 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Practical Learned Image Compression
May 06, 2026One of the major differentiators unlocked by learned codecs relative to their hard-coded traditional counterparts is their ability to be optimized directly to appeal to the human visual system. Despite this potential, a perceptual yet practical image codec is yet to be proposed. In this work, we aim to close this gap. We conduct a comprehensive study of the key modeling choices that govern the design of a practical learned image codec, jointly optimized for perceptual quality and runtime -- including within the ablations several novel techniques. We then perform performance-aware neural architecture search over millions of backbone configurations to identify models that achieve the target on-device runtime while maximizing compression performance as captured by perceptual metrics. We combine the various optimizations to construct a new codec that achieves a significantly improved tradeoff between speed and perceptual quality. Based on rigorous subjective user studies, it provides 2.3-3x bitrate savings against AV1, AV2, VVC, ECM and JPEG-AI, and 20-40% bitrate savings against the best learned codec alternatives. At the same time, on an iPhone 17 Pro Max, it encodes 12MP images as fast as 230ms, and decodes them in 150ms -- faster than most top ML-based codecs run on a V100 GPU.
Drop-In Perceptual Optimization for 3D Gaussian Splatting
Mar 23, 2026Despite their output being ultimately consumed by human viewers, 3D Gaussian Splatting (3DGS) methods often rely on ad-hoc combinations of pixel-level losses, resulting in blurry renderings. To address this, we systematically explore perceptual optimization strategies for 3DGS by searching over a diverse set of distortion losses. We conduct the first-of-its-kind large-scale human subjective study on 3DGS, involving 39,320 pairwise ratings across several datasets and 3DGS frameworks. A regularized version of Wasserstein Distortion, which we call WD-R, emerges as the clear winner, excelling at recovering fine textures without incurring a higher splat count. WD-R is preferred by raters more than $2.3\times$ over the original 3DGS loss, and $1.5\times$ over current best method Perceptual-GS. WD-R also consistently achieves state-of-the-art LPIPS, DISTS, and FID scores across various datasets, and generalizes across recent frameworks, such as Mip-Splatting and Scaffold-GS, where replacing the original loss with WD-R consistently enhances perceptual quality within a similar resource budget (number of splats for Mip-Splatting, model size for Scaffold-GS), and leads to reconstructions being preferred by human raters $1.8\times$ and $3.6\times$, respectively. We also find that this carries over to the task of 3DGS scene compression, with $\approx 50\%$ bitrate savings for comparable perceptual metric performance.
PIM: Video Coding using Perceptual Importance Maps
Dec 20, 2022Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
An Interactive Annotation Tool for Perceptual Video Compression
May 08, 2022


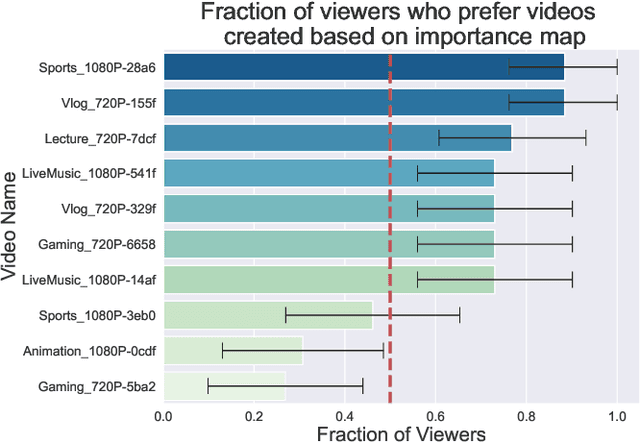
