 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTxt2Vid: Ultra-Low Bitrate Compression of Talking-Head Videos via Text
Jun 26, 2021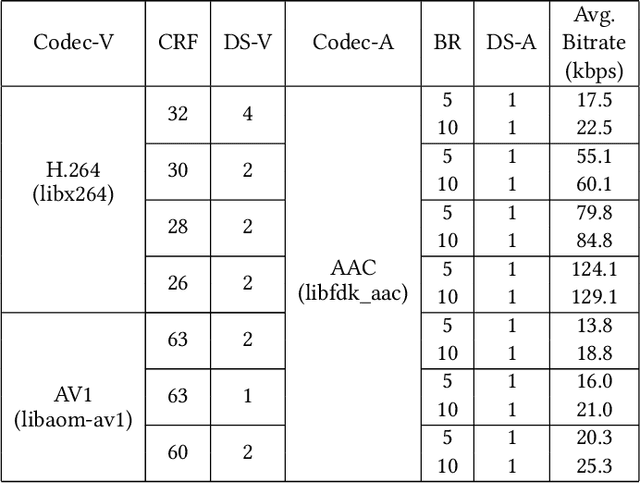
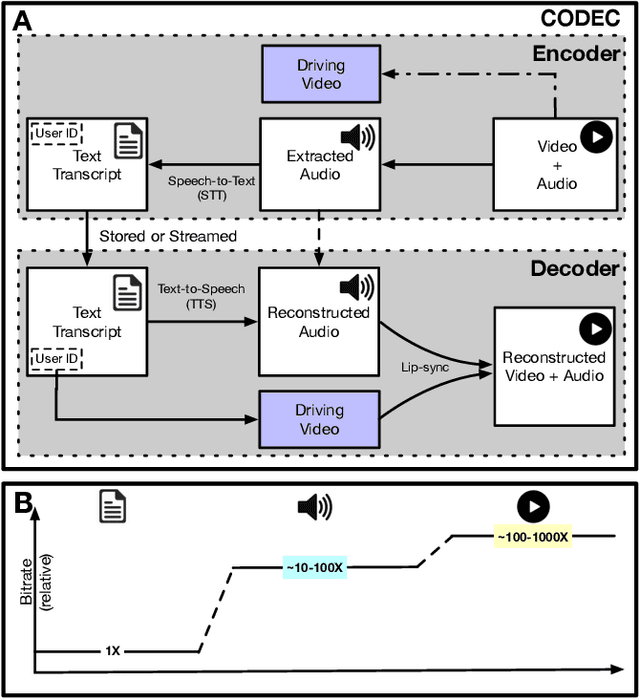
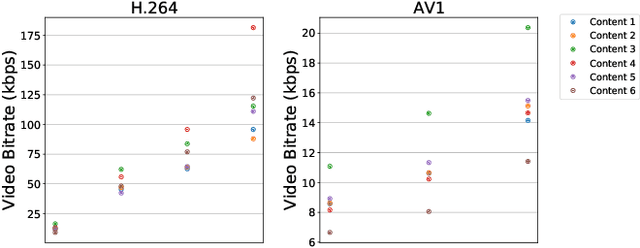
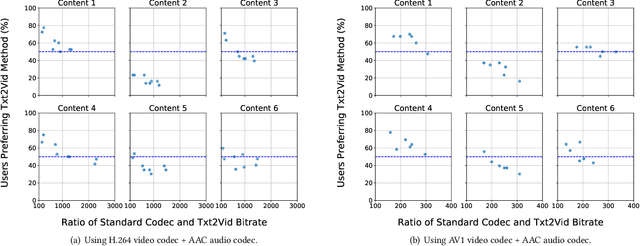
Video represents the majority of internet traffic today leading to a continuous technological arms race between generating higher quality content, transmitting larger file sizes and supporting network infrastructure. Adding to this is the recent COVID-19 pandemic fueled surge in the use of video conferencing tools. Since videos take up substantial bandwidth (~100 Kbps to few Mbps), improved video compression can have a substantial impact on network performance for live and pre-recorded content, providing broader access to multimedia content worldwide. In this work, we present a novel video compression pipeline, called Txt2Vid, which substantially reduces data transmission rates by compressing webcam videos ("talking-head videos") to a text transcript. The text is transmitted and decoded into a realistic reconstruction of the original video using recent advances in deep learning based voice cloning and lip syncing models. Our generative pipeline achieves two to three orders of magnitude reduction in the bitrate as compared to the standard audio-video codecs (encoders-decoders), while maintaining equivalent Quality-of-Experience based on a subjective evaluation by users (n=242) in an online study. The code for this work is available at https://github.com/tpulkit/txt2vid.git.
