 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA: Expressive Virtual Avatars from Multi-view Videos
May 21, 2025



With recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.
GIGA: Generalizable Sparse Image-driven Gaussian Avatars
Apr 08, 2025Driving a high-quality and photorealistic full-body human avatar, from only a few RGB cameras, is a challenging problem that has become increasingly relevant with emerging virtual reality technologies. To democratize such technology, a promising solution may be a generalizable method that takes sparse multi-view images of an unseen person and then generates photoreal free-view renderings of such identity. However, the current state of the art is not scalable to very large datasets and, thus, lacks in diversity and photorealism. To address this problem, we propose a novel, generalizable full-body model for rendering photoreal humans in free viewpoint, as driven by sparse multi-view video. For the first time in literature, our model can scale up training to thousands of subjects while maintaining high photorealism. At the core, we introduce a MultiHeadUNet architecture, which takes sparse multi-view images in texture space as input and predicts Gaussian primitives represented as 2D texels on top of a human body mesh. Importantly, we represent sparse-view image information, body shape, and the Gaussian parameters in 2D so that we can design a deep and scalable architecture entirely based on 2D convolutions and attention mechanisms. At test time, our method synthesizes an articulated 3D Gaussian-based avatar from as few as four input views and a tracked body template for unseen identities. Our method excels over prior works by a significant margin in terms of cross-subject generalization capability as well as photorealism.
Real-time Free-view Human Rendering from Sparse-view RGB Videos using Double Unprojected Textures
Dec 17, 2024



Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to the sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or completely ignore sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address these issues, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.
TEDRA: Text-based Editing of Dynamic and Photoreal Actors
Aug 28, 2024



Over the past years, significant progress has been made in creating photorealistic and drivable 3D avatars solely from videos of real humans. However, a core remaining challenge is the fine-grained and user-friendly editing of clothing styles by means of textual descriptions. To this end, we present TEDRA, the first method allowing text-based edits of an avatar, which maintains the avatar's high fidelity, space-time coherency, as well as dynamics, and enables skeletal pose and view control. We begin by training a model to create a controllable and high-fidelity digital replica of the real actor. Next, we personalize a pretrained generative diffusion model by fine-tuning it on various frames of the real character captured from different camera angles, ensuring the digital representation faithfully captures the dynamics and movements of the real person. This two-stage process lays the foundation for our approach to dynamic human avatar editing. Utilizing this personalized diffusion model, we modify the dynamic avatar based on a provided text prompt using our Personalized Normal Aligned Score Distillation Sampling (PNA-SDS) within a model-based guidance framework. Additionally, we propose a time step annealing strategy to ensure high-quality edits. Our results demonstrate a clear improvement over prior work in functionality and visual quality.
ASH: Animatable Gaussian Splats for Efficient and Photoreal Human Rendering
Dec 10, 2023



Real-time rendering of photorealistic and controllable human avatars stands as a cornerstone in Computer Vision and Graphics. While recent advances in neural implicit rendering have unlocked unprecedented photorealism for digital avatars, real-time performance has mostly been demonstrated for static scenes only. To address this, we propose ASH, an animatable Gaussian splatting approach for photorealistic rendering of dynamic humans in real-time. We parameterize the clothed human as animatable 3D Gaussians, which can be efficiently splatted into image space to generate the final rendering. However, naively learning the Gaussian parameters in 3D space poses a severe challenge in terms of compute. Instead, we attach the Gaussians onto a deformable character model, and learn their parameters in 2D texture space, which allows leveraging efficient 2D convolutional architectures that easily scale with the required number of Gaussians. We benchmark ASH with competing methods on pose-controllable avatars, demonstrating that our method outperforms existing real-time methods by a large margin and shows comparable or even better results than offline methods.
TriHuman : A Real-time and Controllable Tri-plane Representation for Detailed Human Geometry and Appearance Synthesis
Dec 08, 2023Creating controllable, photorealistic, and geometrically detailed digital doubles of real humans solely from video data is a key challenge in Computer Graphics and Vision, especially when real-time performance is required. Recent methods attach a neural radiance field (NeRF) to an articulated structure, e.g., a body model or a skeleton, to map points into a pose canonical space while conditioning the NeRF on the skeletal pose. These approaches typically parameterize the neural field with a multi-layer perceptron (MLP) leading to a slow runtime. To address this drawback, we propose TriHuman a novel human-tailored, deformable, and efficient tri-plane representation, which achieves real-time performance, state-of-the-art pose-controllable geometry synthesis as well as photorealistic rendering quality. At the core, we non-rigidly warp global ray samples into our undeformed tri-plane texture space, which effectively addresses the problem of global points being mapped to the same tri-plane locations. We then show how such a tri-plane feature representation can be conditioned on the skeletal motion to account for dynamic appearance and geometry changes. Our results demonstrate a clear step towards higher quality in terms of geometry and appearance modeling of humans as well as runtime performance.
SketchMetaFace: A Learning-based Sketching Interface for High-fidelity 3D Character Face Modeling
Jul 04, 2023



