 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Video World Modeling: Frontiers, Challenges, Benchmarks, and Future Trends
May 31, 2026With rapid development of large language models and diffusion-based content generation, world modeling has attracted increasing research attention, benefiting various downstream domains such as game engines, embodied AI, autonomous driving, etc. Through explicitly incorporating user actions into world state transition, recent literature empowers world modeling with interactivity in an action-conditioned video or 3D generation paradigm, further enhancing controllability over world evolutions and facilitating users to freely traverse, manipulate, navigate, and personalize the state evolution. In this paper, we aim to systematically review recent research trends, technical developments, evaluation benchmarks, and also propose future potential directions in interactive world modeling. Specifically, we first summarize recent efforts and trends in terms of application scenarios, world state evolution, and scene modality. Afterwards, we delve into three crucial technical challenges, including action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness for real-time interactivity. Furthermore, we also thoroughly compare existing benchmarks and metrics in four specific application fields: open-world exploration, game engine, autonomous driving, and robotics. Finally, we discuss several promising future directions in achieving next-generation interactive world modeling. The corresponding repository is publicly available at: https://github.com/liujiuming123/Awesome-Interactive-World-Model.
ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes
Apr 19, 2026Kinematic rigs provide a structured interface for articulating 3D meshes, but they lack an inherent representation of the plausible manifold of joint configurations for a given asset. Without such a pose space, stochastic sampling or manual manipulation of raw rig parameters often leads to semantic or geometric violations, such as anatomical hyperextension and non-physical self-intersections. We propose Video-informed Pose Spaces (ViPS), a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Unlike existing methods that rely on scarce artist-authored 4D datasets, ViPS transfers generative video priors into a universal distribution over a given rig parameterization. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without requiring manual regularizers. Our model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. Furthermore, the distilled 3D pose samples serve as precise semantic proxies for guiding video diffusion, effectively closing the loop between generative 2D priors and structured 3D kinematic control. Our evaluations show that ViPS, trained solely on video priors, matches the performance of state-of-the-art methods trained on synthetic artist-created 4D data in both plausibility and diversity. Most importantly, as a universal model, ViPS demonstrates robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies.
Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering
Jan 14, 2026Modern video generative models based on diffusion models can produce very realistic clips, but they are computationally inefficient, often requiring minutes of GPU time for just a few seconds of video. This inefficiency poses a critical barrier to deploying generative video in applications that require real-time interactions, such as embodied AI and VR/AR. This paper explores a new strategy for camera-conditioned video generation of static scenes: using diffusion-based generative models to generate a sparse set of keyframes, and then synthesizing the full video through 3D reconstruction and rendering. By lifting keyframes into a 3D representation and rendering intermediate views, our approach amortizes the generation cost across hundreds of frames while enforcing geometric consistency. We further introduce a model that predicts the optimal number of keyframes for a given camera trajectory, allowing the system to adaptively allocate computation. Our final method, SRENDER, uses very sparse keyframes for simple trajectories and denser ones for complex camera motion. This results in video generation that is more than 40 times faster than the diffusion-based baseline in generating 20 seconds of video, while maintaining high visual fidelity and temporal stability, offering a practical path toward efficient and controllable video synthesis.
VDAWorld: World Modelling via VLM-Directed Abstraction and Simulation
Dec 11, 2025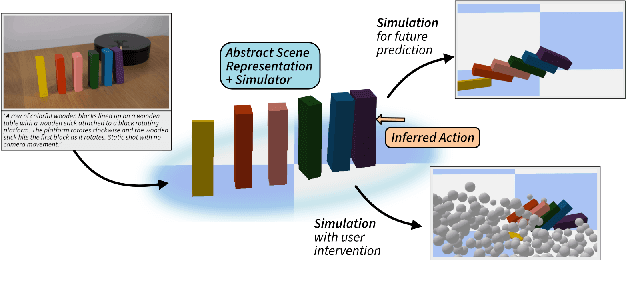
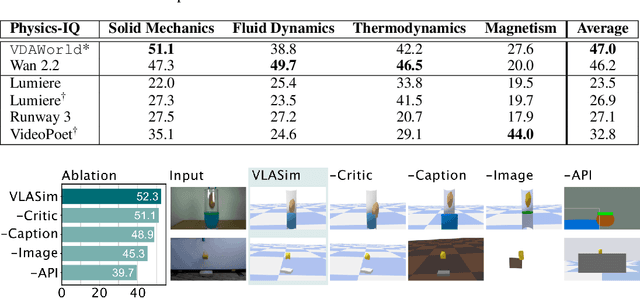
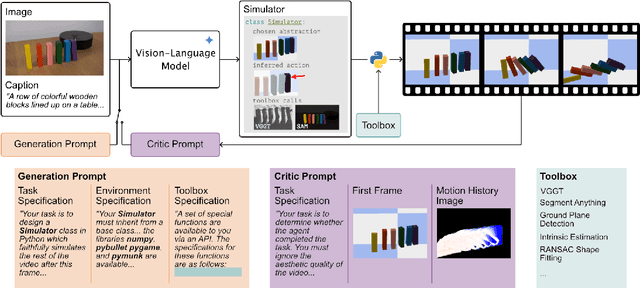

