 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentational Curvature Modulates Behavioral Uncertainty in Large Language Models
Apr 27, 2026In autoregressive large language models (LLMs), temporal straightening offers an account of how the next-token prediction objective shapes representations. Models learn to progressively straighten the representational trajectory of input sequences across layers, potentially facilitating next-token prediction via linear extrapolation. However, a direct link between this trajectory and token-level behavior has been missing. We provide such a link by relating contextual curvature-a geometric measure of how sharply the representational trajectory bends over recent context-to next-token entropy. Across two models (GPT-2 XL and Pythia-2.8B), contextual curvature is correlated with entropy, and this relationship emerges during training. Perturbation experiments reveal selective dependence: manipulating curvature through trajectory-aligned interventions reliably modulates entropy, while geometrically misaligned perturbations have no effect. Finally, regularizing representations to be straighter during training modestly reduces token-level entropy without degrading validation loss. These results identify trajectory curvature as a task-aligned representational feature that influences behavioral uncertainty in LLMs.
Modulating Cross-Modal Convergence with Single-Stimulus, Intra-Modal Dispersion
Apr 23, 2026Neural networks exhibit a remarkable degree of representational convergence across diverse architectures, training objectives, and even data modalities. This convergence is predictive of alignment with brain representation. A recent hypothesis suggests this arises from learning the underlying structure in the environment in similar ways. However, it is unclear how individual stimuli elicit convergent representations across networks. An image can be perceived in multiple ways and expressed differently using words. Here, we introduce a methodology based on the Generalized Procrustes Algorithm to measure intra-modal representational convergence at the single-stimulus level. We applied this to vision models with distinct training objectives, selecting stimuli based on their degree of alignment (intra-modal dispersion). Crucially, we found that this intra-modal dispersion strongly modulates alignment between vision and language models (cross-modal convergence). Specifically, stimuli with low intra-modal dispersion (high agreement among vision models) elicited significantly higher cross-modal alignment than those with high dispersion, by up to a factor of two (e.g., in pairings of DINOv2 with language models). This effect was robust to stimulus selection criteria and generalized across different pairings of vision and language models. Measuring convergence at the single-stimulus level provides a path toward understanding the sources of convergence and divergence across modalities, and between neural networks and human neural representations.
