 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Continual Learning for Unified Adaptive Intelligence in Dynamic Environments
Mar 02, 2026Developing effective predictive models becomes challenging in dynamic environments that continuously produce data and constantly change. Continual Learning (CL) and Streaming Machine Learning (SML) are two research areas that tackle this arduous task. We put forward a unified setting that harnesses the benefits of both CL and SML: their ability to quickly adapt to non-stationary data streams without forgetting previous knowledge. We refer to this setting as Streaming Continual Learning (SCL). SCL does not replace either CL or SML. Instead, it extends the techniques and approaches considered by both fields. We start by briefly describing CL and SML and unifying the languages of the two frameworks. We then present the key features of SCL. We finally highlight the importance of bridging the two communities to advance the field of intelligent systems.
A Practical Guide to Streaming Continual Learning
Mar 02, 2026Continual Learning (CL) and Streaming Machine Learning (SML) study the ability of agents to learn from a stream of non-stationary data. Despite sharing some similarities, they address different and complementary challenges. While SML focuses on rapid adaptation after changes (concept drifts), CL aims to retain past knowledge when learning new tasks. After a brief introduction to CL and SML, we discuss Streaming Continual Learning (SCL), an emerging paradigm providing a unifying solution to real-world problems, which may require both SML and CL abilities. We claim that SCL can i) connect the CL and SML communities, motivating their work towards the same goal, and ii) foster the design of hybrid approaches that can quickly adapt to new information (as in SML) without forgetting previous knowledge (as in CL). We conclude the paper with a motivating example and a set of experiments, highlighting the need for SCL by showing how CL and SML alone struggle in achieving rapid adaptation and knowledge retention.
Task-Agnostic Experts Composition for Continual Learning
Jun 18, 2025Compositionality is one of the fundamental abilities of the human reasoning process, that allows to decompose a complex problem into simpler elements. Such property is crucial also for neural networks, especially when aiming for a more efficient and sustainable AI framework. We propose a compositional approach by ensembling zero-shot a set of expert models, assessing our methodology using a challenging benchmark, designed to test compositionality capabilities. We show that our Expert Composition method is able to achieve a much higher accuracy than baseline algorithms while requiring less computational resources, hence being more efficient.
Learning and Transferring Physical Models through Derivatives
May 02, 2025We propose Derivative Learning (DERL), a supervised approach that models physical systems by learning their partial derivatives. We also leverage DERL to build physical models incrementally, by designing a distillation protocol that effectively transfers knowledge from a pre-trained to a student model. We provide theoretical guarantees that our approach can learn the true physical system, being consistent with the underlying physical laws, even when using empirical derivatives. DERL outperforms state-of-the-art methods in generalizing an ODE to unseen initial conditions and a parametric PDE to unseen parameters. We finally propose a method based on DERL to transfer physical knowledge across models by extending them to new portions of the physical domain and new range of PDE parameters. We believe this is the first attempt at building physical models incrementally in multiple stages.
Replay-free Online Continual Learning with Self-Supervised MultiPatches
Feb 13, 2025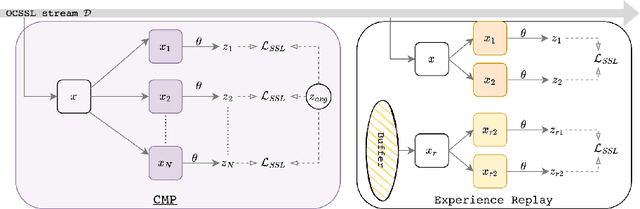
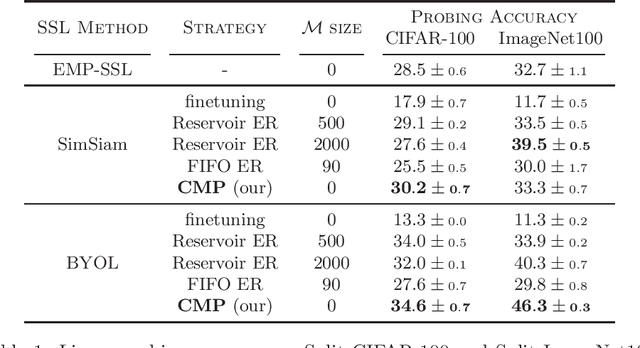
Online Continual Learning (OCL) methods train a model on a non-stationary data stream where only a few examples are available at a time, often leveraging replay strategies. However, usage of replay is sometimes forbidden, especially in applications with strict privacy regulations. Therefore, we propose Continual MultiPatches (CMP), an effective plug-in for existing OCL self-supervised learning strategies that avoids the use of replay samples. CMP generates multiple patches from a single example and projects them into a shared feature space, where patches coming from the same example are pushed together without collapsing into a single point. CMP surpasses replay and other SSL-based strategies on OCL streams, challenging the role of replay as a go-to solution for self-supervised OCL.
