 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Weight Estimation Using Meta-Updates for Online Continual Learning
Jan 29, 2024The loss function plays an important role in optimizing the performance of a learning system. A crucial aspect of the loss function is the assignment of sample weights within a mini-batch during loss computation. In the context of continual learning (CL), most existing strategies uniformly treat samples when calculating the loss value, thereby assigning equal weights to each sample. While this approach can be effective in certain standard benchmarks, its optimal effectiveness, particularly in more complex scenarios, remains underexplored. This is particularly pertinent in training "in the wild," such as with self-training, where labeling is automated using a reference model. This paper introduces the Online Meta-learning for Sample Importance (OMSI) strategy that approximates sample weights for a mini-batch in an online CL stream using an inner- and meta-update mechanism. This is done by first estimating sample weight parameters for each sample in the mini-batch, then, updating the model with the adapted sample weights. We evaluate OMSI in two distinct experimental settings. First, we show that OMSI enhances both learning and retained accuracy in a controlled noisy-labeled data stream. Then, we test the strategy in three standard benchmarks and compare it with other popular replay-based strategies. This research aims to foster the ongoing exploration in the area of self-adaptive CL.
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
Partial Hypernetworks for Continual Learning
Jun 19, 2023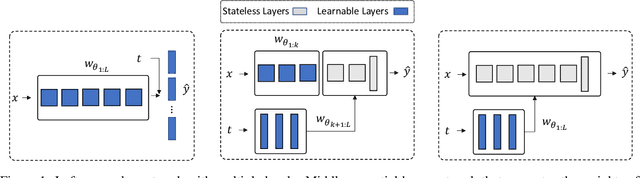
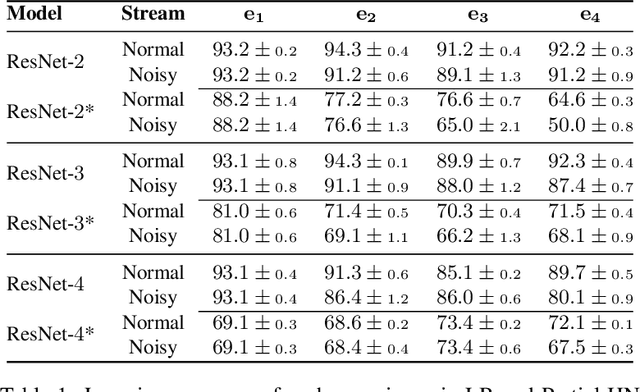
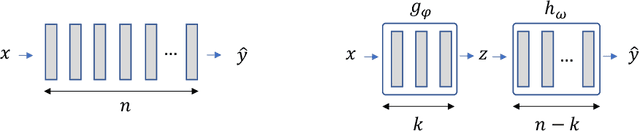

Hypernetworks mitigate forgetting in continual learning (CL) by generating task-dependent weights and penalizing weight changes at a meta-model level. Unfortunately, generating all weights is not only computationally expensive for larger architectures, but also, it is not well understood whether generating all model weights is necessary. Inspired by latent replay methods in CL, we propose partial weight generation for the final layers of a model using hypernetworks while freezing the initial layers. With this objective, we first answer the question of how many layers can be frozen without compromising the final performance. Through several experiments, we empirically show that the number of layers that can be frozen is proportional to the distributional similarity in the CL stream. Then, to demonstrate the effectiveness of hypernetworks, we show that noisy streams can significantly impact the performance of latent replay methods, leading to increased forgetting when features from noisy experiences are replayed with old samples. In contrast, partial hypernetworks are more robust to noise by maintaining accuracy on previous experiences. Finally, we conduct experiments on the split CIFAR-100 and TinyImagenet benchmarks and compare different versions of partial hypernetworks to latent replay methods. We conclude that partial weight generation using hypernetworks is a promising solution to the problem of forgetting in neural networks. It can provide an effective balance between computation and final test accuracy in CL streams.