The time scale of redundancy between prosody and linguistic context
Mar 14, 2025In spoken language, speakers transmit information not only using words, but also via a rich array of non-verbal signals, which include prosody -- the auditory features of speech. However, previous studies have shown that prosodic features exhibit significant redundancy with both past and future words. Here, we examine the time scale of this relationship: How many words in the past (or future) contribute to predicting prosody? We find that this scale differs for past and future words. Prosody's redundancy with past words extends across approximately 3-8 words, whereas redundancy with future words is limited to just 1-2 words. These findings indicate that the prosody-future relationship reflects local word dependencies or short-scale processes such as next word prediction, while the prosody-past relationship unfolds over a longer time scale. The latter suggests that prosody serves to emphasize earlier information that may be challenging for listeners to process given limited cognitive resources in real-time communication. Our results highlight the role of prosody in shaping efficient communication.
Elements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024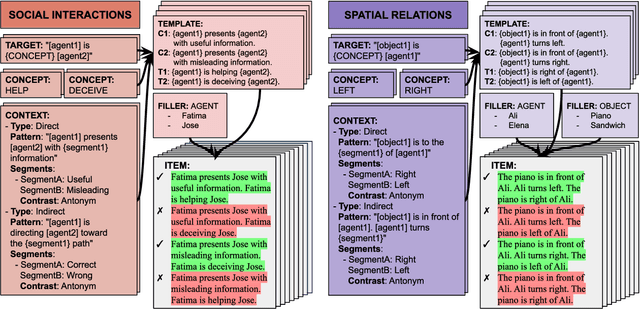
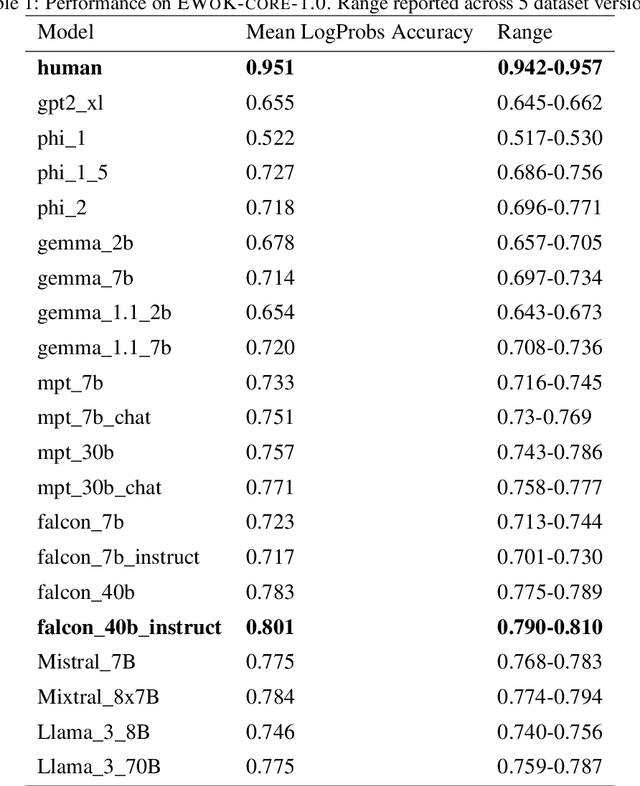
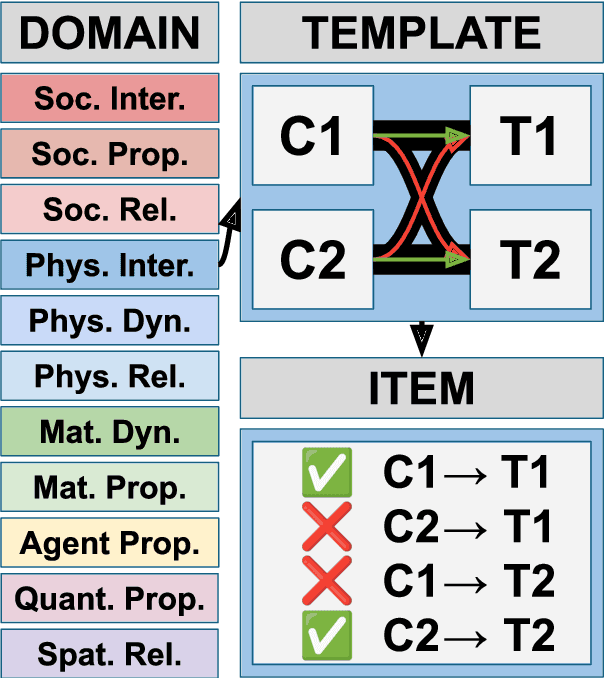
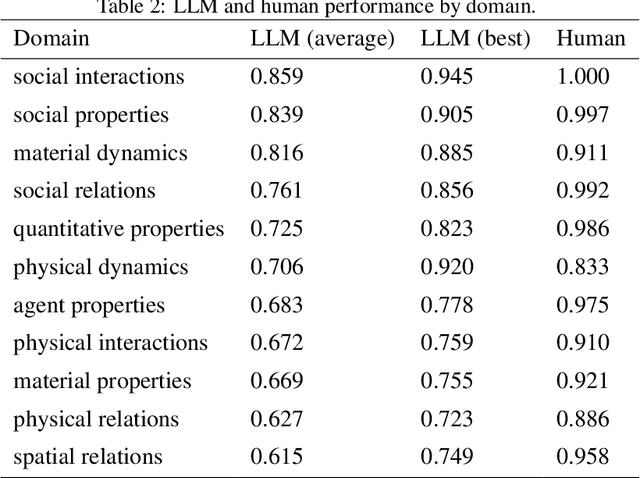
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Comparing Plausibility Estimates in Base and Instruction-Tuned Large Language Models
Mar 21, 2024Instruction-tuned LLMs can respond to explicit queries formulated as prompts, which greatly facilitates interaction with human users. However, prompt-based approaches might not always be able to tap into the wealth of implicit knowledge acquired by LLMs during pre-training. This paper presents a comprehensive study of ways to evaluate semantic plausibility in LLMs. We compare base and instruction-tuned LLM performance on an English sentence plausibility task via (a) explicit prompting and (b) implicit estimation via direct readout of the probabilities models assign to strings. Experiment 1 shows that, across model architectures and plausibility datasets, (i) log likelihood ($\textit{LL}$) scores are the most reliable indicator of sentence plausibility, with zero-shot prompting yielding inconsistent and typically poor results; (ii) $\textit{LL}$-based performance is still inferior to human performance; (iii) instruction-tuned models have worse $\textit{LL}$-based performance than base models. In Experiment 2, we show that $\textit{LL}$ scores across models are modulated by context in the expected way, showing high performance on three metrics of context-sensitive plausibility and providing a direct match to explicit human plausibility judgments. Overall, $\textit{LL}$ estimates remain a more reliable measure of plausibility in LLMs than direct prompting.
