 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiGraspNet: A Multitask 3D Vision Model for Multi-gripper Robotic Grasping
Feb 06, 2026Vision-based models for robotic grasping automate critical, repetitive, and draining industrial tasks. Existing approaches are typically limited in two ways: they either target a single gripper and are potentially applied on costly dual-arm setups, or rely on custom hybrid grippers that require ad-hoc learning procedures with logic that cannot be transferred across tasks, restricting their general applicability. In this work, we present MultiGraspNet, a novel multitask 3D deep learning method that predicts feasible poses simultaneously for parallel and vacuum grippers within a unified framework, enabling a single robot to handle multiple end effectors. The model is trained on the richly annotated GraspNet-1Billion and SuctionNet-1Billion datasets, which have been aligned for the purpose, and generates graspability masks quantifying the suitability of each scene point for successful grasps. By sharing early-stage features while maintaining gripper-specific refiners, MultiGraspNet effectively leverages complementary information across grasping modalities, enhancing robustness and adaptability in cluttered scenes. We characterize MultiGraspNet's performance with an extensive experimental analysis, demonstrating its competitiveness with single-task models on relevant benchmarks. We run real-world experiments on a single-arm multi-gripper robotic setup showing that our approach outperforms the vacuum baseline, grasping 16% percent more seen objects and 32% more of the novel ones, while obtaining competitive results for the parallel task.
MaskPlanner: Learning-Based Object-Centric Motion Generation from 3D Point Clouds
Feb 26, 2025Object-Centric Motion Generation (OCMG) plays a key role in a variety of industrial applications$\unicode{x2014}$such as robotic spray painting and welding$\unicode{x2014}$requiring efficient, scalable, and generalizable algorithms to plan multiple long-horizon trajectories over free-form 3D objects. However, existing solutions rely on specialized heuristics, expensive optimization routines, or restrictive geometry assumptions that limit their adaptability to real-world scenarios. In this work, we introduce a novel, fully data-driven framework that tackles OCMG directly from 3D point clouds, learning to generalize expert path patterns across free-form surfaces. We propose MaskPlanner, a deep learning method that predicts local path segments for a given object while simultaneously inferring "path masks" to group these segments into distinct paths. This design induces the network to capture both local geometric patterns and global task requirements in a single forward pass. Extensive experimentation on a realistic robotic spray painting scenario shows that our approach attains near-complete coverage (above 99%) for unseen objects, while it remains task-agnostic and does not explicitly optimize for paint deposition. Moreover, our real-world validation on a 6-DoF specialized painting robot demonstrates that the generated trajectories are directly executable and yield expert-level painting quality. Our findings crucially highlight the potential of the proposed learning method for OCMG to reduce engineering overhead and seamlessly adapt to several industrial use cases.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Long-Term Upper-Limb Prosthesis Myocontrol via High-Density sEMG and Incremental Learning
Dec 20, 2024



Noninvasive human-machine interfaces such as surface electromyography (sEMG) have long been employed for controlling robotic prostheses. However, classical controllers are limited to few degrees of freedom (DoF). More recently, machine learning methods have been proposed to learn personalized controllers from user data. While promising, they often suffer from distribution shift during long-term usage, requiring costly model re-training. Moreover, most prosthetic sEMG sensors have low spatial density, which limits accuracy and the number of controllable motions. In this work, we address both challenges by introducing a novel myoelectric prosthetic system integrating a high density-sEMG (HD-sEMG) setup and incremental learning methods to accurately control 7 motions of the Hannes prosthesis. First, we present a newly designed, compact HD-sEMG interface equipped with 64 dry electrodes positioned over the forearm. Then, we introduce an efficient incremental learning system enabling model adaptation on a stream of data. We thoroughly analyze multiple learning algorithms across 7 subjects, including one with limb absence, and 6 sessions held in different days covering an extended period of several months. The size and time span of the collected data represent a relevant contribution for studying long-term myocontrol performance. Therefore, we release the DELTA dataset together with our experimental code.