Human perception is at the core of lossy video compression and yet, it is challenging to collect data that is sufficiently dense to drive compression. In perceptual quality assessment, human feedback is typically collected as a single scalar quality score indicating preference of one distorted video over another. In reality, some videos may be better in some parts but not in others. We propose an approach to collecting finer-grained feedback by asking users to use an interactive tool to directly optimize for perceptual quality given a fixed bitrate. To this end, we built a novel web-tool which allows users to paint these spatio-temporal importance maps over videos. The tool allows for interactive successive refinement: we iteratively re-encode the original video according to the painted importance maps, while maintaining the same bitrate, thus allowing the user to visually see the trade-off of assigning higher importance to one spatio-temporal part of the video at the cost of others. We use this tool to collect data in-the-wild (10 videos, 17 users) and utilize the obtained importance maps in the context of x264 coding to demonstrate that the tool can indeed be used to generate videos which, at the same bitrate, look perceptually better through a subjective study - and are 1.9 times more likely to be preferred by viewers. The code for the tool and dataset can be found at https://github.com/jenyap/video-annotation-tool.git
ELF-VC: Efficient Learned Flexible-Rate Video Coding
Apr 29, 2021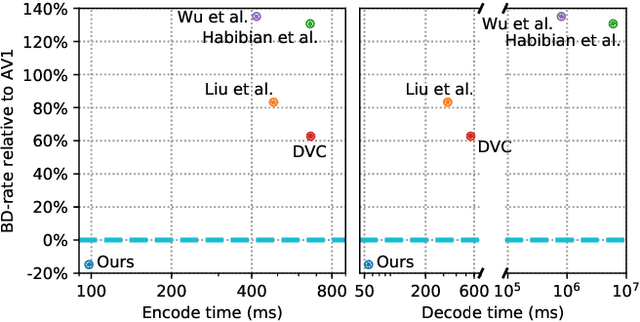
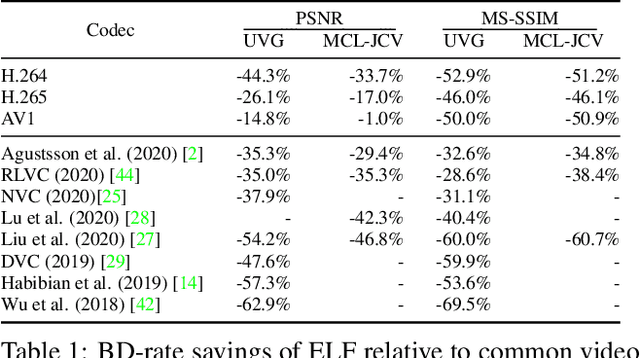
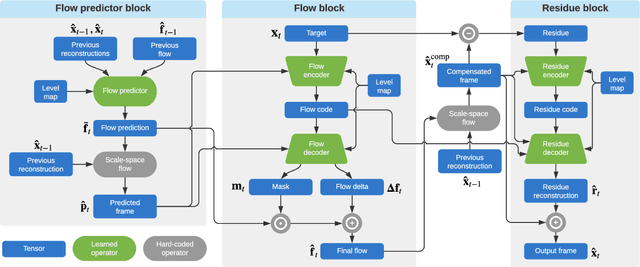

While learned video codecs have demonstrated great promise, they have yet to achieve sufficient efficiency for practical deployment. In this work, we propose several novel ideas for learned video compression which allow for improved performance for the low-latency mode (I- and P-frames only) along with a considerable increase in computational efficiency. In this setting, for natural videos our approach compares favorably across the entire R-D curve under metrics PSNR, MS-SSIM and VMAF against all mainstream video standards (H.264, H.265, AV1) and all ML codecs. At the same time, our approach runs at least 5x faster and has fewer parameters than all ML codecs which report these figures. Our contributions include a flexible-rate framework allowing a single model to cover a large and dense range of bitrates, at a negligible increase in computation and parameter count; an efficient backbone optimized for ML-based codecs; and a novel in-loop flow prediction scheme which leverages prior information towards more efficient compression. We benchmark our method, which we call ELF-VC (Efficient, Learned and Flexible Video Coding) on popular video test sets UVG and MCL-JCV under metrics PSNR, MS-SSIM and VMAF. For example, on UVG under PSNR, it reduces the BD-rate by 44% against H.264, 26% against H.265, 15% against AV1, and 35% against the current best ML codec. At the same time, on an NVIDIA Titan V GPU our approach encodes/decodes VGA at 49/91 FPS, HD 720 at 19/35 FPS, and HD 1080 at 10/18 FPS.