Generative video models, a leading approach to world modeling, face fundamental limitations. They often violate physical and logical rules, lack interactivity, and operate as opaque black boxes ill-suited for building structured, queryable worlds. To overcome these challenges, we propose a new paradigm focused on distilling an image caption pair into a tractable, abstract representation optimized for simulation. We introduce VDAWorld, a framework where a Vision-Language Model (VLM) acts as an intelligent agent to orchestrate this process. The VLM autonomously constructs a grounded (2D or 3D) scene representation by selecting from a suite of vision tools, and accordingly chooses a compatible physics simulator (e.g., rigid body, fluid) to act upon it. VDAWorld can then infer latent dynamics from the static scene to predict plausible future states. Our experiments show that this combination of intelligent abstraction and adaptive simulation results in a versatile world model capable of producing high quality simulations across a wide range of dynamic scenarios.
PickScan: Object discovery and reconstruction from handheld interactions
Nov 17, 2024



Reconstructing compositional 3D representations of scenes, where each object is represented with its own 3D model, is a highly desirable capability in robotics and augmented reality. However, most existing methods rely heavily on strong appearance priors for object discovery, therefore only working on those classes of objects on which the method has been trained, or do not allow for object manipulation, which is necessary to scan objects fully and to guide object discovery in challenging scenarios. We address these limitations with a novel interaction-guided and class-agnostic method based on object displacements that allows a user to move around a scene with an RGB-D camera, hold up objects, and finally outputs one 3D model per held-up object. Our main contribution to this end is a novel approach to detecting user-object interactions and extracting the masks of manipulated objects. On a custom-captured dataset, our pipeline discovers manipulated objects with 78.3% precision at 100% recall and reconstructs them with a mean chamfer distance of 0.90cm. Compared to Co-Fusion, the only comparable interaction-based and class-agnostic baseline, this corresponds to a reduction in chamfer distance of 73% while detecting 99% fewer false positives.
GAURA: Generalizable Approach for Unified Restoration and Rendering of Arbitrary Views
Jul 11, 2024Neural rendering methods can achieve near-photorealistic image synthesis of scenes from posed input images. However, when the images are imperfect, e.g., captured in very low-light conditions, state-of-the-art methods fail to reconstruct high-quality 3D scenes. Recent approaches have tried to address this limitation by modeling various degradation processes in the image formation model; however, this limits them to specific image degradations. In this paper, we propose a generalizable neural rendering method that can perform high-fidelity novel view synthesis under several degradations. Our method, GAURA, is learning-based and does not require any test-time scene-specific optimization. It is trained on a synthetic dataset that includes several degradation types. GAURA outperforms state-of-the-art methods on several benchmarks for low-light enhancement, dehazing, deraining, and on-par for motion deblurring. Further, our model can be efficiently fine-tuned to any new incoming degradation using minimal data. We thus demonstrate adaptation results on two unseen degradations, desnowing and removing defocus blur. Code and video results are available at vinayak-vg.github.io/GAURA.
FlowMap: High-Quality Camera Poses, Intrinsics, and Depth via Gradient Descent
Apr 23, 2024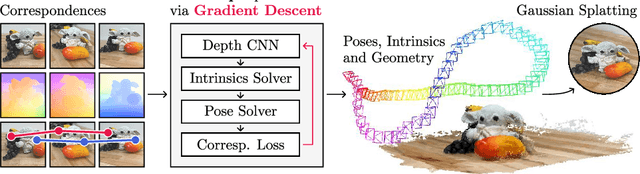


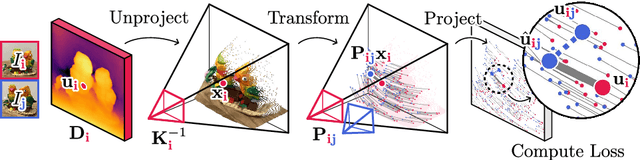
This paper introduces FlowMap, an end-to-end differentiable method that solves for precise camera poses, camera intrinsics, and per-frame dense depth of a video sequence. Our method performs per-video gradient-descent minimization of a simple least-squares objective that compares the optical flow induced by depth, intrinsics, and poses against correspondences obtained via off-the-shelf optical flow and point tracking. Alongside the use of point tracks to encourage long-term geometric consistency, we introduce differentiable re-parameterizations of depth, intrinsics, and pose that are amenable to first-order optimization. We empirically show that camera parameters and dense depth recovered by our method enable photo-realistic novel view synthesis on 360-degree trajectories using Gaussian Splatting. Our method not only far outperforms prior gradient-descent based bundle adjustment methods, but surprisingly performs on par with COLMAP, the state-of-the-art SfM method, on the downstream task of 360-degree novel view synthesis (even though our method is purely gradient-descent based, fully differentiable, and presents a complete departure from conventional SfM).
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering
Sep 30, 2023



