 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimGym: Traffic-Grounded Browser Agents for Offline A/B Testing in E-Commerce
Feb 01, 2026A/B testing remains the gold standard for evaluating e-commerce UI changes, yet it diverts traffic, takes weeks to reach significance, and risks harming user experience. We introduce SimGym, a scalable system for rapid offline A/B testing using traffic-grounded synthetic buyers powered by Large Language Model agents operating in a live browser. SimGym extracts per-shop buyer profiles and intents from production interaction data, identifies distinct behavioral archetypes, and simulates cohort-weighted sessions across control and treatment storefronts. We validate SimGym against real human outcomes from real UI changes on a major e-commerce platform under confounder control. Even without alignment post training, SimGym agents achieve state of the art alignment with observed outcome shifts and reduces experiment cycles from weeks to under an hour , enabling rapid experimentation without exposure to real buyers.
M-LLM Based Video Frame Selection for Efficient Video Understanding
Feb 27, 2025Recent advances in Multi-Modal Large Language Models (M-LLMs) show promising results in video reasoning. Popular Multi-Modal Large Language Model (M-LLM) frameworks usually apply naive uniform sampling to reduce the number of video frames that are fed into an M-LLM, particularly for long context videos. However, it could lose crucial context in certain periods of a video, so that the downstream M-LLM may not have sufficient visual information to answer a question. To attack this pain point, we propose a light-weight M-LLM -based frame selection method that adaptively select frames that are more relevant to users' queries. In order to train the proposed frame selector, we introduce two supervision signals (i) Spatial signal, where single frame importance score by prompting a M-LLM; (ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates. The selected frames are then digested by a frozen downstream video M-LLM for visual reasoning and question answering. Empirical results show that the proposed M-LLM video frame selector improves the performances various downstream video Large Language Model (video-LLM) across medium (ActivityNet, NExT-QA) and long (EgoSchema, LongVideoBench) context video question answering benchmarks.
SitPose: Real-Time Detection of Sitting Posture and Sedentary Behavior Using Ensemble Learning With Depth Sensor
Dec 16, 2024



Poor sitting posture can lead to various work-related musculoskeletal disorders (WMSDs). Office employees spend approximately 81.8% of their working time seated, and sedentary behavior can result in chronic diseases such as cervical spondylosis and cardiovascular diseases. To address these health concerns, we present SitPose, a sitting posture and sedentary detection system utilizing the latest Kinect depth camera. The system tracks 3D coordinates of bone joint points in real-time and calculates the angle values of related joints. We established a dataset containing six different sitting postures and one standing posture, totaling 33,409 data points, by recruiting 36 participants. We applied several state-of-the-art machine learning algorithms to the dataset and compared their performance in recognizing the sitting poses. Our results show that the ensemble learning model based on the soft voting mechanism achieves the highest F1 score of 98.1%. Finally, we deployed the SitPose system based on this ensemble model to encourage better sitting posture and to reduce sedentary habits.
Real-Time Fall Detection Using Smartphone Accelerometers and WiFi Channel State Information
Dec 13, 2024
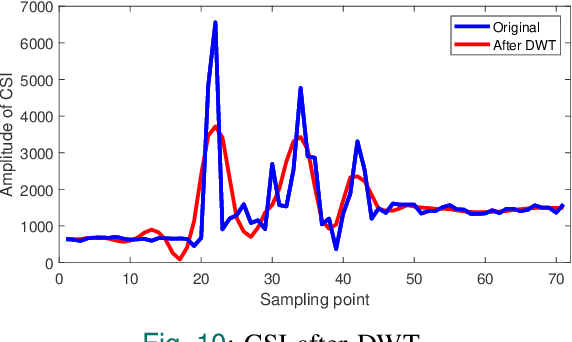
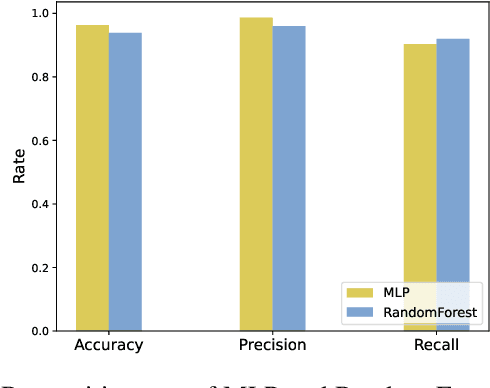
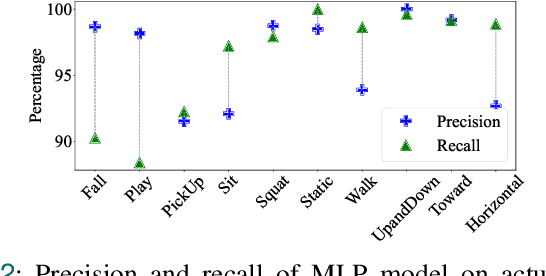
In recent years, as the population ages, falls have increasingly posed a significant threat to the health of the elderly. We propose a real-time fall detection system that integrates the inertial measurement unit (IMU) of a smartphone with optimized Wi-Fi channel state information (CSI) for secondary validation. Initially, the IMU distinguishes falls from routine daily activities with minimal computational demand. Subsequently, the CSI is employed for further assessment, which includes evaluating the individual's post-fall mobility. This methodology not only achieves high accuracy but also reduces energy consumption in the smartphone platform. An Android application developed specifically for the purpose issues an emergency alert if the user experiences a fall and is unable to move. Experimental results indicate that the CSI model, based on convolutional neural networks (CNN), achieves a detection accuracy of 99%, \revised{surpassing comparable IMU-only models, and demonstrating significant resilience in distinguishing between falls and non-fall activities.
Freqformer: Frequency-Domain Transformer for 3-D Visualization and Quantification of Human Retinal Circulation
Nov 17, 2024