Avalanche: A PyTorch Library for Deep Continual Learning
Feb 02, 2023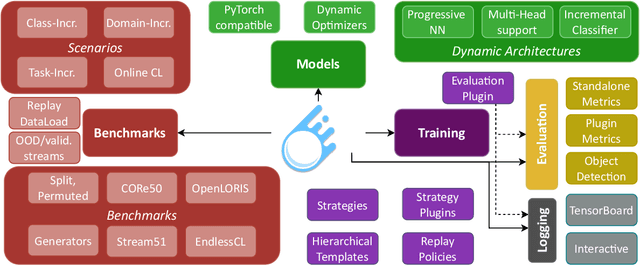
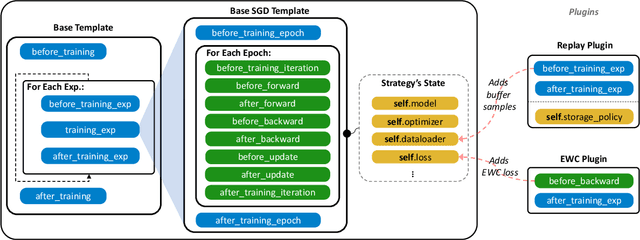
Continual learning is the problem of learning from a nonstationary stream of data, a fundamental issue for sustainable and efficient training of deep neural networks over time. Unfortunately, deep learning libraries only provide primitives for offline training, assuming that model's architecture and data are fixed. Avalanche is an open source library maintained by the ContinualAI non-profit organization that extends PyTorch by providing first-class support for dynamic architectures, streams of datasets, and incremental training and evaluation methods. Avalanche provides a large set of predefined benchmarks and training algorithms and it is easy to extend and modular while supporting a wide range of continual learning scenarios. Documentation is available at \url{https://avalanche.continualai.org}.
Class-Incremental Learning with Repetition
Jan 26, 2023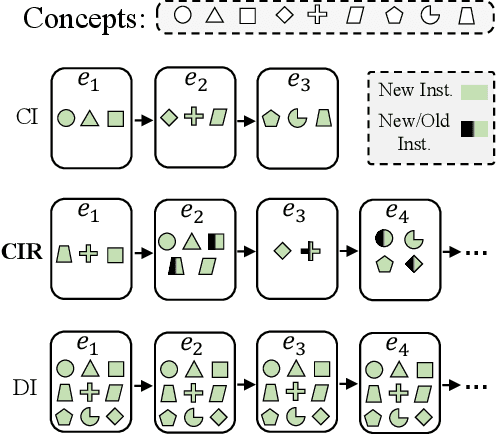

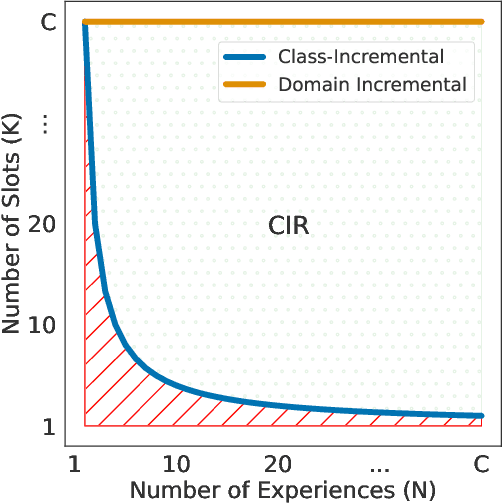
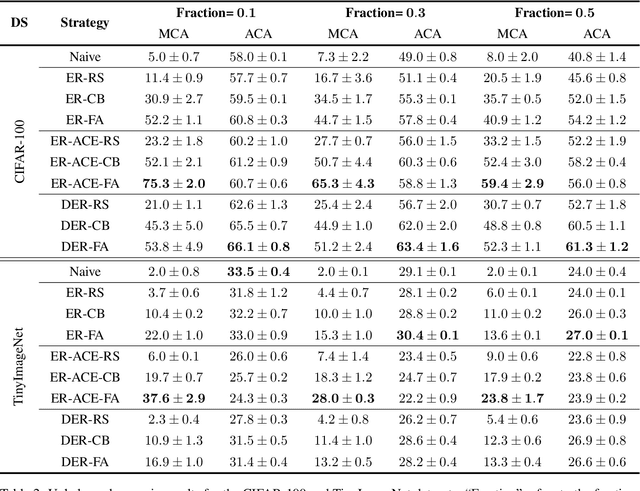
Real-world data streams naturally include the repetition of previous concepts. From a Continual Learning (CL) perspective, repetition is a property of the environment and, unlike replay, cannot be controlled by the user. Nowadays, Class-Incremental scenarios represent the leading test-bed for assessing and comparing CL strategies. This family of scenarios is very easy to use, but it never allows revisiting previously seen classes, thus completely disregarding the role of repetition. We focus on the family of Class-Incremental with Repetition (CIR) scenarios, where repetition is embedded in the definition of the stream. We propose two stochastic scenario generators that produce a wide range of CIR scenarios starting from a single dataset and a few control parameters. We conduct the first comprehensive evaluation of repetition in CL by studying the behavior of existing CL strategies under different CIR scenarios. We then present a novel replay strategy that exploits repetition and counteracts the natural imbalance present in the stream. On both CIFAR100 and TinyImageNet, our strategy outperforms other replay approaches, which are not designed for environments with repetition.
