 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe quasi-semantic competence of LLMs: a case study on the part-whole relation
Apr 03, 2025



Understanding the extent and depth of the semantic competence of \emph{Large Language Models} (LLMs) is at the center of the current scientific agenda in Artificial Intelligence (AI) and Computational Linguistics (CL). We contribute to this endeavor by investigating their knowledge of the \emph{part-whole} relation, a.k.a. \emph{meronymy}, which plays a crucial role in lexical organization, but it is significantly understudied. We used data from ConceptNet relations \citep{speer2016conceptnet} and human-generated semantic feature norms \citep{McRae:2005} to explore the abilities of LLMs to deal with \textit{part-whole} relations. We employed several methods based on three levels of analysis: i.) \textbf{behavioral} testing via prompting, where we directly queried the models on their knowledge of meronymy, ii.) sentence \textbf{probability} scoring, where we tested models' abilities to discriminate correct (real) and incorrect (asymmetric counterfactual) \textit{part-whole} relations, and iii.) \textbf{concept representation} analysis in vector space, where we proved the linear organization of the \textit{part-whole} concept in the embedding and unembedding spaces. These analyses present a complex picture that reveals that the LLMs' knowledge of this relation is only partial. They have just a ``\emph{quasi}-semantic'' competence and still fall short of capturing deep inferential properties.
BAMBI: Developing Baby Language Models for Italian
Mar 12, 2025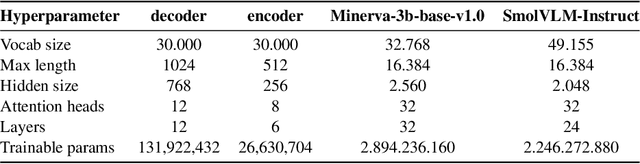



This paper presents BAMBI (BAby language Models Boostrapped for Italian), a series of Baby Language Models (BabyLMs) trained on data that mimic the linguistic input received by a five-year-old Italian-speaking child. The BAMBI models are tested using a benchmark specifically designed to evaluate language models, which takes into account the amount of training input the models received. The BAMBI models are compared against a large language model (LLM) and a multimodal language model (VLM) to study the contribution of extralinguistic information for language acquisition. The results of our evaluation align with the existing literature on English language models, confirming that while reduced training data support the development of relatively robust syntactic competence, they are insufficient for fostering semantic understanding. However, the gap between the training resources (data and computation) of the BAMBI models and the LLMs is not fully reflected in their performance: despite LLMs' massive training, their performance is not much better than that of BAMBI models. This suggests that strategies beyond scaling training resources, such as data curation, inclusion of multimodal input, and other training strategies such as curriculum learning, could play a crucial role in shaping model performance.
All-in-one: Understanding and Generation in Multimodal Reasoning with the MAIA Benchmark
Feb 24, 2025We introduce MAIA (Multimodal AI Assessment), a native-Italian benchmark designed for fine-grained investigation of the reasoning abilities of visual language models on videos. MAIA differs from other available video benchmarks for its design, its reasoning categories, the metric it uses and the language and culture of the videos. It evaluates Vision Language Models (VLMs) on two aligned tasks: a visual statement verification task, and an open-ended visual question-answering task, both on the same set of video-related questions. It considers twelve reasoning categories that aim to disentangle language and vision relations by highlight when one of two alone encodes sufficient information to solve the tasks, when they are both needed and when the full richness of the short video is essential instead of just a part of it. Thanks to its carefully taught design, it evaluates VLMs' consistency and visually grounded natural language comprehension and generation simultaneously through an aggregated metric. Last but not least, the video collection has been carefully selected to reflect the Italian culture and the language data are produced by native-speakers.
ExpliCa: Evaluating Explicit Causal Reasoning in Large Language Models
Feb 21, 2025Large Language Models (LLMs) are increasingly used in tasks requiring interpretive and inferential accuracy. In this paper, we introduce ExpliCa, a new dataset for evaluating LLMs in explicit causal reasoning. ExpliCa uniquely integrates both causal and temporal relations presented in different linguistic orders and explicitly expressed by linguistic connectives. The dataset is enriched with crowdsourced human acceptability ratings. We tested LLMs on ExpliCa through prompting and perplexity-based metrics. We assessed seven commercial and open-source LLMs, revealing that even top models struggle to reach 0.80 accuracy. Interestingly, models tend to confound temporal relations with causal ones, and their performance is also strongly influenced by the linguistic order of the events. Finally, perplexity-based scores and prompting performance are differently affected by model size.
Composing or Not Composing? Towards Distributional Construction Grammars
Dec 10, 2024The mechanisms of comprehension during language processing remains an open question. Classically, building the meaning of a linguistic utterance is said to be incremental, step-by-step, based on a compositional process. However, many different works have shown for a long time that non-compositional phenomena are also at work. It is therefore necessary to propose a framework bringing together both approaches. We present in this paper an approach based on Construction Grammars and completing this framework in order to account for these different mechanisms. We propose first a formal definition of this framework by completing the feature structure representation proposed in Sign-Based Construction Grammars. In a second step, we present a general representation of the meaning based on the interaction of constructions, frames and events. This framework opens the door to a processing mechanism for building the meaning based on the notion of activation evaluated in terms of similarity and unification. This new approach integrates features from distributional semantics into the constructionist framework, leading to what we call Distributional Construction Grammars.
Prompting Encoder Models for Zero-Shot Classification: A Cross-Domain Study in Italian
Jul 30, 2024