Inverse rendering, the process of inferring scene properties from images, is a challenging inverse problem. The task is ill-posed, as many different scene configurations can give rise to the same image. Most existing solutions incorporate priors into the inverse-rendering pipeline to encourage plausible solutions, but they do not consider the inherent ambiguities and the multi-modal distribution of possible decompositions. In this work, we propose a novel scheme that integrates a denoising diffusion probabilistic model pre-trained on natural illumination maps into an optimization framework involving a differentiable path tracer. The proposed method allows sampling from combinations of illumination and spatially-varying surface materials that are, both, natural and explain the image observations. We further conduct an extensive comparative study of different priors on illumination used in previous work on inverse rendering. Our method excels in recovering materials and producing highly realistic and diverse environment map samples that faithfully explain the illumination of the input images.
Approaching human 3D shape perception with neurally mappable models
Sep 07, 2023Humans effortlessly infer the 3D shape of objects. What computations underlie this ability? Although various computational models have been proposed, none of them capture the human ability to match object shape across viewpoints. Here, we ask whether and how this gap might be closed. We begin with a relatively novel class of computational models, 3D neural fields, which encapsulate the basic principles of classic analysis-by-synthesis in a deep neural network (DNN). First, we find that a 3D Light Field Network (3D-LFN) supports 3D matching judgments well aligned to humans for within-category comparisons, adversarially-defined comparisons that accentuate the 3D failure cases of standard DNN models, and adversarially-defined comparisons for algorithmically generated shapes with no category structure. We then investigate the source of the 3D-LFN's ability to achieve human-aligned performance through a series of computational experiments. Exposure to multiple viewpoints of objects during training and a multi-view learning objective are the primary factors behind model-human alignment; even conventional DNN architectures come much closer to human behavior when trained with multi-view objectives. Finally, we find that while the models trained with multi-view learning objectives are able to partially generalize to new object categories, they fall short of human alignment. This work provides a foundation for understanding human shape inferences within neurally mappable computational architectures.
Diffusion with Forward Models: Solving Stochastic Inverse Problems Without Direct Supervision
Jun 20, 2023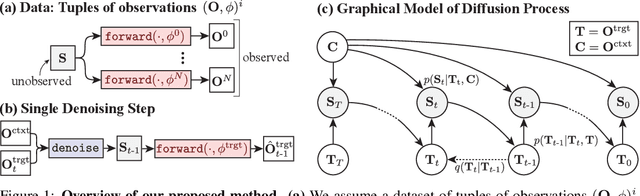


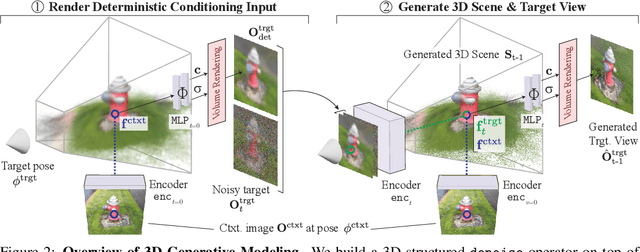
Denoising diffusion models are a powerful type of generative models used to capture complex distributions of real-world signals. However, their applicability is limited to scenarios where training samples are readily available, which is not always the case in real-world applications. For example, in inverse graphics, the goal is to generate samples from a distribution of 3D scenes that align with a given image, but ground-truth 3D scenes are unavailable and only 2D images are accessible. To address this limitation, we propose a novel class of denoising diffusion probabilistic models that learn to sample from distributions of signals that are never directly observed. Instead, these signals are measured indirectly through a known differentiable forward model, which produces partial observations of the unknown signal. Our approach involves integrating the forward model directly into the denoising process. This integration effectively connects the generative modeling of observations with the generative modeling of the underlying signals, allowing for end-to-end training of a conditional generative model over signals. During inference, our approach enables sampling from the distribution of underlying signals that are consistent with a given partial observation. We demonstrate the effectiveness of our method on three challenging computer vision tasks. For instance, in the context of inverse graphics, our model enables direct sampling from the distribution of 3D scenes that align with a single 2D input image.