 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Latent Rehearsal Decay in Online Continual SSL with SOLAR
Apr 12, 2026This paper explores Online Continual Self-Supervised Learning (OCSSL), a scenario in which models learn from continuous streams of unlabeled, non-stationary data, where methods typically employ replay and fast convergence is a central desideratum. We find that OCSSL requires particular attention to the stability-plasticity trade-off: stable methods (e.g. replay with Reservoir sampling) are able to converge faster compared to plastic ones (e.g. FIFO buffer), but incur in performance drops under certain conditions. We explain this collapse phenomenon with the Latent Rehearsal Decay hypothesis, which attributes it to latent space degradation under excessive stability of replay. We introduce two metrics (Overlap and Deviation) that diagnose latent degradation and correlate with accuracy declines. Building on these insights, we propose SOLAR, which leverages efficient online proxies of Deviation to guide buffer management and incorporates an explicit Overlap loss, allowing SOLAR to adaptively managing plasticity. Experiments demonstrate that SOLAR achieves state-of-the-art performance on OCSSL vision benchmarks, with both high convergence speed and final performance.
Not All Layers Are Created Equal: Adaptive LoRA Ranks for Personalized Image Generation
Mar 23, 2026Low Rank Adaptation (LoRA) is the de facto fine-tuning strategy to generate personalized images from pre-trained diffusion models. Choosing a good rank is extremely critical, since it trades off performance and memory consumption, but today the decision is often left to the community's consensus, regardless of the personalized subject's complexity. The reason is evident: the cost of selecting a good rank for each LoRA component is combinatorial, so we opt for practical shortcuts such as fixing the same rank for all components. In this paper, we take a first step to overcome this challenge. Inspired by variational methods that learn an adaptive width of neural networks, we let the ranks of each layer freely adapt during fine-tuning on a subject. We achieve it by imposing an ordering of importance on the rank's positions, effectively encouraging the creation of higher ranks when strictly needed. Qualitatively and quantitatively, our approach, LoRA$^2$, achieves a competitive trade-off between DINO, CLIP-I, and CLIP-T across 29 subjects while requiring much less memory and lower rank than high rank LoRA versions. Code: https://github.com/donaldssh/NotAllLayersAreCreatedEqual.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
Online Continual Learning for Time Series: a Natural Score-driven Approach
Jan 19, 2026Online continual learning (OCL) methods adapt to changing environments without forgetting past knowledge. Similarly, online time series forecasting (OTSF) is a real-world problem where data evolve in time and success depends on both rapid adaptation and long-term memory. Indeed, time-varying and regime-switching forecasting models have been extensively studied, offering a strong justification for the use of OCL in these settings. Building on recent work that applies