 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Neural Signatures of Semantic Evaluations in Depression and Suicidality
Jul 30, 2025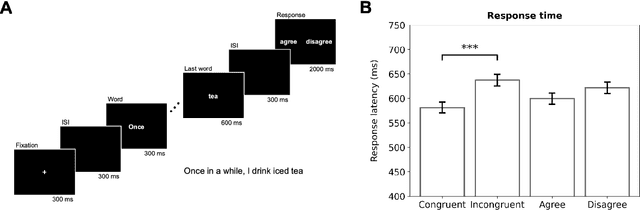
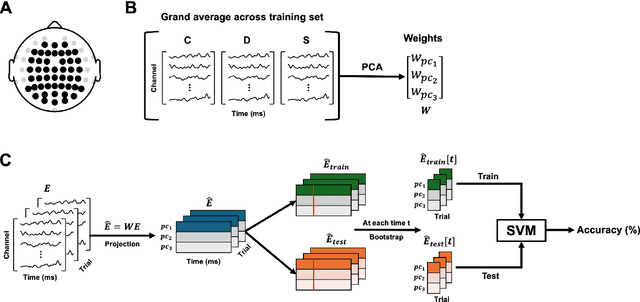
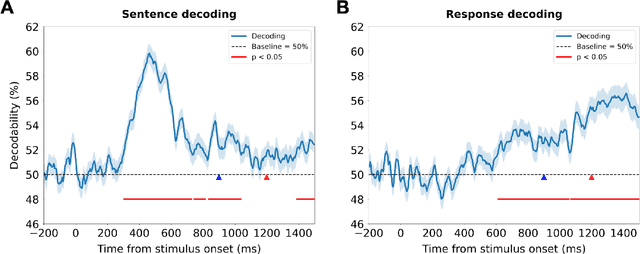
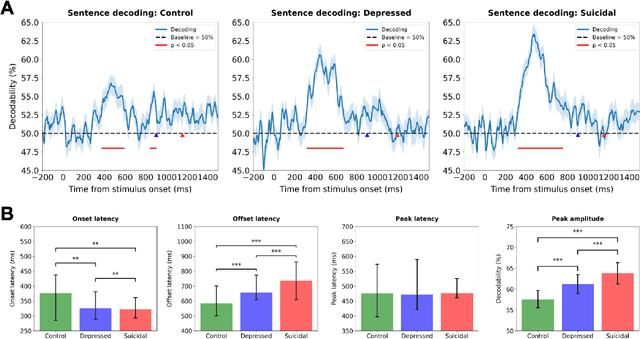
Depression and suicidality profoundly impact cognition and emotion, yet objective neurophysiological biomarkers remain elusive. We investigated the spatiotemporal neural dynamics underlying affective semantic processing in individuals with varying levels of clinical severity of depression and suicidality using multivariate decoding of electroencephalography (EEG) data. Participants (N=137) completed a sentence evaluation task involving emotionally charged self-referential statements while EEG was recorded. We identified robust, neural signatures of semantic processing, with peak decoding accuracy between 300-600 ms -- a window associated with automatic semantic evaluation and conflict monitoring. Compared to healthy controls, individuals with depression and suicidality showed earlier onset, longer duration, and greater amplitude decoding responses, along with broader cross-temporal generalization and increased activation of frontocentral and parietotemporal components. These findings suggest altered sensitivity and impaired disengagement from emotionally salient content in the clinical groups, advancing our understanding of the neurocognitive basis of mental health and providing a principled basis for developing reliable EEG-based biomarkers of depression and suicidality.
