 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
DOD-SA: Infrared-Visible Decoupled Object Detection with Single-Modality Annotations
Aug 14, 2025Infrared-visible object detection has shown great potential in real-world applications, enabling robust all-day perception by leveraging the complementary information of infrared and visible images. However, existing methods typically require dual-modality annotations to output detection results for both modalities during prediction, which incurs high annotation costs. To address this challenge, we propose a novel infrared-visible Decoupled Object Detection framework with Single-modality Annotations, called DOD-SA. The architecture of DOD-SA is built upon a Single- and Dual-Modality Collaborative Teacher-Student Network (CoSD-TSNet), which consists of a single-modality branch (SM-Branch) and a dual-modality decoupled branch (DMD-Branch). The teacher model generates pseudo-labels for the unlabeled modality, simultaneously supporting the training of the student model. The collaborative design enables cross-modality knowledge transfer from the labeled modality to the unlabeled modality, and facilitates effective SM-to-DMD branch supervision. To further improve the decoupling ability of the model and the pseudo-label quality, we introduce a Progressive and Self-Tuning Training Strategy (PaST) that trains the model in three stages: (1) pretraining SM-Branch, (2) guiding the learning of DMD-Branch by SM-Branch, and (3) refining DMD-Branch. In addition, we design a Pseudo Label Assigner (PLA) to align and pair labels across modalities, explicitly addressing modality misalignment during training. Extensive experiments on the DroneVehicle dataset demonstrate that our method outperforms state-of-the-art (SOTA).
SitPose: Real-Time Detection of Sitting Posture and Sedentary Behavior Using Ensemble Learning With Depth Sensor
Dec 16, 2024



Poor sitting posture can lead to various work-related musculoskeletal disorders (WMSDs). Office employees spend approximately 81.8% of their working time seated, and sedentary behavior can result in chronic diseases such as cervical spondylosis and cardiovascular diseases. To address these health concerns, we present SitPose, a sitting posture and sedentary detection system utilizing the latest Kinect depth camera. The system tracks 3D coordinates of bone joint points in real-time and calculates the angle values of related joints. We established a dataset containing six different sitting postures and one standing posture, totaling 33,409 data points, by recruiting 36 participants. We applied several state-of-the-art machine learning algorithms to the dataset and compared their performance in recognizing the sitting poses. Our results show that the ensemble learning model based on the soft voting mechanism achieves the highest F1 score of 98.1%. Finally, we deployed the SitPose system based on this ensemble model to encourage better sitting posture and to reduce sedentary habits.
Simultaneous Deep Learning of Myocardium Segmentation and T2 Quantification for Acute Myocardial Infarction MRI
May 17, 2024