Federated Continual Learning to Detect Accounting Anomalies in Financial Auditing
Oct 26, 2022



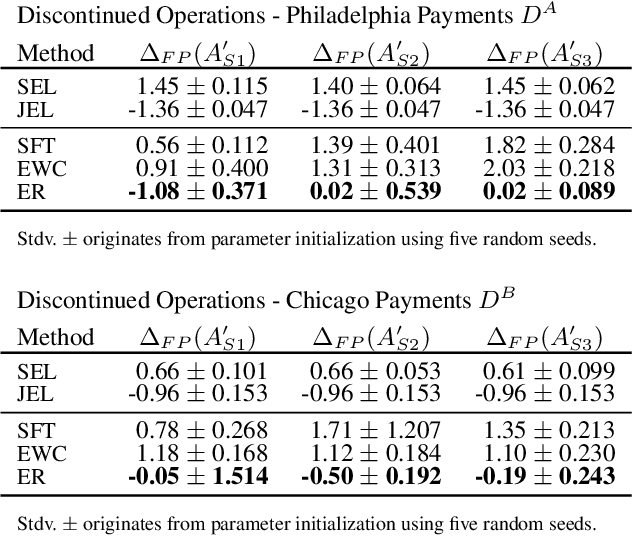
The International Standards on Auditing require auditors to collect reasonable assurance that financial statements are free of material misstatement. At the same time, a central objective of Continuous Assurance is the real-time assessment of digital accounting journal entries. Recently, driven by the advances in artificial intelligence, Deep Learning techniques have emerged in financial auditing to examine vast quantities of accounting data. However, learning highly adaptive audit models in decentralised and dynamic settings remains challenging. It requires the study of data distribution shifts over multiple clients and time periods. In this work, we propose a Federated Continual Learning framework enabling auditors to learn audit models from decentral clients continuously. We evaluate the framework's ability to detect accounting anomalies in common scenarios of organizational activity. Our empirical results, using real-world datasets and combined federated continual learning strategies, demonstrate the learned model's ability to detect anomalies in audit settings of data distribution shifts.