Modeling 3D avatars benefits various application scenarios such as AR/VR, gaming, and filming. Character faces contribute significant diversity and vividity as a vital component of avatars. However, building 3D character face models usually requires a heavy workload with commercial tools, even for experienced artists. Various existing sketch-based tools fail to support amateurs in modeling diverse facial shapes and rich geometric details. In this paper, we present SketchMetaFace - a sketching system targeting amateur users to model high-fidelity 3D faces in minutes. We carefully design both the user interface and the underlying algorithm. First, curvature-aware strokes are adopted to better support the controllability of carving facial details. Second, considering the key problem of mapping a 2D sketch map to a 3D model, we develop a novel learning-based method termed "Implicit and Depth Guided Mesh Modeling" (IDGMM). It fuses the advantages of mesh, implicit, and depth representations to achieve high-quality results with high efficiency. In addition, to further support usability, we present a coarse-to-fine 2D sketching interface design and a data-driven stroke suggestion tool. User studies demonstrate the superiority of our system over existing modeling tools in terms of the ease to use and visual quality of results. Experimental analyses also show that IDGMM reaches a better trade-off between accuracy and efficiency. SketchMetaFace is available at https://zhongjinluo.github.io/SketchMetaFace/.
Registering Explicit to Implicit: Towards High-Fidelity Garment mesh Reconstruction from Single Images
Mar 28, 2022



Fueled by the power of deep learning techniques and implicit shape learning, recent advances in single-image human digitalization have reached unprecedented accuracy and could recover fine-grained surface details such as garment wrinkles. However, a common problem for the implicit-based methods is that they cannot produce separated and topology-consistent mesh for each garment piece, which is crucial for the current 3D content creation pipeline. To address this issue, we proposed a novel geometry inference framework ReEF that reconstructs topology-consistent layered garment mesh by registering the explicit garment template to the whole-body implicit fields predicted from single images. Experiments demonstrate that our method notably outperforms its counterparts on single-image layered garment reconstruction and could bring high-quality digital assets for further content creation.
SimpModeling: Sketching Implicit Field to Guide Mesh Modeling for 3D Animalmorphic Head Design
Aug 05, 2021


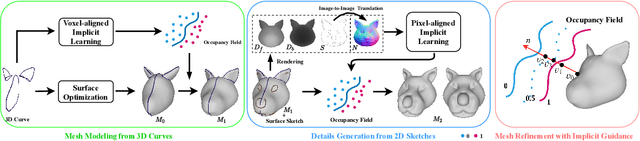
Head shapes play an important role in 3D character design. In this work, we propose SimpModeling, a novel sketch-based system for helping users, especially amateur users, easily model 3D animalmorphic heads - a prevalent kind of heads in character design. Although sketching provides an easy way to depict desired shapes, it is challenging to infer dense geometric information from sparse line drawings. Recently, deepnet-based approaches have been taken to address this challenge and try to produce rich geometric details from very few strokes. However, while such methods reduce users' workload, they would cause less controllability of target shapes. This is mainly due to the uncertainty of the neural prediction. Our system tackles this issue and provides good controllability from three aspects: 1) we separate coarse shape design and geometric detail specification into two stages and respectively provide different sketching means; 2) in coarse shape designing, sketches are used for both shape inference and geometric constraints to determine global geometry, and in geometric detail crafting, sketches are used for carving surface details; 3) in both stages, we use the advanced implicit-based shape inference methods, which have strong ability to handle the domain gap between freehand sketches and synthetic ones used for training. Experimental results confirm the effectiveness of our method and the usability of our interactive system. We also contribute to a dataset of high-quality 3D animal heads, which are manually created by artists.
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images
Mar 28, 2020
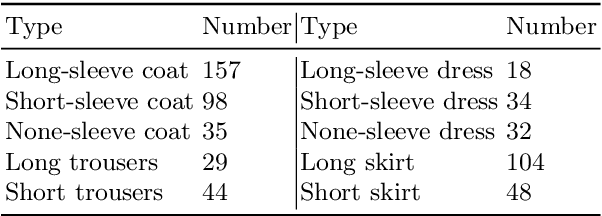

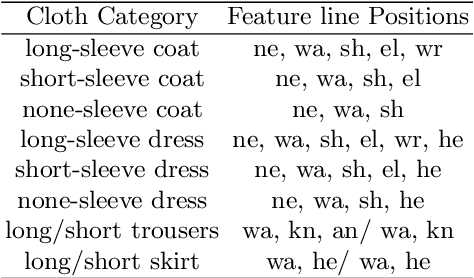
High-fidelity clothing reconstruction is the key to achieving photorealism in a wide range of applications including human digitization, virtual try-on, etc. Recent advances in learning-based approaches have accomplished unprecedented accuracy in recovering unclothed human shape and pose from single images, thanks to the availability of powerful statistical models, e.g. SMPL, learned from a large number of body scans. In contrast, modeling and recovering clothed human and 3D garments remains notoriously difficult, mostly due to the lack of large-scale clothing models available for the research community. We propose to fill this gap by introducing Deep Fashion3D, the largest collection to date of 3D garment models, with the goal of establishing a novel benchmark and dataset for the evaluation of image-based garment reconstruction systems. Deep Fashion3D contains 2078 models reconstructed from real garments, which covers 10 different categories and 563 garment instances. It provides rich annotations including 3D feature lines, 3D body pose and the corresponded multi-view real images. In addition, each garment is randomly posed to enhance the variety of real clothing deformations. To demonstrate the advantage of Deep Fashion3D, we propose a novel baseline approach for single-view garment reconstruction, which leverages the merits of both mesh and implicit representations. A novel adaptable template is proposed to enable the learning of all types of clothing in a single network. Extensive experiments have been conducted on the proposed dataset to verify its significance and usefulness. We will make Deep Fashion3D publicly available upon publication.