Lexicon-Level Contrastive Visual-Grounding Improves Language Modeling
Mar 21, 2024Today's most accurate language models are trained on orders of magnitude more language data than human language learners receive - but with no supervision from other sensory modalities that play a crucial role in human learning. Can we make LMs' representations and predictions more accurate (and more human-like) with more ecologically plausible supervision? This paper describes LexiContrastive Grounding (LCG), a grounded language learning procedure that leverages visual supervision to improve textual representations. LexiContrastive Grounding combines a next token prediction strategy with a contrastive visual grounding objective, focusing on early-layer representations that encode lexical information. Across multiple word-learning and sentence-understanding benchmarks, LexiContrastive Grounding not only outperforms standard language-only models in learning efficiency, but also improves upon vision-and-language learning procedures including CLIP, GIT, Flamingo, and Vokenization. Moreover, LexiContrastive Grounding improves perplexity by around 5% on multiple language modeling tasks. This work underscores the potential of incorporating visual grounding into language models, aligning more closely with the multimodal nature of human language acquisition.
Quantifying the redundancy between prosody and text
Nov 28, 2023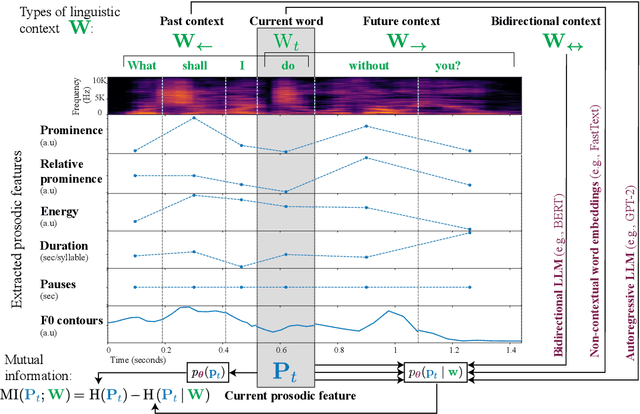
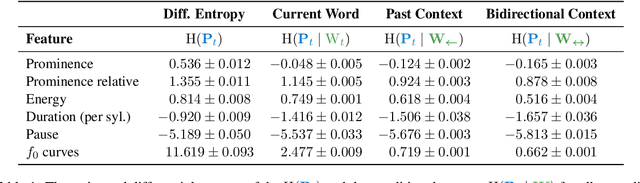
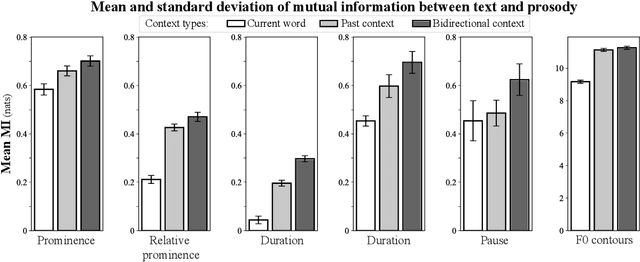
Prosody -- the suprasegmental component of speech, including pitch, loudness, and tempo -- carries critical aspects of meaning. However, the relationship between the information conveyed by prosody vs. by the words themselves remains poorly understood. We use large language models (LLMs) to estimate how much information is redundant between prosody and the words themselves. Using a large spoken corpus of English audiobooks, we extract prosodic features aligned to individual words and test how well they can be predicted from LLM embeddings, compared to non-contextual word embeddings. We find a high degree of redundancy between the information carried by the words and prosodic information across several prosodic features, including intensity, duration, pauses, and pitch contours. Furthermore, a word's prosodic information is redundant with both the word itself and the context preceding as well as following it. Still, we observe that prosodic features can not be fully predicted from text, suggesting that prosody carries information above and beyond the words. Along with this paper, we release a general-purpose data processing pipeline for quantifying the relationship between linguistic information and extra-linguistic features.