Addressing the challenge of limited annotated data in specialized fields and low-resource languages is crucial for the effective use of Language Models (LMs). While most Large Language Models (LLMs) are trained on general-purpose English corpora, there is a notable gap in models specifically tailored for Italian, particularly for technical and bureaucratic jargon. This paper explores the feasibility of employing smaller, domain-specific encoder LMs alongside prompting techniques to enhance performance in these specialized contexts. Our study concentrates on the Italian bureaucratic and legal language, experimenting with both general-purpose and further pre-trained encoder-only models. We evaluated the models on downstream tasks such as document classification and entity typing and conducted intrinsic evaluations using Pseudo-Log-Likelihood. The results indicate that while further pre-trained models may show diminished robustness in general knowledge, they exhibit superior adaptability for domain-specific tasks, even in a zero-shot setting. Furthermore, the application of calibration techniques and in-domain verbalizers significantly enhances the efficacy of encoder models. These domain-specialized models prove to be particularly advantageous in scenarios where in-domain resources or expertise are scarce. In conclusion, our findings offer new insights into the use of Italian models in specialized contexts, which may have a significant impact on both research and industrial applications in the digital transformation era.
Comparing Plausibility Estimates in Base and Instruction-Tuned Large Language Models
Mar 21, 2024Instruction-tuned LLMs can respond to explicit queries formulated as prompts, which greatly facilitates interaction with human users. However, prompt-based approaches might not always be able to tap into the wealth of implicit knowledge acquired by LLMs during pre-training. This paper presents a comprehensive study of ways to evaluate semantic plausibility in LLMs. We compare base and instruction-tuned LLM performance on an English sentence plausibility task via (a) explicit prompting and (b) implicit estimation via direct readout of the probabilities models assign to strings. Experiment 1 shows that, across model architectures and plausibility datasets, (i) log likelihood ($\textit{LL}$) scores are the most reliable indicator of sentence plausibility, with zero-shot prompting yielding inconsistent and typically poor results; (ii) $\textit{LL}$-based performance is still inferior to human performance; (iii) instruction-tuned models have worse $\textit{LL}$-based performance than base models. In Experiment 2, we show that $\textit{LL}$ scores across models are modulated by context in the expected way, showing high performance on three metrics of context-sensitive plausibility and providing a direct match to explicit human plausibility judgments. Overall, $\textit{LL}$ estimates remain a more reliable measure of plausibility in LLMs than direct prompting.
Agentività e telicità in GilBERTo: implicazioni cognitive
Jul 06, 2023
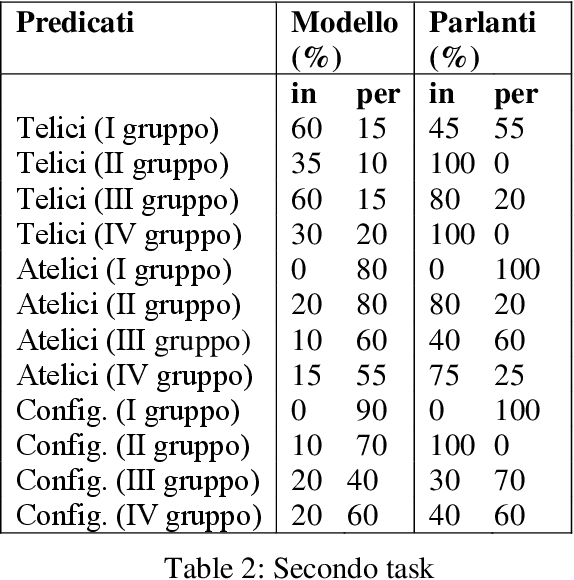