Generative Data Augmentation Guided by Triplet Loss for Speech Emotion Recognition
Aug 09, 2022
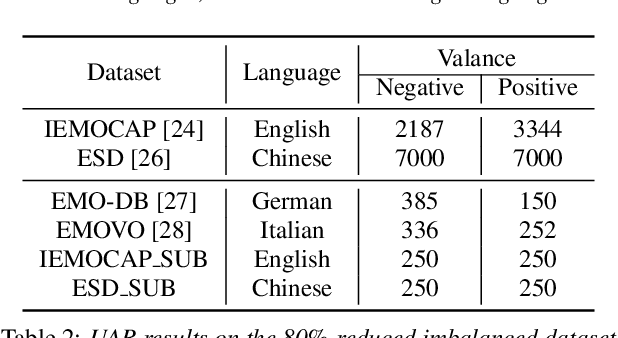
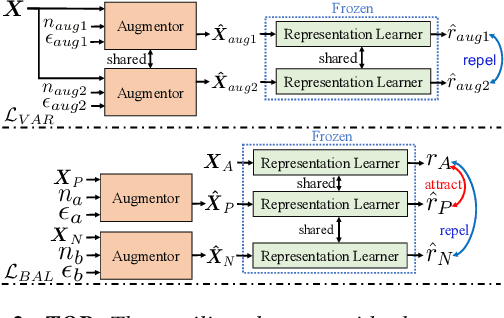
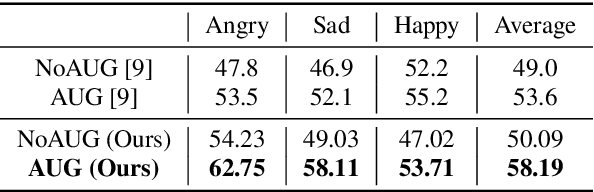
Speech Emotion Recognition (SER) is crucial for human-computer interaction but still remains a challenging problem because of two major obstacles: data scarcity and imbalance. Many datasets for SER are substantially imbalanced, where data utterances of one class (most often Neutral) are much more frequent than those of other classes. Furthermore, only a few data resources are available for many existing spoken languages. To address these problems, we exploit a GAN-based augmentation model guided by a triplet network, to improve SER performance given imbalanced and insufficient training data. We conduct experiments and demonstrate: 1) With a highly imbalanced dataset, our augmentation strategy significantly improves the SER performance (+8% recall score compared with the baseline). 2) Moreover, in a cross-lingual benchmark, where we train a model with enough source language utterances but very few target language utterances (around 50 in our experiments), our augmentation strategy brings benefits for the SER performance of all three target languages.
Continual Learning for Unsupervised Anomaly Detection in Continuous Auditing of Financial Accounting Data
Dec 25, 2021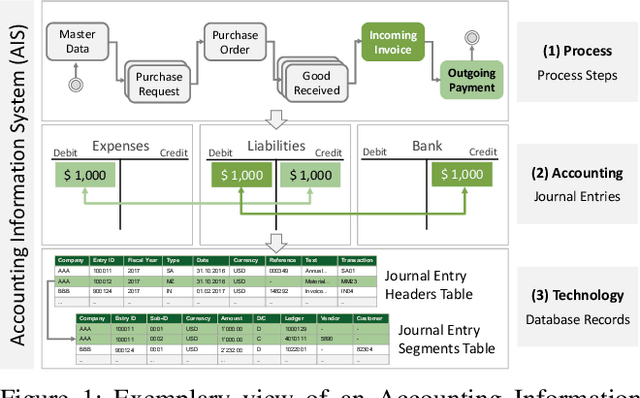

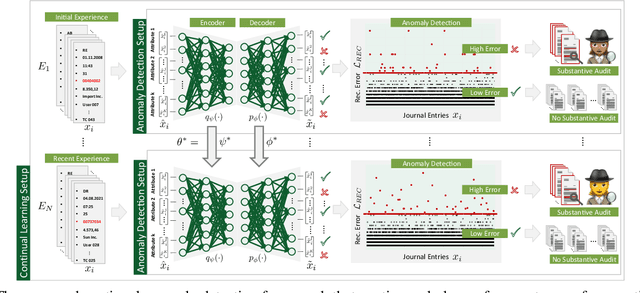
International audit standards require the direct assessment of a financial statement's underlying accounting journal entries. Driven by advances in artificial intelligence, deep-learning inspired audit techniques emerged to examine vast quantities of journal entry data. However, in regular audits, most of the proposed methods are applied to learn from a comparably stationary journal entry population, e.g., of a financial quarter or year. Ignoring situations where audit relevant distribution changes are not evident in the training data or become incrementally available over time. In contrast, in continuous auditing, deep-learning models are continually trained on a stream of recorded journal entries, e.g., of the last hour. Resulting in situations where previous knowledge interferes with new information and will be entirely overwritten. This work proposes a continual anomaly detection framework to overcome both challenges and designed to learn from a stream of journal entry data experiences. The framework is evaluated based on deliberately designed audit scenarios and two real-world datasets. Our experimental results provide initial evidence that such a learning scheme offers the ability to reduce false-positive alerts and false-negative decisions.