We introduce Freqformer, a novel Transformer-based architecture designed for 3-D, high-definition visualization of human retinal circulation from a single scan in commercial optical coherence tomography angiography (OCTA). Freqformer addresses the challenge of limited signal-to-noise ratio in OCTA volume by utilizing a complex-valued frequency-domain module (CFDM) and a simplified multi-head attention (Sim-MHA) mechanism. Using merged volumes as ground truth, Freqformer enables accurate reconstruction of retinal vasculature across the depth planes, allowing for 3-D quantification of capillary segments (count, density, and length). Our method outperforms state-of-the-art convolutional neural networks (CNNs) and several Transformer-based models, with superior performance in peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and learned perceptual image patch similarity (LPIPS). Furthermore, Freqformer demonstrates excellent generalizability across lower scanning density, effectively enhancing OCTA scans with larger fields of view (from 3$\times$3 $mm^{2}$ to 6$\times$6 $mm^{2}$ and 12$\times$12 $mm^{2}$). These results suggest that Freqformer can significantly improve the understanding and characterization of retinal circulation, offering potential clinical applications in diagnosing and managing retinal vascular diseases.
Multimodal Instruction Tuning with Hybrid State Space Models
Nov 13, 2024



Handling lengthy context is crucial for enhancing the recognition and understanding capabilities of multimodal large language models (MLLMs) in applications such as processing high-resolution images or high frame rate videos. The rise in image resolution and frame rate substantially increases computational demands due to the increased number of input tokens. This challenge is further exacerbated by the quadratic complexity with respect to sequence length of the self-attention mechanism. Most prior works either pre-train models with long contexts, overlooking the efficiency problem, or attempt to reduce the context length via downsampling (e.g., identify the key image patches or frames) to decrease the context length, which may result in information loss. To circumvent this issue while keeping the remarkable effectiveness of MLLMs, we propose a novel approach using a hybrid transformer-MAMBA model to efficiently handle long contexts in multimodal applications. Our multimodal model can effectively process long context input exceeding 100k tokens, outperforming existing models across various benchmarks. Remarkably, our model enhances inference efficiency for high-resolution images and high-frame-rate videos by about 4 times compared to current models, with efficiency gains increasing as image resolution or video frames rise. Furthermore, our model is the first to be trained on low-resolution images or low-frame-rate videos while being capable of inference on high-resolution images and high-frame-rate videos, offering flexibility for inference in diverse scenarios.
BreakNet: Discontinuity-Resilient Multi-Scale Transformer Segmentation of Retinal Layers
Aug 26, 2024Visible light optical coherence tomography (vis-OCT) is gaining traction for retinal imaging due to its high resolution and functional capabilities. However, the significant absorption of hemoglobin in the visible light range leads to pronounced shadow artifacts from retinal blood vessels, posing challenges for accurate layer segmentation. In this study, we present BreakNet, a multi-scale Transformer-based segmentation model designed to address boundary discontinuities caused by these shadow artifacts. BreakNet utilizes hierarchical Transformer and convolutional blocks to extract multi-scale global and local feature maps, capturing essential contextual, textural, and edge characteristics. The model incorporates decoder blocks that expand pathwaproys to enhance the extraction of fine details and semantic information, ensuring precise segmentation. Evaluated on rodent retinal images acquired with prototype vis-OCT, BreakNet demonstrated superior performance over state-of-the-art segmentation models, such as TCCT-BP and U-Net, even when faced with limited-quality ground truth data. Our findings indicate that BreakNet has the potential to significantly improve retinal quantification and analysis.
Gaussian Time Machine: A Real-Time Rendering Methodology for Time-Variant Appearances
May 22, 2024