Neural Responses to Affective Sentences Reveal Signatures of Depression
Jun 06, 2025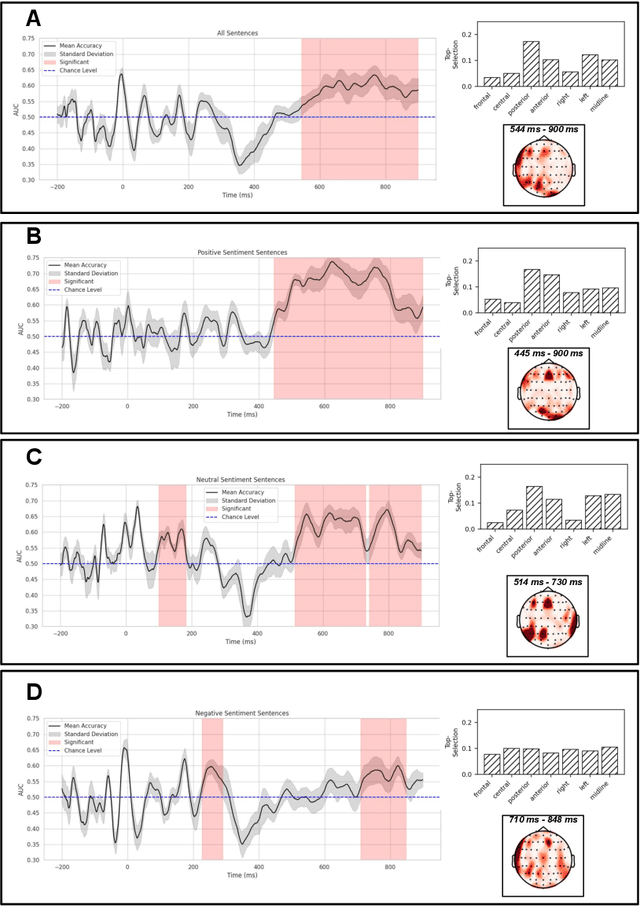
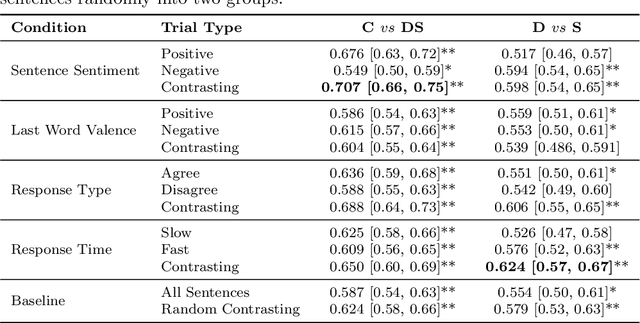
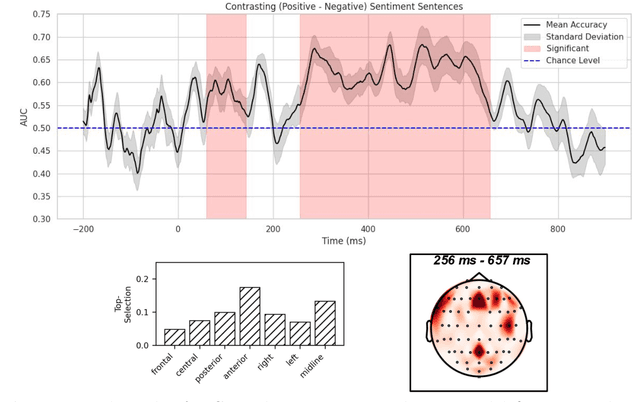

Major Depressive Disorder (MDD) is a highly prevalent mental health condition, and a deeper understanding of its neurocognitive foundations is essential for identifying how core functions such as emotional and self-referential processing are affected. We investigate how depression alters the temporal dynamics of emotional processing by measuring neural responses to self-referential affective sentences using surface electroencephalography (EEG) in healthy and depressed individuals. Our results reveal significant group-level differences in neural activity during sentence viewing, suggesting disrupted integration of emotional and self-referential information in depression. Deep learning model trained on these responses achieves an area under the receiver operating curve (AUC) of 0.707 in distinguishing healthy from depressed participants, and 0.624 in differentiating depressed subgroups with and without suicidal ideation. Spatial ablations highlight anterior electrodes associated with semantic and affective processing as key contributors. These findings suggest stable, stimulus-driven neural signatures of depression that may inform future diagnostic tools.
