 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Multiview Object Consistency in Humans and Image Models
Sep 10, 2024



We introduce a benchmark to directly evaluate the alignment between human observers and vision models on a 3D shape inference task. We leverage an experimental design from the cognitive sciences which requires zero-shot visual inferences about object shape: given a set of images, participants identify which contain the same/different objects, despite considerable viewpoint variation. We draw from a diverse range of images that include common objects (e.g., chairs) as well as abstract shapes (i.e., procedurally generated `nonsense' objects). After constructing over 2000 unique image sets, we administer these tasks to human participants, collecting 35K trials of behavioral data from over 500 participants. This includes explicit choice behaviors as well as intermediate measures, such as reaction time and gaze data. We then evaluate the performance of common vision models (e.g., DINOv2, MAE, CLIP). We find that humans outperform all models by a wide margin. Using a multi-scale evaluation approach, we identify underlying similarities and differences between models and humans: while human-model performance is correlated, humans allocate more time/processing on challenging trials. All images, data, and code can be accessed via our project page.
Approaching human 3D shape perception with neurally mappable models
Sep 07, 2023Humans effortlessly infer the 3D shape of objects. What computations underlie this ability? Although various computational models have been proposed, none of them capture the human ability to match object shape across viewpoints. Here, we ask whether and how this gap might be closed. We begin with a relatively novel class of computational models, 3D neural fields, which encapsulate the basic principles of classic analysis-by-synthesis in a deep neural network (DNN). First, we find that a 3D Light Field Network (3D-LFN) supports 3D matching judgments well aligned to humans for within-category comparisons, adversarially-defined comparisons that accentuate the 3D failure cases of standard DNN models, and adversarially-defined comparisons for algorithmically generated shapes with no category structure. We then investigate the source of the 3D-LFN's ability to achieve human-aligned performance through a series of computational experiments. Exposure to multiple viewpoints of objects during training and a multi-view learning objective are the primary factors behind model-human alignment; even conventional DNN architectures come much closer to human behavior when trained with multi-view objectives. Finally, we find that while the models trained with multi-view learning objectives are able to partially generalize to new object categories, they fall short of human alignment. This work provides a foundation for understanding human shape inferences within neurally mappable computational architectures.
Dissociating language and thought in large language models: a cognitive perspective
Jan 16, 2023