OCL to OTSF, this paper aims to strengthen the theoretical and practical connections between time series methods and OCL. First, we reframe neural network optimization as a parameter filtering problem, showing that natural gradient descent is a score-driven method and proving its information-theoretic optimality. Then, we show that using a Student's t likelihood in addition to natural gradient induces a bounded update, which improves robustness to outliers. Finally, we introduce Natural Score-driven Replay (NatSR), which combines our robust optimizer with a replay buffer and a dynamic scale heuristic that improves fast adaptation at regime drifts. Empirical results demonstrate that NatSR achieves stronger forecasting performance than more complex state-of-the-art methods.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025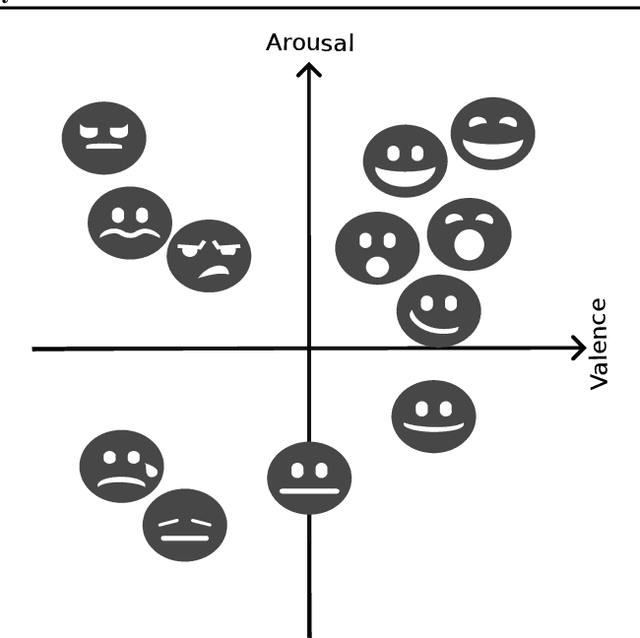


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Replay-free Online Continual Learning with Self-Supervised MultiPatches
Feb 13, 2025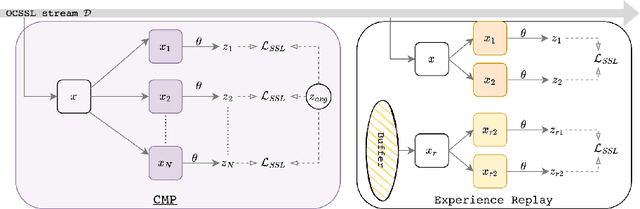
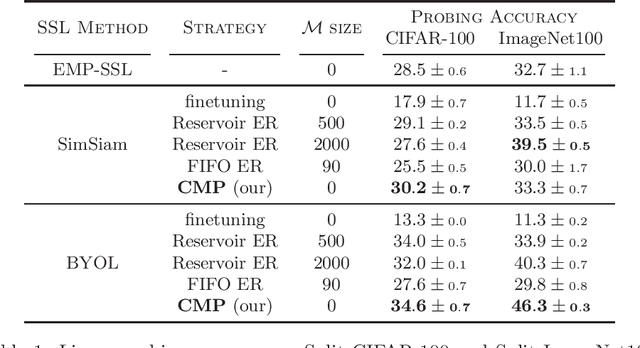
Online Continual Learning (OCL) methods train a model on a non-stationary data stream where only a few examples are available at a time, often leveraging replay strategies. However, usage of replay is sometimes forbidden, especially in applications with strict privacy regulations. Therefore, we propose Continual MultiPatches (CMP), an effective plug-in for existing OCL self-supervised learning strategies that avoids the use of replay samples. CMP generates multiple patches from a single example and projects them into a shared feature space, where patches coming from the same example are pushed together without collapsing into a single point. CMP surpasses replay and other SSL-based strategies on OCL streams, challenging the role of replay as a go-to solution for self-supervised OCL.
Online Curvature-Aware Replay: Leveraging $\mathbf{2^{nd}}$ Order Information for Online Continual Learning
Feb 03, 2025



Online Continual Learning (OCL) models continuously adapt to nonstationary data streams, usually without task information. These settings are complex and many traditional CL methods fail, while online methods (mainly replay-based) suffer from instabilities after the task shift. To address this issue, we formalize replay-based OCL as a second-order online joint optimization with explicit KL-divergence constraints on replay data. We propose Online Curvature-Aware Replay (OCAR) to solve the problem: a method that leverages second-order information of the loss using a K-FAC approximation of the Fisher Information Matrix (FIM) to precondition the gradient. The FIM acts as a stabilizer to prevent forgetting while also accelerating the optimization in non-interfering directions. We show how to adapt the estimation of the FIM to a continual setting stabilizing second-order optimization for non-iid data, uncovering the role of the Tikhonov regularization in the stability-plasticity tradeoff. Empirical results show that OCAR outperforms state-of-the-art methods in continual metrics achieving higher average accuracy throughout the training process in three different benchmarks.