Recent advancements in neural rendering techniques have significantly enhanced the fidelity of 3D reconstruction. Notably, the emergence of 3D Gaussian Splatting (3DGS) has marked a significant milestone by adopting a discrete scene representation, facilitating efficient training and real-time rendering. Several studies have successfully extended the real-time rendering capability of 3DGS to dynamic scenes. However, a challenge arises when training images are captured under vastly differing weather and lighting conditions. This scenario poses a challenge for 3DGS and its variants in achieving accurate reconstructions. Although NeRF-based methods (NeRF-W, CLNeRF) have shown promise in handling such challenging conditions, their computational demands hinder real-time rendering capabilities. In this paper, we present Gaussian Time Machine (GTM) which models the time-dependent attributes of Gaussian primitives with discrete time embedding vectors decoded by a lightweight Multi-Layer-Perceptron(MLP). By adjusting the opacity of Gaussian primitives, we can reconstruct visibility changes of objects. We further propose a decomposed color model for improved geometric consistency. GTM achieved state-of-the-art rendering fidelity on 3 datasets and is 100 times faster than NeRF-based counterparts in rendering. Moreover, GTM successfully disentangles the appearance changes and renders smooth appearance interpolation.
Fully Automated OCT-based Tissue Screening System
May 15, 2024This study introduces a groundbreaking optical coherence tomography (OCT) imaging system dedicated for high-throughput screening applications using ex vivo tissue culture. Leveraging OCT's non-invasive, high-resolution capabilities, the system is equipped with a custom-designed motorized platform and tissue detection ability for automated, successive imaging across samples. Transformer-based deep learning segmentation algorithms further ensure robust, consistent, and efficient readouts meeting the standards for screening assays. Validated using retinal explant cultures from a mouse model of retinal degeneration, the system provides robust, rapid, reliable, unbiased, and comprehensive readouts of tissue response to treatments. This fully automated OCT-based system marks a significant advancement in tissue screening, promising to transform drug discovery, as well as other relevant research fields.
Sub2Full: split spectrum to boost OCT despeckling without clean data
Jan 18, 2024
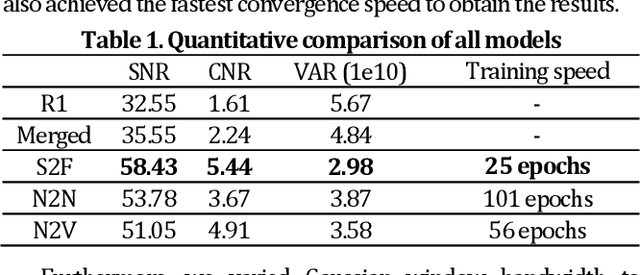

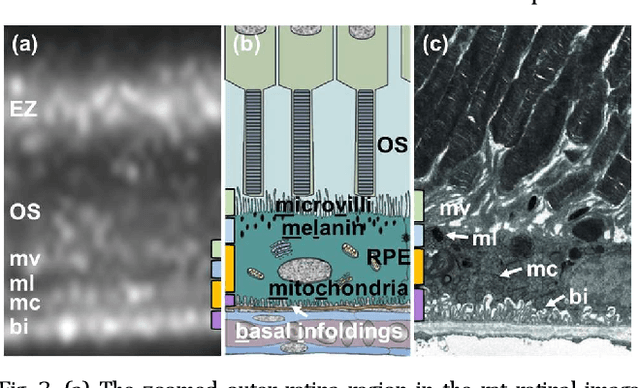
Optical coherence tomography (OCT) suffers from speckle noise, causing the deterioration of image quality, especially in high-resolution modalities like visible light OCT (vis-OCT). The potential of conventional supervised deep learning denoising methods is limited by the difficulty of obtaining clean data. Here, we proposed an innovative self-supervised strategy called Sub2Full (S2F) for OCT despeckling without clean data. This approach works by acquiring two repeated B-scans, splitting the spectrum of the first repeat as a low-resolution input, and utilizing the full spectrum of the second repeat as the high-resolution target. The proposed method was validated on vis-OCT retinal images visualizing sublaminar structures in outer retina and demonstrated superior performance over conventional Noise2Noise and Noise2Void schemes. The code is available at https://github.com/PittOCT/Sub2Full-OCT-Denoising.