DZip: improved general-purpose lossless compression based on novel neural network modeling
Nov 08, 2019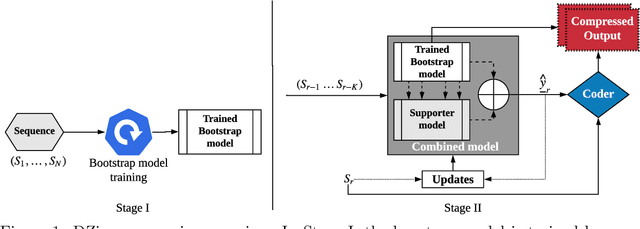

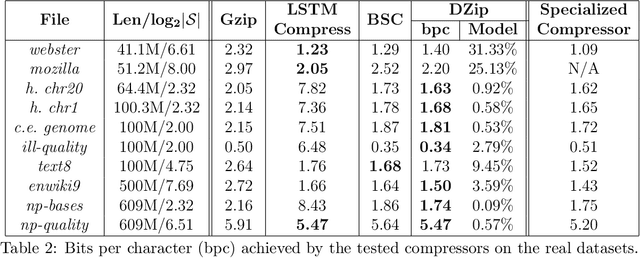

We consider lossless compression based on statistical data modeling followed by prediction-based encoding, where an accurate statistical model for the input data leads to substantial improvements in compression. We propose DZip, a general-purpose compressor for sequential data that exploits the well-known modeling capabilities of neural networks (NNs) for prediction, followed by arithmetic coding. Dzip uses a novel hybrid architecture based on adaptive and semi-adaptive training. Unlike most NN based compressors, DZip does not require additional training data and is not restricted to specific data types, only needing the alphabet size of the input data. The proposed compressor outperforms general-purpose compressors such as Gzip (on average 26% reduction) on a variety of real datasets, achieves near-optimal compression on synthetic datasets, and performs close to specialized compressors for large sequence lengths, without any human input. The main limitation of DZip in its current implementation is the encoding/decoding time, which limits its practicality. Nevertheless, the results showcase the potential of developing improved general-purpose compressors based on neural networks and hybrid modeling.
LFZip: Lossy compression of multivariate floating-point time series data via improved prediction
Nov 01, 2019

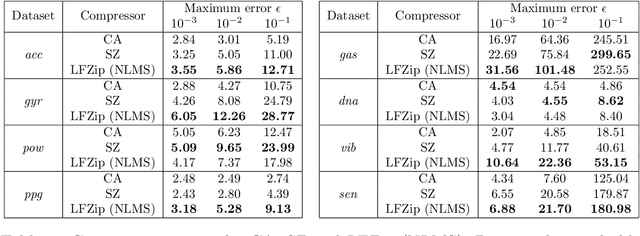
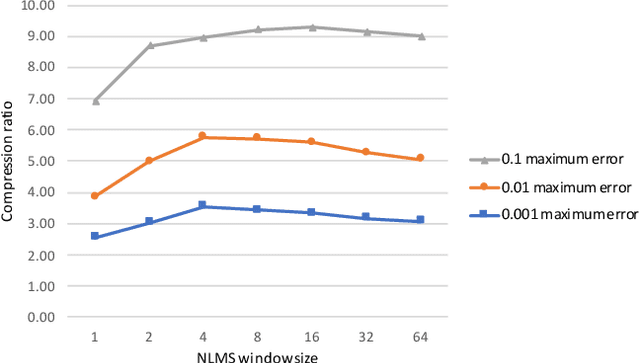
Time series data compression is emerging as an important problem with the growth in IoT devices and sensors. Due to the presence of noise in these datasets, lossy compression can often provide significant compression gains without impacting the performance of downstream applications. In this work, we propose an error-bounded lossy compressor, LFZip, for multivariate floating-point time series data that provides guaranteed reconstruction up to user-specified maximum absolute error. The compressor is based on the prediction-quantization-entropy coder framework and benefits from improved prediction using linear models and neural networks. We evaluate the compressor on several time series datasets where it outperforms the existing state-of-the-art error-bounded lossy compressors. The code and data are available at https://github.com/shubhamchandak94/LFZip