MultiSTOP: Solving Functional Equations with Reinforcement Learning
Apr 23, 2024We develop MultiSTOP, a Reinforcement Learning framework for solving functional equations in physics. This new methodology produces actual numerical solutions instead of bounds on them. We extend the original BootSTOP algorithm by adding multiple constraints derived from domain-specific knowledge, even in integral form, to improve the accuracy of the solution. We investigate a particular equation in a one-dimensional Conformal Field Theory.
Calibration of Continual Learning Models
Apr 12, 2024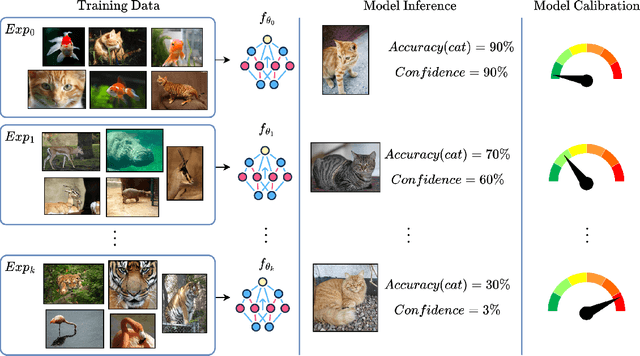
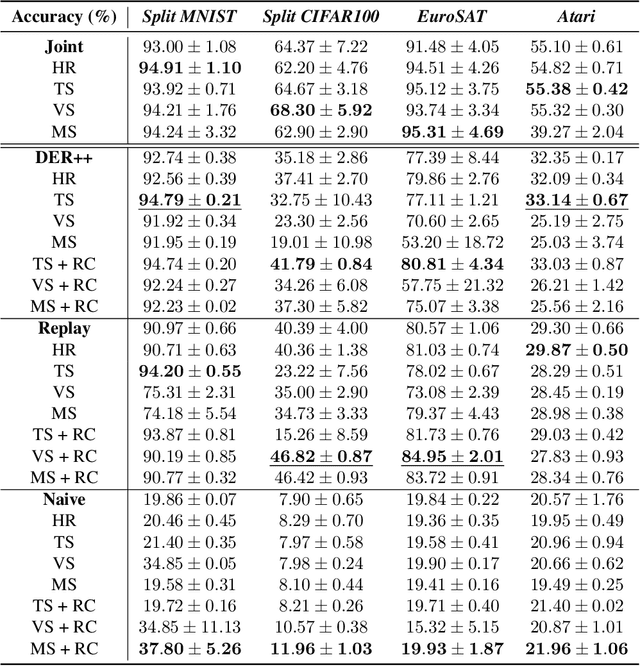
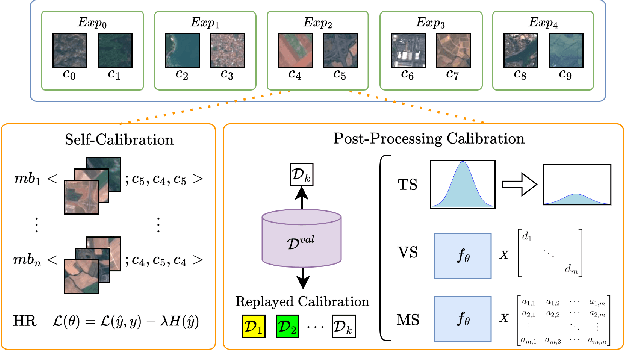
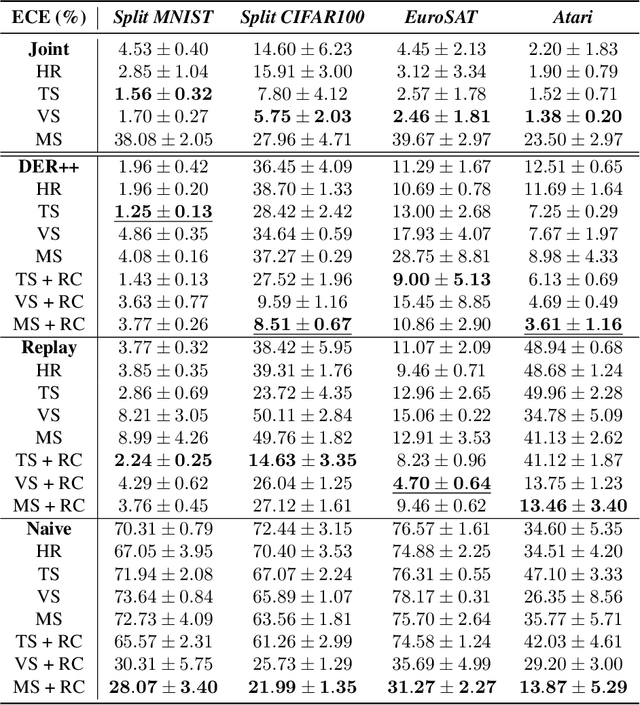
Continual Learning (CL) focuses on maximizing the predictive performance of a model across a non-stationary stream of data. Unfortunately, CL models tend to forget previous knowledge, thus often underperforming when compared with an offline model trained jointly on the entire data stream. Given that any CL model will eventually make mistakes, it is of crucial importance to build calibrated CL models: models that can reliably tell their confidence when making a prediction. Model calibration is an active research topic in machine learning, yet to be properly investigated in CL. We provide the first empirical study of the behavior of calibration approaches in CL, showing that CL strategies do not inherently learn calibrated models. To mitigate this issue, we design a continual calibration approach that improves the performance of post-processing calibration methods over a wide range of different benchmarks and CL strategies. CL does not necessarily need perfect predictive models, but rather it can benefit from reliable predictive models. We believe our study on continual calibration represents a first step towards this direction.