The goal of this study is to investigate whether a Transformer-based neural language model infers lexical semantics and use this information for the completion of morphosyntactic patterns. The semantic properties considered are telicity (also combined with definiteness) and agentivity. Both act at the interface between semantics and morphosyntax: they are semantically determined and syntactically encoded. The tasks were submitted to both the computational model and a group of Italian native speakers. The comparison between the two groups of data allows us to investigate to what extent neural language models capture significant aspects of human semantic competence.
Understanding Natural Language Understanding Systems. A Critical Analysis
Mar 01, 2023The development of machines that {\guillemotleft}talk like us{\guillemotright}, also known as Natural Language Understanding (NLU) systems, is the Holy Grail of Artificial Intelligence (AI), since language is the quintessence of human intelligence. The brief but intense life of NLU research in AI and Natural Language Processing (NLP) is full of ups and downs, with periods of high hopes that the Grail is finally within reach, typically followed by phases of equally deep despair and disillusion. But never has the trust that we can build {\guillemotleft}talking machines{\guillemotright} been stronger than the one engendered by the last generation of NLU systems. But is it gold all that glitters in AI? do state-of-the-art systems possess something comparable to the human knowledge of language? Are we at the dawn of a new era, in which the Grail is finally closer to us? In fact, the latest achievements of AI systems have sparkled, or better renewed, an intense scientific debate on their true language understanding capabilities. Some defend the idea that, yes, we are on the right track, despite the limits that computational models still show. Others are instead radically skeptic and even dismissal: The present limits are not just contingent and temporary problems of NLU systems, but the sign of the intrinsic inadequacy of the epistemological and technological paradigm grounding them. This paper aims at contributing to such debate by carrying out a critical analysis of the linguistic abilities of the most recent NLU systems. I contend that they incorporate important aspects of the way language is learnt and processed by humans, but at the same time they lack key interpretive and inferential skills that it is unlikely they can attain unless they are integrated with structured knowledge and the ability to exploit it for language use.
Event knowledge in large language models: the gap between the impossible and the unlikely
Dec 07, 2022



People constantly use language to learn about the world. Computational linguists have capitalized on this fact to build large language models (LLMs) that acquire co-occurrence-based knowledge from language corpora. LLMs achieve impressive performance on many tasks, but the robustness of their world knowledge has been questioned. Here, we ask: do LLMs acquire generalized knowledge about real-world events? Using curated sets of minimal sentence pairs (n=1215), we tested whether LLMs are more likely to generate plausible event descriptions compared to their implausible counterparts. We found that LLMs systematically distinguish possible and impossible events (The teacher bought the laptop vs. The laptop bought the teacher) but fall short of human performance when distinguishing likely and unlikely events (The nanny tutored the boy vs. The boy tutored the nanny). In follow-up analyses, we show that (i) LLM scores are driven by both plausibility and surface-level sentence features, (ii) LLMs generalize well across syntactic sentence variants (active vs passive) but less well across semantic sentence variants (synonymous sentences), (iii) some, but not all LLM deviations from ground-truth labels align with crowdsourced human judgments, and (iv) explicit event plausibility information emerges in middle LLM layers and remains high thereafter. Overall, our analyses reveal a gap in LLMs' event knowledge, highlighting their limitations as generalized knowledge bases. We conclude by speculating that the differential performance on impossible vs. unlikely events is not a temporary setback but an inherent property of LLMs, reflecting a fundamental difference between linguistic knowledge and world knowledge in intelligent systems.