 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Online Moderation Via LLM-Powered Counterfactual Simulations
Nov 10, 2025Online Social Networks (OSNs) widely adopt content moderation to mitigate the spread of abusive and toxic discourse. Nonetheless, the real effectiveness of moderation interventions remains unclear due to the high cost of data collection and limited experimental control. The latest developments in Natural Language Processing pave the way for a new evaluation approach. Large Language Models (LLMs) can be successfully leveraged to enhance Agent-Based Modeling and simulate human-like social behavior with unprecedented degree of believability. Yet, existing tools do not support simulation-based evaluation of moderation strategies. We fill this gap by designing a LLM-powered simulator of OSN conversations enabling a parallel, counterfactual simulation where toxic behavior is influenced by moderation interventions, keeping all else equal. We conduct extensive experiments, unveiling the psychological realism of OSN agents, the emergence of social contagion phenomena and the superior effectiveness of personalized moderation strategies.
All-in-one: Understanding and Generation in Multimodal Reasoning with the MAIA Benchmark
Feb 24, 2025We introduce MAIA (Multimodal AI Assessment), a native-Italian benchmark designed for fine-grained investigation of the reasoning abilities of visual language models on videos. MAIA differs from other available video benchmarks for its design, its reasoning categories, the metric it uses and the language and culture of the videos. It evaluates Vision Language Models (VLMs) on two aligned tasks: a visual statement verification task, and an open-ended visual question-answering task, both on the same set of video-related questions. It considers twelve reasoning categories that aim to disentangle language and vision relations by highlight when one of two alone encodes sufficient information to solve the tasks, when they are both needed and when the full richness of the short video is essential instead of just a part of it. Thanks to its carefully taught design, it evaluates VLMs' consistency and visually grounded natural language comprehension and generation simultaneously through an aggregated metric. Last but not least, the video collection has been carefully selected to reflect the Italian culture and the language data are produced by native-speakers.
ExpliCa: Evaluating Explicit Causal Reasoning in Large Language Models
Feb 21, 2025Large Language Models (LLMs) are increasingly used in tasks requiring interpretive and inferential accuracy. In this paper, we introduce ExpliCa, a new dataset for evaluating LLMs in explicit causal reasoning. ExpliCa uniquely integrates both causal and temporal relations presented in different linguistic orders and explicitly expressed by linguistic connectives. The dataset is enriched with crowdsourced human acceptability ratings. We tested LLMs on ExpliCa through prompting and perplexity-based metrics. We assessed seven commercial and open-source LLMs, revealing that even top models struggle to reach 0.80 accuracy. Interestingly, models tend to confound temporal relations with causal ones, and their performance is also strongly influenced by the linguistic order of the events. Finally, perplexity-based scores and prompting performance are differently affected by model size.
Multi-Perspective Stance Detection
Nov 13, 2024

Subjective NLP tasks usually rely on human annotations provided by multiple annotators, whose judgments may vary due to their diverse backgrounds and life experiences. Traditional methods often aggregate multiple annotations into a single ground truth, disregarding the diversity in perspectives that arises from annotator disagreement. In this preliminary study, we examine the effect of including multiple annotations on model accuracy in classification. Our methodology investigates the performance of perspective-aware classification models in stance detection task and further inspects if annotator disagreement affects the model confidence. The results show that multi-perspective approach yields better classification performance outperforming the baseline which uses the single label. This entails that designing more inclusive perspective-aware AI models is not only an essential first step in implementing responsible and ethical AI, but it can also achieve superior results than using the traditional approaches.
Prompting Encoder Models for Zero-Shot Classification: A Cross-Domain Study in Italian
Jul 30, 2024