DeepZip: Lossless Data Compression using Recurrent Neural Networks
Nov 20, 2018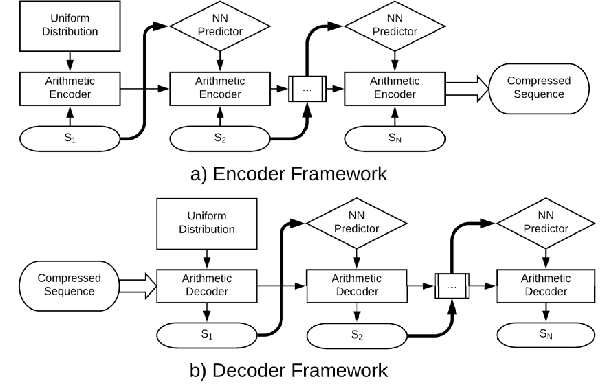
Sequential data is being generated at an unprecedented pace in various forms, including text and genomic data. This creates the need for efficient compression mechanisms to enable better storage, transmission and processing of such data. To solve this problem, many of the existing compressors attempt to learn models for the data and perform prediction-based compression. Since neural networks are known as universal function approximators with the capability to learn arbitrarily complex mappings, and in practice show excellent performance in prediction tasks, we explore and devise methods to compress sequential data using neural network predictors. We combine recurrent neural network predictors with an arithmetic coder and losslessly compress a variety of synthetic, text and genomic datasets. The proposed compressor outperforms Gzip on the real datasets and achieves near-optimal compression for the synthetic datasets. The results also help understand why and where neural networks are good alternatives for traditional finite context models
Humans are still the best lossy image compressors
Oct 29, 2018
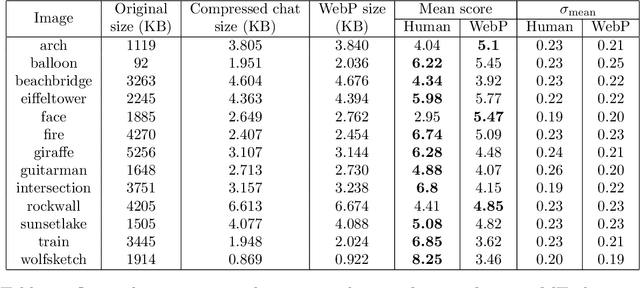
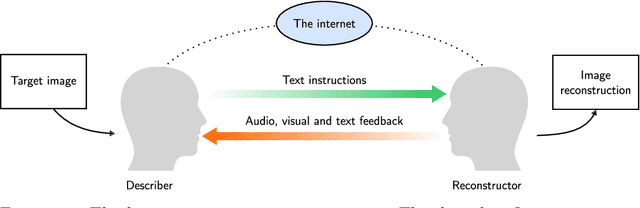
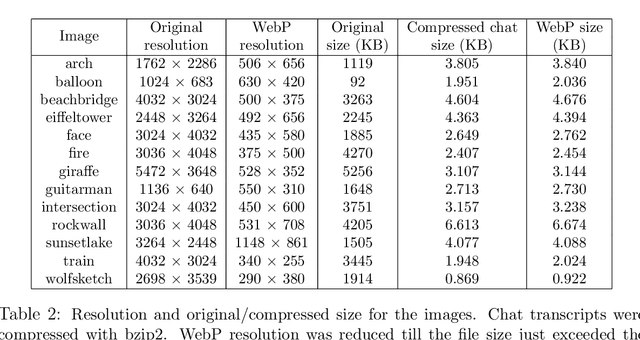
Lossy image compression has been studied extensively in the context of typical loss functions such as RMSE, MS-SSIM, etc. However, it is not well understood what loss function might be most appropriate for human perception. Furthermore, the availability of massive public image datasets appears to have hardly been exploited in image compression. In this work, we perform compression experiments in which one human describes images to another, using publicly available images and text instructions. These image reconstructions are rated by human scorers on the Amazon Mechanical Turk platform and compared to reconstructions obtained by existing image compressors. In our experiments, the humans outperform the state of the art compressor WebP in the MTurk survey on most images, which shows that there is significant room for improvement in image compression for human perception. The images, results and additional data is available at https://compression.stanford.edu/human-compression.