Continual Speaker Adaptation for Text-to-Speech Synthesis
Mar 26, 2021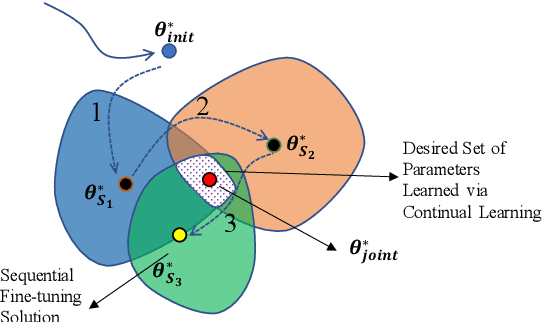

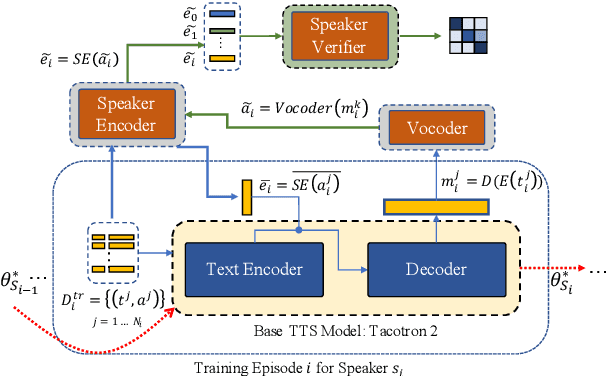
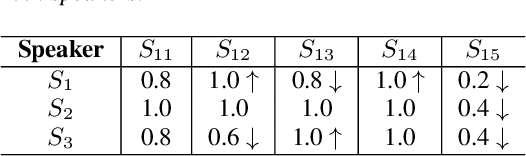
Training a multi-speaker Text-to-Speech (TTS) model from scratch is computationally expensive and adding new speakers to the dataset requires the model to be re-trained. The naive solution of sequential fine-tuning of a model for new speakers can cause the model to have poor performance on older speakers. This phenomenon is known as catastrophic forgetting. In this paper, we look at TTS modeling from a continual learning perspective where the goal is to add new speakers without forgetting previous speakers. Therefore, we first propose an experimental setup and show that serial fine-tuning for new speakers can result in the forgetting of the previous speakers. Then we exploit two well-known techniques for continual learning namely experience replay and weight regularization and we reveal how one can mitigate the effect of degradation in speech synthesis diversity in sequential training of new speakers using these methods. Finally, we present a simple extension to improve the results in extreme setups.
Using IPA-Based Tacotron for Data Efficient Cross-Lingual Speaker Adaptation and Pronunciation Enhancement
Nov 12, 2020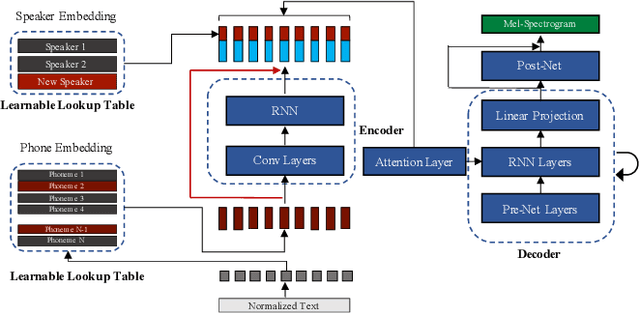
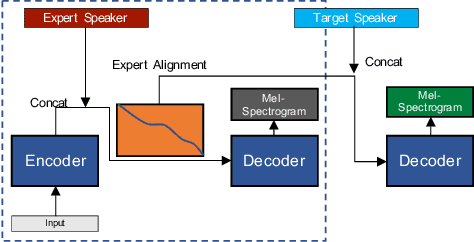
Recent neural Text-to-Speech (TTS) models have been shown to perform very well when enough data is available. However, fine-tuning them towards a new speaker or a new language is not as straight-forward in a low-resource setup. In this paper, we show that by applying minor changes to a Tacotron model, one can transfer an existing TTS model for a new speaker with the same or a different language using only 20 minutes of data. For this purpose, we first introduce a baseline multi-lingual Tacotron with language-agnostic input, then show how transfer learning is done for different scenarios of speaker adaptation without exploiting any pre-trained speaker encoder or code-switching technique. We evaluate the transferred model in both subjective and objective ways.