Large language models implicitly learn to straighten neural sentence trajectories to construct a predictive representation of natural language
Nov 05, 2023Predicting upcoming events is critical to our ability to interact with our environment. Transformer models, trained on next-word prediction, appear to construct representations of linguistic input that can support diverse downstream tasks. But how does a predictive objective shape such representations? Inspired by recent work in vision (Henaff et al., 2019), we test a hypothesis about predictive representations of autoregressive transformers. In particular, we test whether the neural trajectory of a sentence becomes progressively straighter as it passes through the network layers. The key insight is that straighter trajectories should facilitate prediction via linear extrapolation. We quantify straightness using a 1-dimensional curvature metric, and present four findings in support of the trajectory straightening hypothesis: i) In trained models, the curvature decreases from the early to the deeper layers of the network. ii) Models that perform better on the next-word prediction objective exhibit greater decreases in curvature, suggesting that this improved ability to straighten sentence trajectories may be the driver of better language modeling performance. iii) Given the same linguistic context, the sequences that are generated by the model have lower curvature than the actual continuations observed in a language corpus, suggesting that the model favors straighter trajectories for making predictions. iv) A consistent relationship holds between the average curvature and the average surprisal of sentences in the deep model layers, such that sentences with straighter trajectories also have lower surprisal. Importantly, untrained models do not exhibit these behaviors. In tandem, these results support the trajectory straightening hypothesis and provide a possible mechanism for how the geometry of the internal representations of autoregressive models supports next word prediction.
Visual Grounding Helps Learn Word Meanings in Low-Data Regimes
Oct 20, 2023Modern neural language models (LMs) are powerful tools for modeling human sentence production and comprehension, and their internal representations are remarkably well-aligned with representations of language in the human brain. But to achieve these results, LMs must be trained in distinctly un-human-like ways -- requiring orders of magnitude more language data than children receive during development, and without any of the accompanying grounding in perception, action, or social behavior. Do models trained more naturalistically -- with grounded supervision -- exhibit more human-like language learning? We investigate this question in the context of word learning, a key sub-task in language acquisition. We train a diverse set of LM architectures, with and without auxiliary supervision from image captioning tasks, on datasets of varying scales. We then evaluate these models on a broad set of benchmarks characterizing models' learning of syntactic categories, lexical relations, semantic features, semantic similarity, and alignment with human neural representations. We find that visual supervision can indeed improve the efficiency of word learning. However, these improvements are limited: they are present almost exclusively in the low-data regime, and sometimes canceled out by the inclusion of rich distributional signals from text. The information conveyed by text and images is not redundant -- we find that models mainly driven by visual information yield qualitatively different from those mainly driven by word co-occurrences. However, our results suggest that current multi-modal modeling approaches fail to effectively leverage visual information to build more human-like word representations from human-sized datasets.
Joint cortical registration of geometry and function using semi-supervised learning
Mar 06, 2023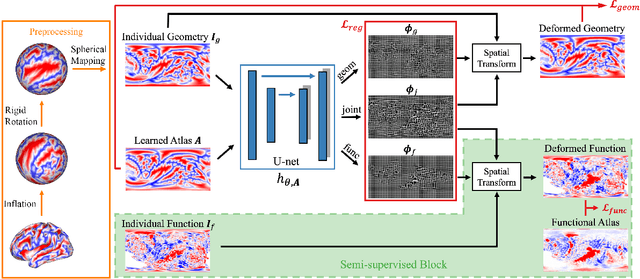


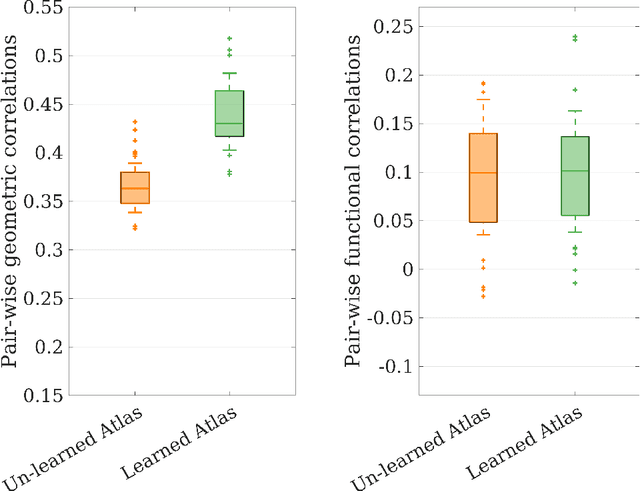
Brain surface-based image registration, an important component of brain image analysis, establishes spatial correspondence between cortical surfaces. Existing iterative and learning-based approaches focus on accurate registration of folding patterns of the cerebral cortex, and assume that geometry predicts function and thus functional areas will also be well aligned. However, structure/functional variability of anatomically corresponding areas across subjects has been widely reported. In this work, we introduce a learning-based cortical registration framework, JOSA, which jointly aligns folding patterns and functional maps while simultaneously learning an optimal atlas. We demonstrate that JOSA can substantially improve registration performance in both anatomical and functional domains over existing methods. By employing a semi-supervised training strategy, the proposed framework obviates the need for functional data during inference, enabling its use in broad neuroscientific domains where functional data may not be observed.