Today's large language models (LLMs) routinely generate coherent, grammatical and seemingly meaningful paragraphs of text. This achievement has led to speculation that these networks are -- or will soon become -- "thinking machines", capable of performing tasks that require abstract knowledge and reasoning. Here, we review the capabilities of LLMs by considering their performance on two different aspects of language use: 'formal linguistic competence', which includes knowledge of rules and patterns of a given language, and 'functional linguistic competence', a host of cognitive abilities required for language understanding and use in the real world. Drawing on evidence from cognitive neuroscience, we show that formal competence in humans relies on specialized language processing mechanisms, whereas functional competence recruits multiple extralinguistic capacities that comprise human thought, such as formal reasoning, world knowledge, situation modeling, and social cognition. In line with this distinction, LLMs show impressive (although imperfect) performance on tasks requiring formal linguistic competence, but fail on many tests requiring functional competence. Based on this evidence, we argue that (1) contemporary LLMs should be taken seriously as models of formal linguistic skills; (2) models that master real-life language use would need to incorporate or develop not only a core language module, but also multiple non-language-specific cognitive capacities required for modeling thought. Overall, a distinction between formal and functional linguistic competence helps clarify the discourse surrounding LLMs' potential and provides a path toward building models that understand and use language in human-like ways.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines
Jun 17, 2021
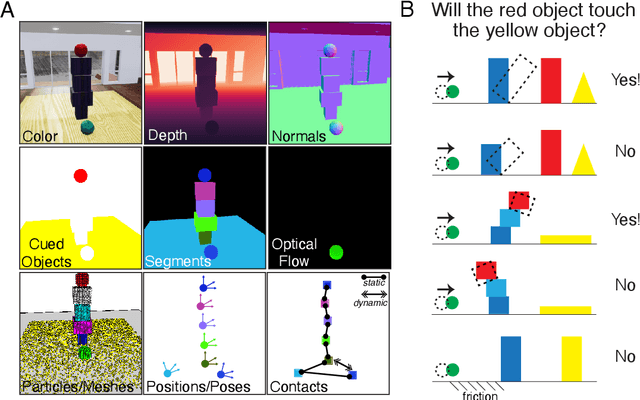
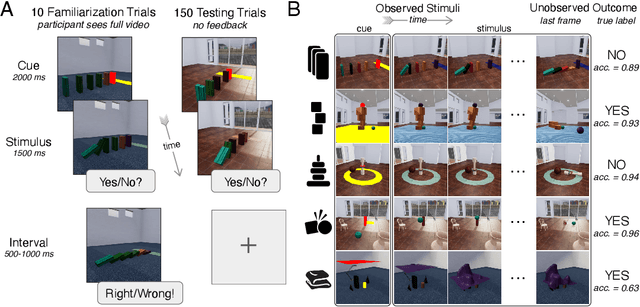
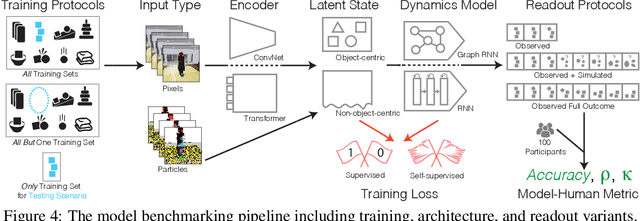
While machine learning algorithms excel at many challenging visual tasks, it is unclear that they can make predictions about commonplace real world physical events. Here, we present a visual and physical prediction benchmark that precisely measures this capability. In realistically simulating a wide variety of physical phenomena -- rigid and soft-body collisions, stable multi-object configurations, rolling and sliding, projectile motion -- our dataset presents a more comprehensive challenge than existing benchmarks. Moreover, we have collected human responses for our stimuli so that model predictions can be directly compared to human judgments. We compare an array of algorithms -- varying in their architecture, learning objective, input-output structure, and training data -- on their ability to make diverse physical predictions. We find that graph neural networks with access to the physical state best capture human behavior, whereas among models that receive only visual input, those with object-centric representations or pretraining do best but fall far short of human accuracy. This suggests that extracting physically meaningful representations of scenes is the main bottleneck to achieving human-like visual prediction. We thus demonstrate how our benchmark can identify areas for improvement and measure progress on this key aspect of physical understanding.
Measuring and modeling the perception of natural and unconstrained gaze in humans and machines
Nov 29, 2016
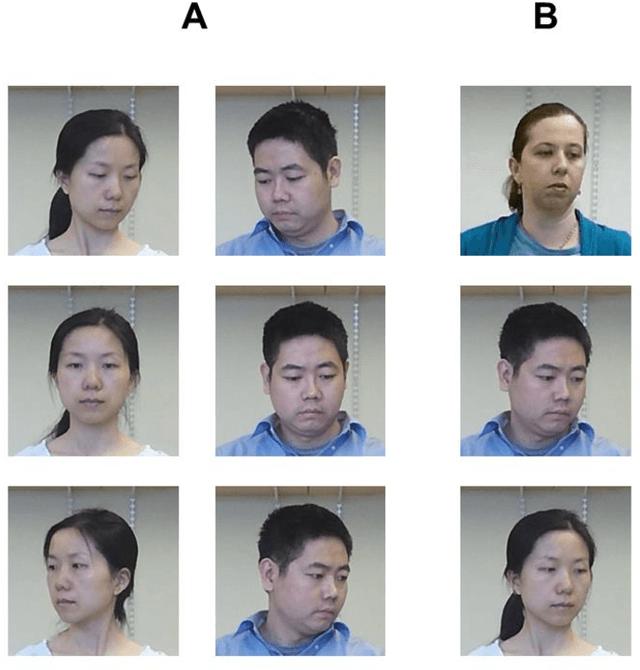
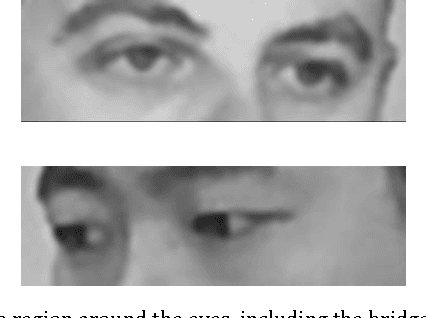

Humans are remarkably adept at interpreting the gaze direction of other individuals in their surroundings. This skill is at the core of the ability to engage in joint visual attention, which is essential for establishing social interactions. How accurate are humans in determining the gaze direction of others in lifelike scenes, when they can move their heads and eyes freely, and what are the sources of information for the underlying perceptual processes? These questions pose a challenge from both empirical and computational perspectives, due to the complexity of the visual input in real-life situations. Here we measure empirically human accuracy in perceiving the gaze direction of others in lifelike scenes, and study computationally the sources of information and representations underlying this cognitive capacity. We show that humans perform better in face-to-face conditions compared with recorded conditions, and that this advantage is not due to the availability of input dynamics. We further show that humans are still performing well when only the eyes-region is visible, rather than the whole face. We develop a computational model, which replicates the pattern of human performance, including the finding that the eyes-region contains on its own, the required information for estimating both head orientation and direction of gaze. Consistent with neurophysiological findings on task-specific face regions in the brain, the learned computational representations reproduce perceptual effects such as the Wollaston illusion, when trained to estimate direction of gaze, but not when trained to recognize objects or faces.