DZip: improved general-purpose lossless compression based on novel neural network modeling
Nov 08, 2019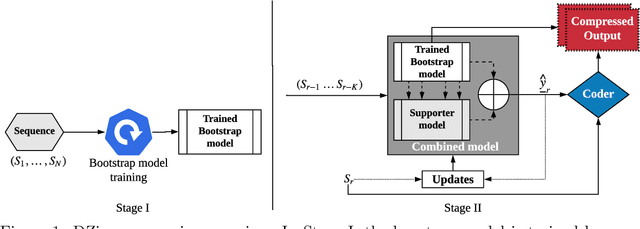

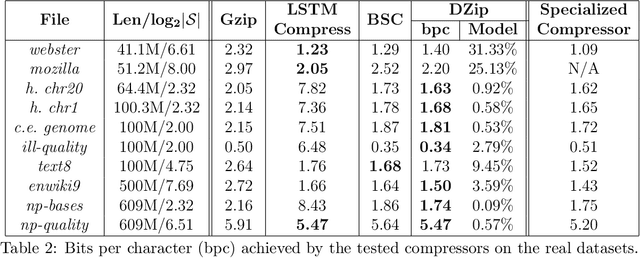

We consider lossless compression based on statistical data modeling followed by prediction-based encoding, where an accurate statistical model for the input data leads to substantial improvements in compression. We propose DZip, a general-purpose compressor for sequential data that exploits the well-known modeling capabilities of neural networks (NNs) for prediction, followed by arithmetic coding. Dzip uses a novel hybrid architecture based on adaptive and semi-adaptive training. Unlike most NN based compressors, DZip does not require additional training data and is not restricted to specific data types, only needing the alphabet size of the input data. The proposed compressor outperforms general-purpose compressors such as Gzip (on average 26% reduction) on a variety of real datasets, achieves near-optimal compression on synthetic datasets, and performs close to specialized compressors for large sequence lengths, without any human input. The main limitation of DZip in its current implementation is the encoding/decoding time, which limits its practicality. Nevertheless, the results showcase the potential of developing improved general-purpose compressors based on neural networks and hybrid modeling.
LFZip: Lossy compression of multivariate floating-point time series data via improved prediction
Nov 01, 2019

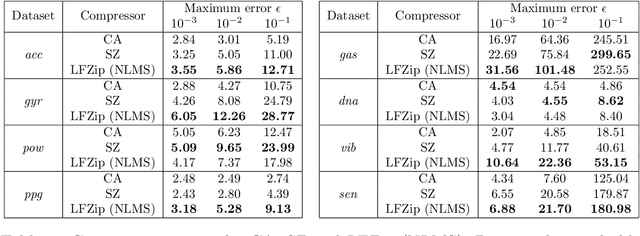
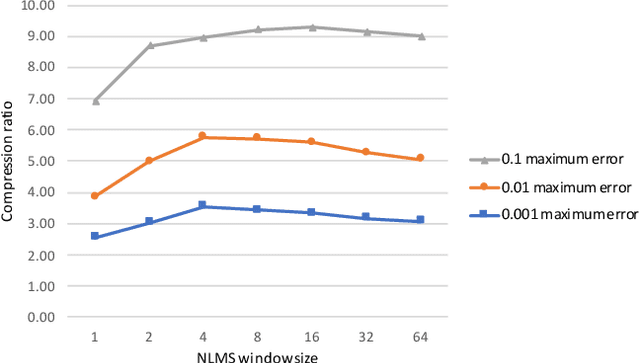
Time series data compression is emerging as an important problem with the growth in IoT devices and sensors. Due to the presence of noise in these datasets, lossy compression can often provide significant compression gains without impacting the performance of downstream applications. In this work, we propose an error-bounded lossy compressor, LFZip, for multivariate floating-point time series data that provides guaranteed reconstruction up to user-specified maximum absolute error. The compressor is based on the prediction-quantization-entropy coder framework and benefits from improved prediction using linear models and neural networks. We evaluate the compressor on several time series datasets where it outperforms the existing state-of-the-art error-bounded lossy compressors. The code and data are available at https://github.com/shubhamchandak94/LFZip
DeepZip: Lossless Data Compression using Recurrent Neural Networks
Nov 20, 2018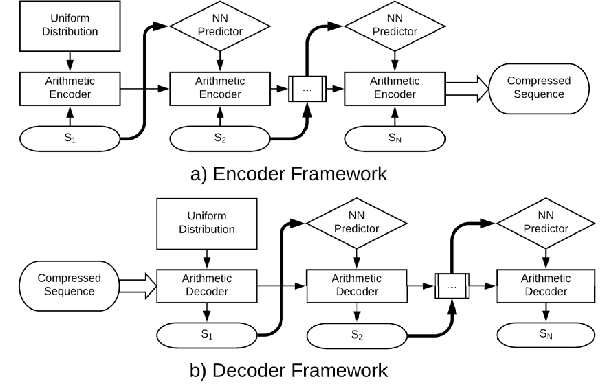
