan 17, 2025



We consider the universal discrete filtering problem, where an input sequence generated by an unknown source passes through a discrete memoryless channel, and the goal is to estimate its components based on the output sequence with limited lookahead or delay. We propose and establish the universality of a family of schemes for this setting. These schemes are induced by universal Sequential Probability Assignments (SPAs), and inherit their computational properties. We show that the schemes induced by LZ78 are practically implementable and well-suited for scenarios with limited computational resources and latency constraints. In passing, we use some of the intermediate results to obtain upper and lower bounds that appear to be new, in the purely Bayesian setting, on the optimal filtering performance in terms, respectively, of the mutual information between the noise-free and noisy sequence, and the entropy of the noise-free sequence causally conditioned on the noisy one.
Lottery Ticket Adaptation: Mitigating Destructive Interference in LLMs
Jun 25, 2024



Existing methods for adapting large language models (LLMs) to new tasks are not suited to multi-task adaptation because they modify all the model weights -- causing destructive interference between tasks. The resulting effects, such as catastrophic forgetting of earlier tasks, make it challenging to obtain good performance on multiple tasks at the same time. To mitigate this, we propose Lottery Ticket Adaptation (LoTA), a sparse adaptation method that identifies and optimizes only a sparse subnetwork of the model. We evaluate LoTA on a wide range of challenging tasks such as instruction following, reasoning, math, and summarization. LoTA obtains better performance than full fine-tuning and low-rank adaptation (LoRA), and maintains good performance even after training on other tasks -- thus, avoiding catastrophic forgetting. By extracting and fine-tuning over lottery tickets (or sparse task vectors), LoTA also enables model merging over highly dissimilar tasks. Our code is made publicly available at https://github.com/kiddyboots216/lottery-ticket-adaptation.
Communication-Efficient Federated Learning through Importance Sampling
Jun 25, 2023
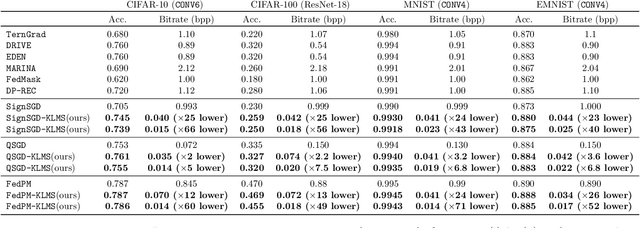
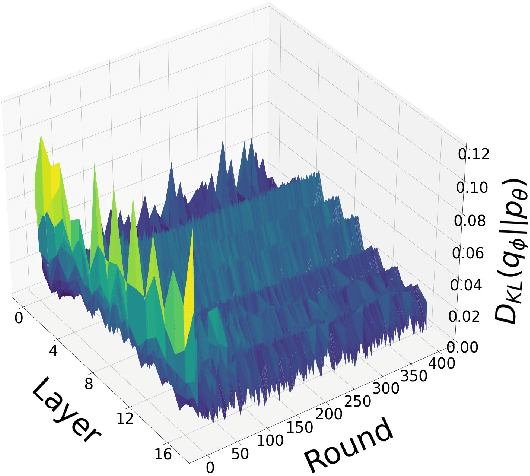
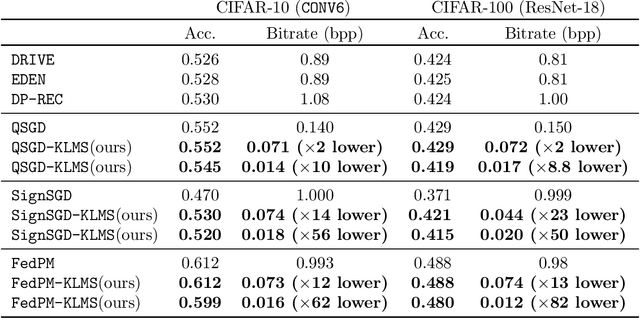
The high communication cost of sending model updates from the clients to the server is a significant bottleneck for scalable federated learning (FL). Among existing approaches, state-of-the-art bitrate-accuracy tradeoffs have been achieved using stochastic compression methods -- in which the client $n$ sends a sample from a client-only probability distribution $q_{\phi^{(n)}}$, and the server estimates the mean of the clients' distributions using these samples. However, such methods do not take full advantage of the FL setup where the server, throughout the training process, has side information in the form of a pre-data distribution $p_{\theta}$ that is close to the client's distribution $q_{\phi^{(n)}}$ in Kullback-Leibler (KL) divergence. In this work, we exploit this closeness between the clients' distributions $q_{\phi^{(n)}}$'s and the side information $p_{\theta}$ at the server, and propose a framework that requires approximately $D_{KL}(q_{\phi^{(n)}}|| p_{\theta})$ bits of communication. We show that our method can be integrated into many existing stochastic compression frameworks such as FedPM, Federated SGLD, and QSGD to attain the same (and often higher) test accuracy with up to $50$ times reduction in the bitrate.
Exact Optimality of Communication-Privacy-Utility Tradeoffs in Distributed Mean Estimation
Jun 08, 2023

We study the mean estimation problem under communication and local differential privacy constraints. While previous work has proposed \emph{order}-optimal algorithms for the same problem (i.e., asymptotically optimal as we spend more bits), \emph{exact} optimality (in the non-asymptotic setting) still has not been achieved. In this work, we take a step towards characterizing the \emph{exact}-optimal approach in the presence of shared randomness (a random variable shared between the server and the user) and identify several necessary conditions for \emph{exact} optimality. We prove that one of the necessary conditions is to utilize a rotationally symmetric shared random codebook. Based on this, we propose a randomization mechanism where the codebook is a randomly rotated simplex -- satisfying the necessary properties of the \emph{exact}-optimal codebook. The proposed mechanism is based on a $k$-closest encoding which we prove to be \emph{exact}-optimal for the randomly rotated simplex codebook.
PIM: Video Coding using Perceptual Importance Maps
Dec 20, 2022Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
Leveraging the Hints: Adaptive Bidding in Repeated First-Price Auctions
Nov 05, 2022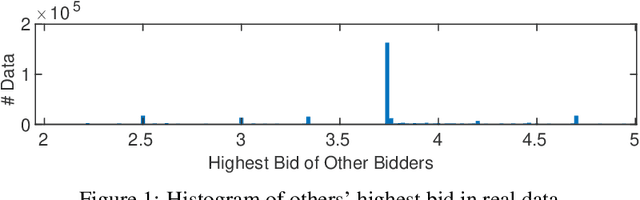



With the advent and increasing consolidation of e-commerce, digital advertising has very recently replaced traditional advertising as the main marketing force in the economy. In the past four years, a particularly important development in the digital advertising industry is the shift from second-price auctions to first-price auctions for online display ads. This shift immediately motivated the intellectually challenging question of how to bid in first-price auctions, because unlike in second-price auctions, bidding one's private value truthfully is no longer optimal. Following a series of recent works in this area, we consider a differentiated setup: we do not make any assumption about other bidders' maximum bid (i.e. it can be adversarial over time), and instead assume that we have access to a hint that serves as a prediction of other bidders' maximum bid, where the prediction is learned through some blackbox machine learning model. We consider two types of hints: one where a single point-prediction is available, and the other where a hint interval (representing a type of confidence region into which others' maximum bid falls) is available. We establish minimax optimal regret bounds for both cases and highlight the quantitatively different behavior between the two settings. We also provide improved regret bounds when the others' maximum bid exhibits the further structure of sparsity. Finally, we complement the theoretical results with demonstrations using real bidding data.