 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEDRA: Text-based Editing of Dynamic and Photoreal Actors
Aug 28, 2024



Over the past years, significant progress has been made in creating photorealistic and drivable 3D avatars solely from videos of real humans. However, a core remaining challenge is the fine-grained and user-friendly editing of clothing styles by means of textual descriptions. To this end, we present TEDRA, the first method allowing text-based edits of an avatar, which maintains the avatar's high fidelity, space-time coherency, as well as dynamics, and enables skeletal pose and view control. We begin by training a model to create a controllable and high-fidelity digital replica of the real actor. Next, we personalize a pretrained generative diffusion model by fine-tuning it on various frames of the real character captured from different camera angles, ensuring the digital representation faithfully captures the dynamics and movements of the real person. This two-stage process lays the foundation for our approach to dynamic human avatar editing. Utilizing this personalized diffusion model, we modify the dynamic avatar based on a provided text prompt using our Personalized Normal Aligned Score Distillation Sampling (PNA-SDS) within a model-based guidance framework. Additionally, we propose a time step annealing strategy to ensure high-quality edits. Our results demonstrate a clear improvement over prior work in functionality and visual quality.
FaceGPT: Self-supervised Learning to Chat about 3D Human Faces
Jun 11, 2024



We introduce FaceGPT, a self-supervised learning framework for Large Vision-Language Models (VLMs) to reason about 3D human faces from images and text. Typical 3D face reconstruction methods are specialized algorithms that lack semantic reasoning capabilities. FaceGPT overcomes this limitation by embedding the parameters of a 3D morphable face model (3DMM) into the token space of a VLM, enabling the generation of 3D faces from both textual and visual inputs. FaceGPT is trained in a self-supervised manner as a model-based autoencoder from in-the-wild images. In particular, the hidden state of LLM is projected into 3DMM parameters and subsequently rendered as 2D face image to guide the self-supervised learning process via image-based reconstruction. Without relying on expensive 3D annotations of human faces, FaceGPT obtains a detailed understanding about 3D human faces, while preserving the capacity to understand general user instructions. Our experiments demonstrate that FaceGPT not only achieves high-quality 3D face reconstructions but also retains the ability for general-purpose visual instruction following. Furthermore, FaceGPT learns fully self-supervised to generate 3D faces based on complex textual inputs, which opens a new direction in human face analysis.
Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models
May 27, 2024We introduce the first zero-shot approach for Video Semantic Segmentation (VSS) based on pre-trained diffusion models. A growing research direction attempts to employ diffusion models to perform downstream vision tasks by exploiting their deep understanding of image semantics. Yet, the majority of these approaches have focused on image-related tasks like semantic correspondence and segmentation, with less emphasis on video tasks such as VSS. Ideally, diffusion-based image semantic segmentation approaches can be applied to videos in a frame-by-frame manner. However, we find their performance on videos to be subpar due to the absence of any modeling of temporal information inherent in the video data. To this end, we tackle this problem and introduce a framework tailored for VSS based on pre-trained image and video diffusion models. We propose building a scene context model based on the diffusion features, where the model is autoregressively updated to adapt to scene changes. This context model predicts per-frame coarse segmentation maps that are temporally consistent. To refine these maps further, we propose a correspondence-based refinement strategy that aggregates predictions temporally, resulting in more confident predictions. Finally, we introduce a masked modulation approach to upsample the coarse maps to the full resolution at a high quality. Experiments show that our proposed approach outperforms existing zero-shot image semantic segmentation approaches significantly on various VSS benchmarks without any training or fine-tuning. Moreover, it rivals supervised VSS approaches on the VSPW dataset despite not being explicitly trained for VSS.
AvatarStudio: Text-driven Editing of 3D Dynamic Human Head Avatars
Jun 02, 2023

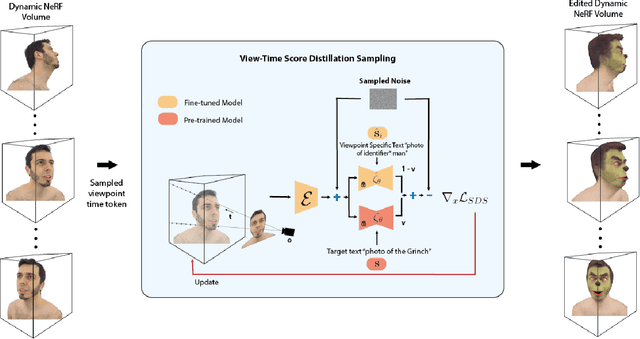
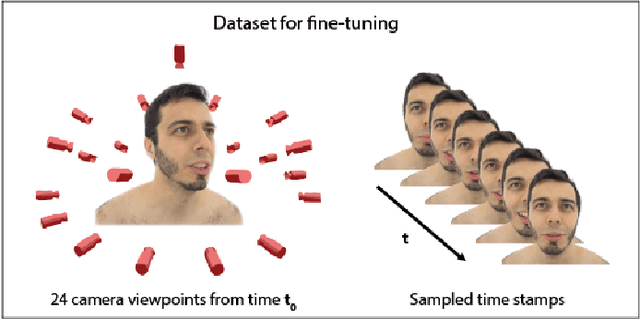
Capturing and editing full head performances enables the creation of virtual characters with various applications such as extended reality and media production. The past few years witnessed a steep rise in the photorealism of human head avatars. Such avatars can be controlled through different input data modalities, including RGB, audio, depth, IMUs and others. While these data modalities provide effective means of control, they mostly focus on editing the head movements such as the facial expressions, head pose and/or camera viewpoint. In this paper, we propose AvatarStudio, a text-based method for editing the appearance of a dynamic full head avatar. Our approach builds on existing work to capture dynamic performances of human heads using neural radiance field (NeRF) and edits this representation with a text-to-image diffusion model. Specifically, we introduce an optimization strategy for incorporating multiple keyframes representing different camera viewpoints and time stamps of a video performance into a single diffusion model. Using this personalized diffusion model, we edit the dynamic NeRF by introducing view-and-time-aware Score Distillation Sampling (VT-SDS) following a model-based guidance approach. Our method edits the full head in a canonical space, and then propagates these edits to remaining time steps via a pretrained deformation network. We evaluate our method visually and numerically via a user study, and results show that our method outperforms existing approaches. Our experiments validate the design choices of our method and highlight that our edits are genuine, personalized, as well as 3D- and time-consistent.
Egocentric Videoconferencing
Jul 07, 2021

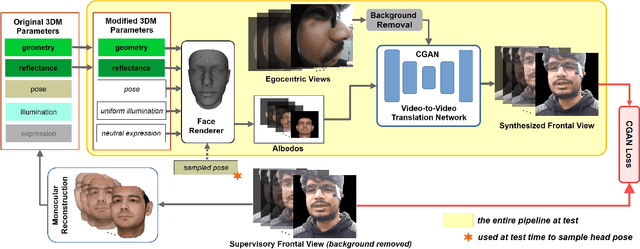

We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
* Mohamed Elgharib and Mohit Mendiratta contributed equally to this work. http://gvv.mpi-inf.mpg.de/projects/EgoChat/