GAS-Norm: Score-Driven Adaptive Normalization for Non-Stationary Time Series Forecasting in Deep Learning
Oct 04, 2024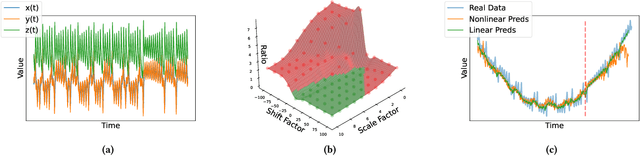
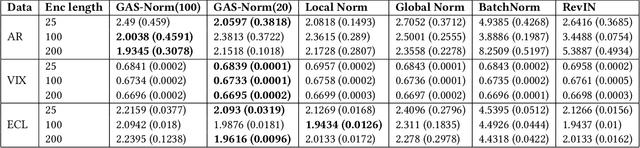
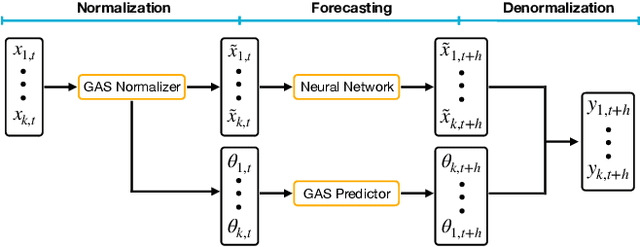
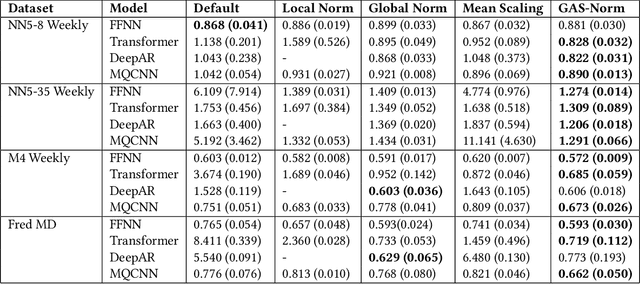
Despite their popularity, deep neural networks (DNNs) applied to time series forecasting often fail to beat simpler statistical models. One of the main causes of this suboptimal performance is the data non-stationarity present in many processes. In particular, changes in the mean and variance of the input data can disrupt the predictive capability of a DNN. In this paper, we first show how DNN forecasting models fail in simple non-stationary settings. We then introduce GAS-Norm, a novel methodology for adaptive time series normalization and forecasting based on the combination of a Generalized Autoregressive Score (GAS) model and a Deep Neural Network. The GAS approach encompasses a score-driven family of models that estimate the mean and variance at each new observation, providing updated statistics to normalize the input data of the deep model. The output of the DNN is eventually denormalized using the statistics forecasted by the GAS model, resulting in a hybrid approach that leverages the strengths of both statistical modeling and deep learning. The adaptive normalization improves the performance of the model in non-stationary settings. The proposed approach is model-agnostic and can be applied to any DNN forecasting model. To empirically validate our proposal, we first compare GAS-Norm with other state-of-the-art normalization methods. We then combine it with state-of-the-art DNN forecasting models and test them on real-world datasets from the Monash open-access forecasting repository. Results show that deep forecasting models improve their performance in 21 out of 25 settings when combined with GAS-Norm compared to other normalization methods.
* Accepted at CIKM '24
A Comprehensive Empirical Evaluation on Online Continual Learning
Sep 01, 2023Online continual learning aims to get closer to a live learning experience by learning directly on a stream of data with temporally shifting distribution and by storing a minimum amount of data from that stream. In this empirical evaluation, we evaluate various methods from the literature that tackle online continual learning. More specifically, we focus on the class-incremental setting in the context of image classification, where the learner must learn new classes incrementally from a stream of data. We compare these methods on the Split-CIFAR100 and Split-TinyImagenet benchmarks, and measure their average accuracy, forgetting, stability, and quality of the representations, to evaluate various aspects of the algorithm at the end but also during the whole training period. We find that most methods suffer from stability and underfitting issues. However, the learned representations are comparable to i.i.d. training under the same computational budget. No clear winner emerges from the results and basic experience replay, when properly tuned and implemented, is a very strong baseline. We release our modular and extensible codebase at https://github.com/AlbinSou/ocl_survey based on the avalanche framework to reproduce our results and encourage future research.
Improving Online Continual Learning Performance and Stability with Temporal Ensembles
Jul 03, 2023



Neural networks are very effective when trained on large datasets for a large number of iterations. However, when they are trained on non-stationary streams of data and in an online fashion, their performance is reduced (1) by the online setup, which limits the availability of data, (2) due to catastrophic forgetting because of the non-stationary nature of the data. Furthermore, several recent works (Caccia et al., 2022; Lange et al., 2023) arXiv:2205.13452 showed that replay methods used in continual learning suffer from the stability gap, encountered when evaluating the model continually (rather than only on task boundaries). In this article, we study the effect of model ensembling as a way to improve performance and stability in online continual learning. We notice that naively ensembling models coming from a variety of training tasks increases the performance in online continual learning considerably. Starting from this observation, and drawing inspirations from semi-supervised learning ensembling methods, we use a lightweight temporal ensemble that computes the exponential moving average of the weights (EMA) at test time, and show that it can drastically increase the performance and stability when used in combination with several methods from the literature.