Continual Learning: Applications and the Road Forward
Nov 21, 2023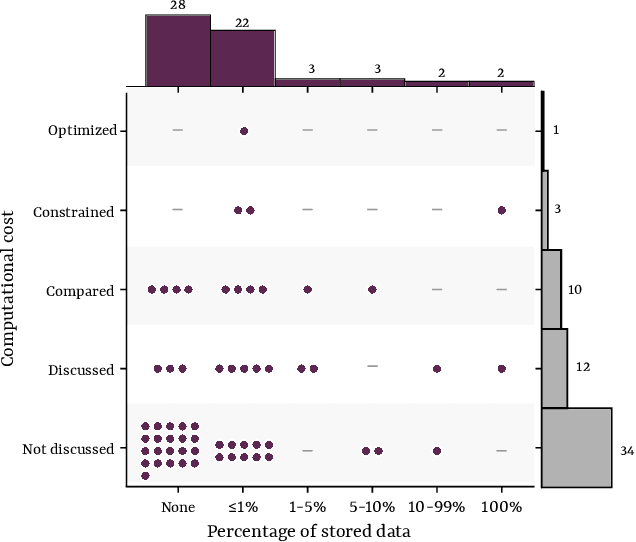
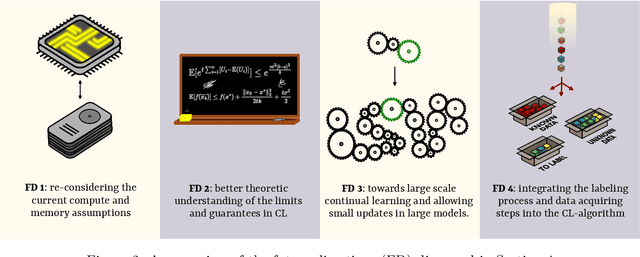
Continual learning is a sub-field of machine learning, which aims to allow machine learning models to continuously learn on new data, by accumulating knowledge without forgetting what was learned in the past. In this work, we take a step back, and ask: "Why should one care about continual learning in the first place?". We set the stage by surveying recent continual learning papers published at three major machine learning conferences, and show that memory-constrained settings dominate the field. Then, we discuss five open problems in machine learning, and even though they seem unrelated to continual learning at first sight, we show that continual learning will inevitably be part of their solution. These problems are model-editing, personalization, on-device learning, faster (re-)training and reinforcement learning. Finally, by comparing the desiderata from these unsolved problems and the current assumptions in continual learning, we highlight and discuss four future directions for continual learning research. We hope that this work offers an interesting perspective on the future of continual learning, while displaying its potential value and the paths we have to pursue in order to make it successful. This work is the result of the many discussions the authors had at the Dagstuhl seminar on Deep Continual Learning, in March 2023.
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
A Protocol for Continual Explanation of SHAP
Jun 20, 2023
Continual Learning trains models on a stream of data, with the aim of learning new information without forgetting previous knowledge. Given the dynamic nature of such environments, explaining the predictions of these models can be challenging. We study the behavior of SHAP values explanations in Continual Learning and propose an evaluation protocol to robustly assess the change of explanations in Class-Incremental scenarios. We observed that, while Replay strategies enforce the stability of SHAP values in feedforward/convolutional models, they are not able to do the same with fully-trained recurrent models. We show that alternative recurrent approaches, like randomized recurrent models, are more effective in keeping the explanations stable over time.