Addressing the challenge of limited annotated data in specialized fields and low-resource languages is crucial for the effective use of Language Models (LMs). While most Large Language Models (LLMs) are trained on general-purpose English corpora, there is a notable gap in models specifically tailored for Italian, particularly for technical and bureaucratic jargon. This paper explores the feasibility of employing smaller, domain-specific encoder LMs alongside prompting techniques to enhance performance in these specialized contexts. Our study concentrates on the Italian bureaucratic and legal language, experimenting with both general-purpose and further pre-trained encoder-only models. We evaluated the models on downstream tasks such as document classification and entity typing and conducted intrinsic evaluations using Pseudo-Log-Likelihood. The results indicate that while further pre-trained models may show diminished robustness in general knowledge, they exhibit superior adaptability for domain-specific tasks, even in a zero-shot setting. Furthermore, the application of calibration techniques and in-domain verbalizers significantly enhances the efficacy of encoder models. These domain-specialized models prove to be particularly advantageous in scenarios where in-domain resources or expertise are scarce. In conclusion, our findings offer new insights into the use of Italian models in specialized contexts, which may have a significant impact on both research and industrial applications in the digital transformation era.
Continually Learn to Map Visual Concepts to Large Language Models in Resource-constrained Environments
Jul 11, 2024



Learning continually from a stream of non-i.i.d. data is an open challenge in deep learning, even more so when working in resource-constrained environments such as embedded devices. Visual models that are continually updated through supervised learning are often prone to overfitting, catastrophic forgetting, and biased representations. On the other hand, large language models contain knowledge about multiple concepts and their relations, which can foster a more robust, informed and coherent learning process. This work proposes Continual Visual Mapping (CVM), an approach that continually ground vision representations to a knowledge space extracted from a fixed Language model. Specifically, CVM continually trains a small and efficient visual model to map its representations into a conceptual space established by a fixed Large Language Model. Due to their smaller nature, CVM can be used when directly adapting large visual pre-trained models is unfeasible due to computational or data constraints. CVM overcome state-of-the-art continual learning methods on five benchmarks and offers a promising avenue for addressing generalization capabilities in continual learning, even in computationally constrained devices.
Continual Pre-Training Mitigates Forgetting in Language and Vision
May 19, 2022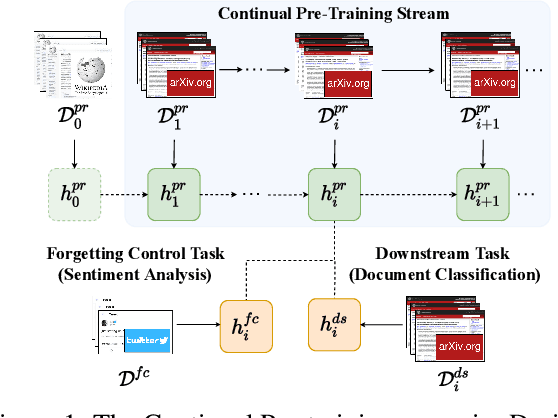
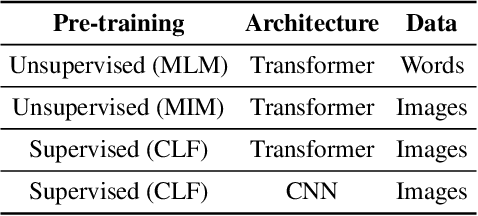
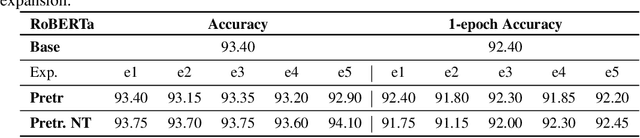
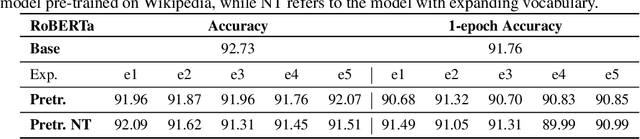
Pre-trained models are nowadays a fundamental component of machine learning research. In continual learning, they are commonly used to initialize the model before training on the stream of non-stationary data. However, pre-training is rarely applied during continual learning. We formalize and investigate the characteristics of the continual pre-training scenario in both language and vision environments, where a model is continually pre-trained on a stream of incoming data and only later fine-tuned to different downstream tasks. We show that continually pre-trained models are robust against catastrophic forgetting and we provide strong empirical evidence supporting the fact that self-supervised pre-training is more effective in retaining previous knowledge than supervised protocols. Code is provided at https://github.com/AndreaCossu/continual-pretraining-nlp-vision .