In cardiac Magnetic Resonance Imaging (MRI) analysis, simultaneous myocardial segmentation and T2 quantification are crucial for assessing myocardial pathologies. Existing methods often address these tasks separately, limiting their synergistic potential. To address this, we propose SQNet, a dual-task network integrating Transformer and Convolutional Neural Network (CNN) components. SQNet features a T2-refine fusion decoder for quantitative analysis, leveraging global features from the Transformer, and a segmentation decoder with multiple local region supervision for enhanced accuracy. A tight coupling module aligns and fuses CNN and Transformer branch features, enabling SQNet to focus on myocardium regions. Evaluation on healthy controls (HC) and acute myocardial infarction patients (AMI) demonstrates superior segmentation dice scores (89.3/89.2) compared to state-of-the-art methods (87.7/87.9). T2 quantification yields strong linear correlations (Pearson coefficients: 0.84/0.93) with label values for HC/AMI, indicating accurate mapping. Radiologist evaluations confirm SQNet's superior image quality scores (4.60/4.58 for segmentation, 4.32/4.42 for T2 quantification) over state-of-the-art methods (4.50/4.44 for segmentation, 3.59/4.37 for T2 quantification). SQNet thus offers accurate simultaneous segmentation and quantification, enhancing cardiac disease diagnosis, such as AMI.
DARCS: Memory-Efficient Deep Compressed Sensing Reconstruction for Acceleration of 3D Whole-Heart Coronary MR Angiography
Feb 02, 2024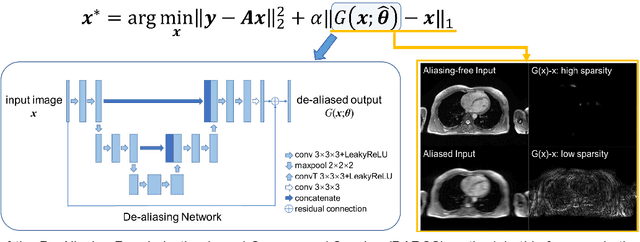
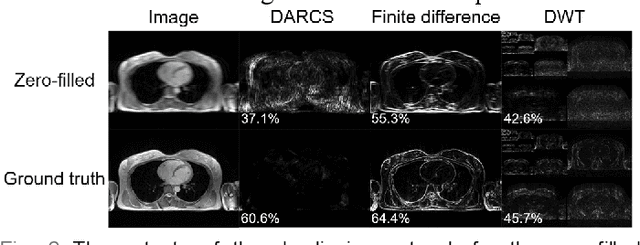
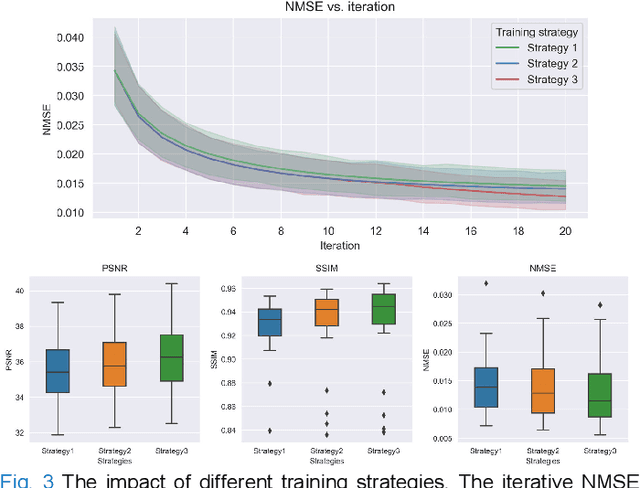
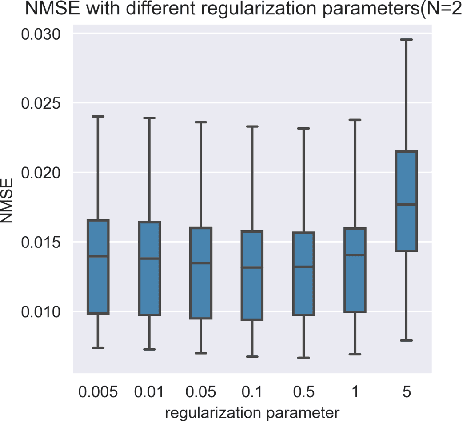
Three-dimensional coronary magnetic resonance angiography (CMRA) demands reconstruction algorithms that can significantly suppress the artifacts from a heavily undersampled acquisition. While unrolling-based deep reconstruction methods have achieved state-of-the-art performance on 2D image reconstruction, their application to 3D reconstruction is hindered by the large amount of memory needed to train an unrolled network. In this study, we propose a memory-efficient deep compressed sensing method by employing a sparsifying transform based on a pre-trained artifact estimation network. The motivation is that the artifact image estimated by a well-trained network is sparse when the input image is artifact-free, and less sparse when the input image is artifact-affected. Thus, the artifact-estimation network can be used as an inherent sparsifying transform. The proposed method, named De-Aliasing Regularization based Compressed Sensing (DARCS), was compared with a traditional compressed sensing method, de-aliasing generative adversarial network (DAGAN), model-based deep learning (MoDL), and plug-and-play for accelerations of 3D CMRA. The results demonstrate that the proposed method improved the reconstruction quality relative to the compared methods by a large margin. Furthermore, the proposed method well generalized for different undersampling rates and noise levels. The memory usage of the proposed method was only 63% of that needed by MoDL. In conclusion, the proposed method achieves improved reconstruction quality for 3D CMRA with reduced memory burden.
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images
Mar 28, 2020
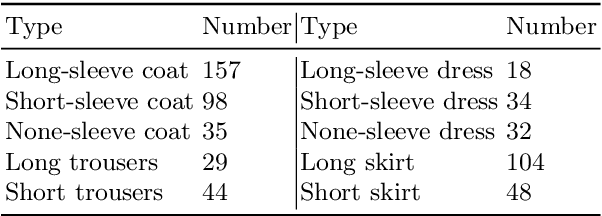

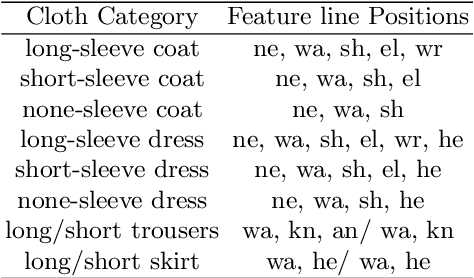
High-fidelity clothing reconstruction is the key to achieving photorealism in a wide range of applications including human digitization, virtual try-on, etc. Recent advances in learning-based approaches have accomplished unprecedented accuracy in recovering unclothed human shape and pose from single images, thanks to the availability of powerful statistical models, e.g. SMPL, learned from a large number of body scans. In contrast, modeling and recovering clothed human and 3D garments remains notoriously difficult, mostly due to the lack of large-scale clothing models available for the research community. We propose to fill this gap by introducing Deep Fashion3D, the largest collection to date of 3D garment models, with the goal of establishing a novel benchmark and dataset for the evaluation of image-based garment reconstruction systems. Deep Fashion3D contains 2078 models reconstructed from real garments, which covers 10 different categories and 563 garment instances. It provides rich annotations including 3D feature lines, 3D body pose and the corresponded multi-view real images. In addition, each garment is randomly posed to enhance the variety of real clothing deformations. To demonstrate the advantage of Deep Fashion3D, we propose a novel baseline approach for single-view garment reconstruction, which leverages the merits of both mesh and implicit representations. A novel adaptable template is proposed to enable the learning of all types of clothing in a single network. Extensive experiments have been conducted on the proposed dataset to verify its significance and usefulness. We will make Deep Fashion3D publicly available upon publication.