Deep Learning Characterizes Depression and Suicidal Ideation from Eye Movements
Apr 29, 2025Identifying physiological and behavioral markers for mental health conditions is a longstanding challenge in psychiatry. Depression and suicidal ideation, in particular, lack objective biomarkers, with screening and diagnosis primarily relying on self-reports and clinical interviews. Here, we investigate eye tracking as a potential marker modality for screening purposes. Eye movements are directly modulated by neuronal networks and have been associated with attentional and mood-related patterns; however, their predictive value for depression and suicidality remains unclear. We recorded eye-tracking sequences from 126 young adults as they read and responded to affective sentences, and subsequently developed a deep learning framework to predict their clinical status. The proposed model included separate branches for trials of positive and negative sentiment, and used 2D time-series representations to account for both intra-trial and inter-trial variations. We were able to identify depression and suicidal ideation with an area under the receiver operating curve (AUC) of 0.793 (95% CI: 0.765-0.819) against healthy controls, and suicidality specifically with 0.826 AUC (95% CI: 0.797-0.852). The model also exhibited moderate, yet significant, accuracy in differentiating depressed from suicidal participants, with 0.609 AUC (95% CI 0.571-0.646). Discriminative patterns emerge more strongly when assessing the data relative to response generation than relative to the onset time of the final word of the sentences. The most pronounced effects were observed for negative-sentiment sentences, that are congruent to depressed and suicidal participants. Our findings highlight eye tracking as an objective tool for mental health assessment and underscore the modulatory impact of emotional stimuli on cognitive processes affecting oculomotor control.
Do Large Language Models know who did what to whom?
Apr 23, 2025

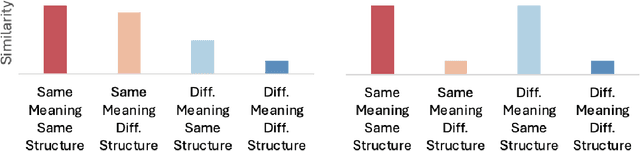

Large Language Models (LLMs) are commonly criticized for not understanding language. However, many critiques focus on cognitive abilities that, in humans, are distinct from language processing. Here, we instead study a kind of understanding tightly linked to language: inferring who did what to whom (thematic roles) in a sentence. Does the central training objective of LLMs-word prediction-result in sentence representations that capture thematic roles? In two experiments, we characterized sentence representations in four LLMs. In contrast to human similarity judgments, in LLMs the overall representational similarity of sentence pairs reflected syntactic similarity but not whether their agent and patient assignments were identical vs. reversed. Furthermore, we found little evidence that thematic role information was available in any subset of hidden units. However, some attention heads robustly captured thematic roles, independently of syntax. Therefore, LLMs can extract thematic roles but, relative to humans, this information influences their representations more weakly.
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Jun 03, 2024Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called "brain score". Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
Dissociating language and thought in large language models: a cognitive perspective
Jan 16, 2023

Today's large language models (LLMs) routinely generate coherent, grammatical and seemingly meaningful paragraphs of text. This achievement has led to speculation that these networks are -- or will soon become -- "thinking machines", capable of performing tasks that require abstract knowledge and reasoning. Here, we review the capabilities of LLMs by considering their performance on two different aspects of language use: 'formal linguistic competence', which includes knowledge of rules and patterns of a given language, and 'functional linguistic competence', a host of cognitive abilities required for language understanding and use in the real world. Drawing on evidence from cognitive neuroscience, we show that formal competence in humans relies on specialized language processing mechanisms, whereas functional competence recruits multiple extralinguistic capacities that comprise human thought, such as formal reasoning, world knowledge, situation modeling, and social cognition. In line with this distinction, LLMs show impressive (although imperfect) performance on tasks requiring formal linguistic competence, but fail on many tests requiring functional competence. Based on this evidence, we argue that (1) contemporary LLMs should be taken seriously as models of formal linguistic skills; (2) models that master real-life language use would need to incorporate or develop not only a core language module, but also multiple non-language-specific cognitive capacities required for modeling thought. Overall, a distinction between formal and functional linguistic competence helps clarify the discourse surrounding LLMs' potential and provides a path toward building models that understand and use language in human-like ways.