Accelerating Heterogeneous Federated Learning with Closed-form Classifiers
Jun 03, 2024Federated Learning (FL) methods often struggle in highly statistically heterogeneous settings. Indeed, non-IID data distributions cause client drift and biased local solutions, particularly pronounced in the final classification layer, negatively impacting convergence speed and accuracy. To address this issue, we introduce Federated Recursive Ridge Regression (Fed3R). Our method fits a Ridge Regression classifier computed in closed form leveraging pre-trained features. Fed3R is immune to statistical heterogeneity and is invariant to the sampling order of the clients. Therefore, it proves particularly effective in cross-device scenarios. Furthermore, it is fast and efficient in terms of communication and computation costs, requiring up to two orders of magnitude fewer resources than the competitors. Finally, we propose to leverage the Fed3R parameters as an initialization for a softmax classifier and subsequently fine-tune the model using any FL algorithm (Fed3R with Fine-Tuning, Fed3R+FT). Our findings also indicate that maintaining a fixed classifier aids in stabilizing the training and learning more discriminative features in cross-device settings. Official website: https://fed-3r.github.io/.
Key Design Choices in Source-Free Unsupervised Domain Adaptation: An In-depth Empirical Analysis
Feb 25, 2024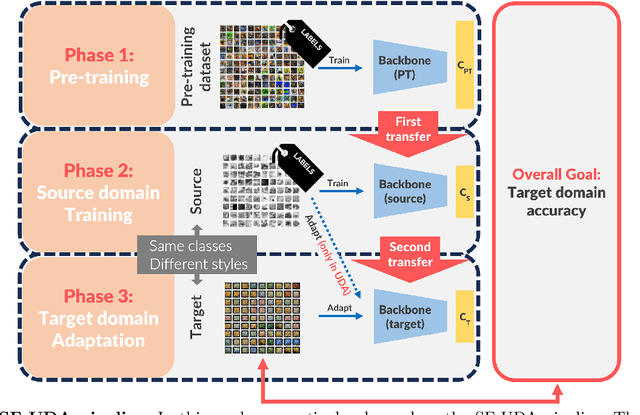
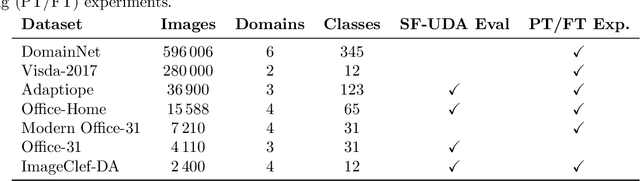


This study provides a comprehensive benchmark framework for Source-Free Unsupervised Domain Adaptation (SF-UDA) in image classification, aiming to achieve a rigorous empirical understanding of the complex relationships between multiple key design factors in SF-UDA methods. The study empirically examines a diverse set of SF-UDA techniques, assessing their consistency across datasets, sensitivity to specific hyperparameters, and applicability across different families of backbone architectures. Moreover, it exhaustively evaluates pre-training datasets and strategies, particularly focusing on both supervised and self-supervised methods, as well as the impact of fine-tuning on the source domain. Our analysis also highlights gaps in existing benchmark practices, guiding SF-UDA research towards more effective and general approaches. It emphasizes the importance of backbone architecture and pre-training dataset selection on SF-UDA performance, serving as an essential reference and providing key insights. Lastly, we release the source code of our experimental framework. This facilitates the construction, training, and testing of SF-UDA methods, enabling systematic large-scale experimental analysis and supporting further research efforts in this field.
Learning Rhythmic Trajectories with Geometric Constraints for Laser-Based Skincare Procedures
Dec 21, 2023The increasing deployment of robots has significantly enhanced the automation levels across a wide and diverse range of industries. This paper investigates the automation challenges of laser-based dermatology procedures in the beauty industry; This group of related manipulation tasks involves delivering energy from a cosmetic laser onto the skin with repetitive patterns. To automate this procedure, we propose to use a robotic manipulator and endow it with the dexterity of a skilled dermatology practitioner through a learning-from-demonstration framework. To ensure that the cosmetic laser can properly deliver the energy onto the skin surface of an individual, we develop a novel structured prediction-based imitation learning algorithm with the merit of handling geometric constraints. Notably, our proposed algorithm effectively tackles the imitation challenges associated with quasi-periodic motions, a common feature of many laser-based cosmetic tasks. The conducted real-world experiments illustrate the performance of our robotic beautician in mimicking realistic dermatological procedures; Our new method is shown to not only replicate the rhythmic movements from the provided demonstrations but also to adapt the acquired skills to previously unseen scenarios and subjects.