Sequential data is being generated at an unprecedented pace in various forms, including text and genomic data. This creates the need for efficient compression mechanisms to enable better storage, transmission and processing of such data. To solve this problem, many of the existing compressors attempt to learn models for the data and perform prediction-based compression. Since neural networks are known as universal function approximators with the capability to learn arbitrarily complex mappings, and in practice show excellent performance in prediction tasks, we explore and devise methods to compress sequential data using neural network predictors. We combine recurrent neural network predictors with an arithmetic coder and losslessly compress a variety of synthetic, text and genomic datasets. The proposed compressor outperforms Gzip on the real datasets and achieves near-optimal compression for the synthetic datasets. The results also help understand why and where neural networks are good alternatives for traditional finite context models
NECST: Neural Joint Source-Channel Coding
Nov 19, 2018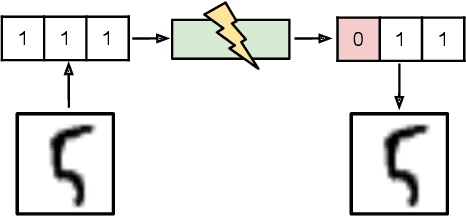

For reliable transmission across a noisy communication channel, classical results from information theory show that it is asymptotically optimal to separate out the source and channel coding processes. However, this decomposition can fall short in the finite bit-length regime, as it requires non-trivial tuning of hand-crafted codes and assumes infinite computational power for decoding. In this work, we propose Neural Error Correcting and Source Trimming (\modelname) codes to jointly learn the encoding and decoding processes in an end-to-end fashion. By adding noise into the latent codes to simulate the channel during training, we learn to both compress and error-correct given a fixed bit-length and computational budget. We obtain codes that are not only competitive against several capacity-approaching channel codes, but also learn useful robust representations of the data for downstream tasks such as classification. Finally, we learn an extremely fast neural decoder, yielding almost an order of magnitude in speedup compared to standard decoding methods based on iterative belief propagation.
Humans are still the best lossy image compressors
Oct 29, 2018
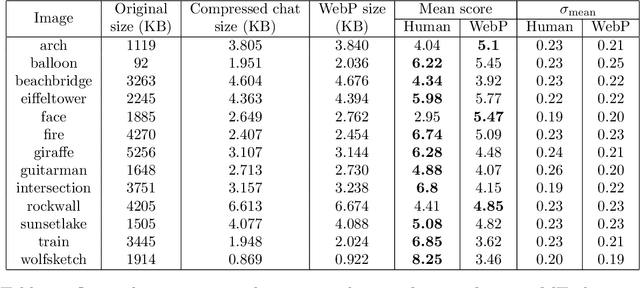
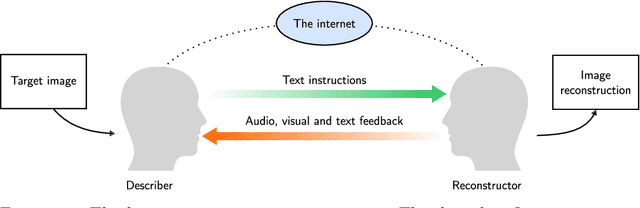
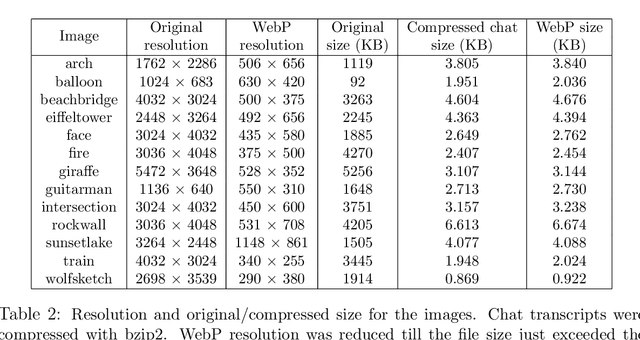
Lossy image compression has been studied extensively in the context of typical loss functions such as RMSE, MS-SSIM, etc. However, it is not well understood what loss function might be most appropriate for human perception. Furthermore, the availability of massive public image datasets appears to have hardly been exploited in image compression. In this work, we perform compression experiments in which one human describes images to another, using publicly available images and text instructions. These image reconstructions are rated by human scorers on the Amazon Mechanical Turk platform and compared to reconstructions obtained by existing image compressors. In our experiments, the humans outperform the state of the art compressor WebP in the MTurk survey on most images, which shows that there is significant room for improvement in image compression for human perception. The images, results and additional data is available at https://compression.stanford.edu/human-compression.