A Structured Prediction Approach for Robot Imitation Learning
Sep 26, 2023We propose a structured prediction approach for robot imitation learning from demonstrations. Among various tools for robot imitation learning, supervised learning has been observed to have a prominent role. Structured prediction is a form of supervised learning that enables learning models to operate on output spaces with complex structures. Through the lens of structured prediction, we show how robots can learn to imitate trajectories belonging to not only Euclidean spaces but also Riemannian manifolds. Exploiting ideas from information theory, we propose a class of loss functions based on the f-divergence to measure the information loss between the demonstrated and reproduced probabilistic trajectories. Different types of f-divergence will result in different policies, which we call imitation modes. Furthermore, our approach enables the incorporation of spatial and temporal trajectory modulation, which is necessary for robots to be adaptive to the change in working conditions. We benchmark our algorithm against state-of-the-art methods in terms of trajectory reproduction and adaptation. The quantitative evaluation shows that our approach outperforms other algorithms regarding both accuracy and efficiency. We also report real-world experimental results on learning manifold trajectories in a polishing task with a KUKA LWR robot arm, illustrating the effectiveness of our algorithmic framework.
TempoRL: laser pulse temporal shape optimization with Deep Reinforcement Learning
Apr 20, 2023High Power Laser's (HPL) optimal performance is essential for the success of a wide variety of experimental tasks related to light-matter interactions. Traditionally, HPL parameters are optimised in an automated fashion relying on black-box numerical methods. However, these can be demanding in terms of computational resources and usually disregard transient and complex dynamics. Model-free Deep Reinforcement Learning (DRL) offers a promising alternative framework for optimising HPL performance since it allows to tune the control parameters as a function of system states subject to nonlinear temporal dynamics without requiring an explicit dynamics model of those. Furthermore, DRL aims to find an optimal control policy rather than a static parameter configuration, particularly suitable for dynamic processes involving sequential decision-making. This is particularly relevant as laser systems are typically characterised by dynamic rather than static traits. Hence the need for a strategy to choose the control applied based on the current context instead of one single optimal control configuration. This paper investigates the potential of DRL in improving the efficiency and safety of HPL control systems. We apply this technique to optimise the temporal profile of laser pulses in the L1 pump laser hosted at the ELI Beamlines facility. We show how to adapt DRL to the setting of spectral phase control by solely tuning dispersion coefficients of the spectral phase and reaching pulses similar to transform limited with full-width at half-maximum (FWHM) of ca1.6 ps.
Key Design Choices for Double-Transfer in Source-Free Unsupervised Domain Adaptation
Feb 10, 2023Fine-tuning and Domain Adaptation emerged as effective strategies for efficiently transferring deep learning models to new target tasks. However, target domain labels are not accessible in many real-world scenarios. This led to the development of Unsupervised Domain Adaptation (UDA) methods, which only employ unlabeled target samples. Furthermore, efficiency and privacy requirements may also prevent the use of source domain data during the adaptation stage. This challenging setting, known as Source-Free Unsupervised Domain Adaptation (SF-UDA), is gaining interest among researchers and practitioners due to its potential for real-world applications. In this paper, we provide the first in-depth analysis of the main design choices in SF-UDA through a large-scale empirical study across 500 models and 74 domain pairs. We pinpoint the normalization approach, pre-training strategy, and backbone architecture as the most critical factors. Based on our quantitative findings, we propose recipes to best tackle SF-UDA scenarios. Moreover, we show that SF-UDA is competitive also beyond standard benchmarks and backbone architectures, performing on par with UDA at a fraction of the data and computational cost. In the interest of reproducibility, we include the full experimental results and code as supplementary material.