 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multisensory Pretraining for Contact-Rich Robot Reinforcement Learning
Nov 18, 2025
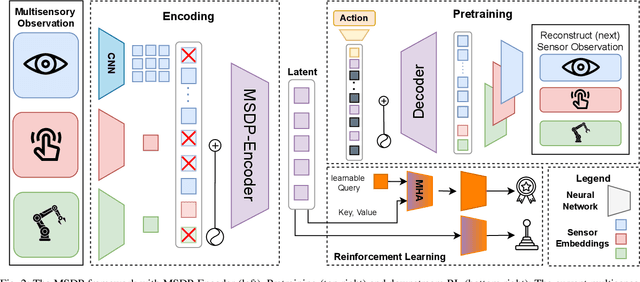
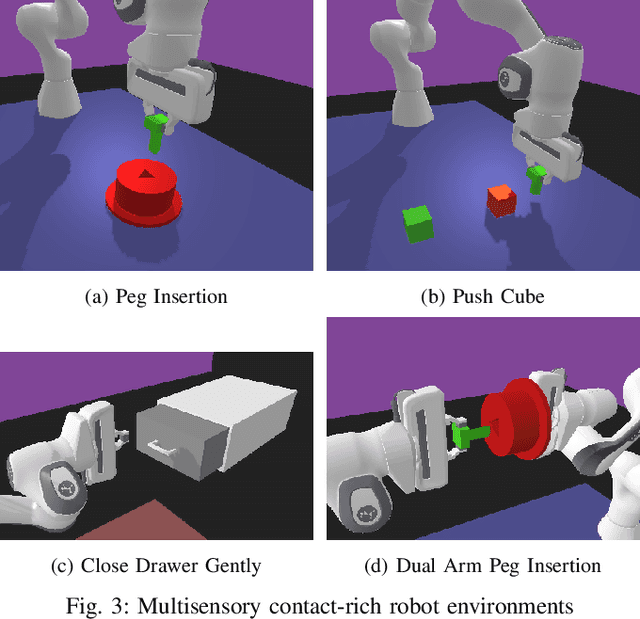
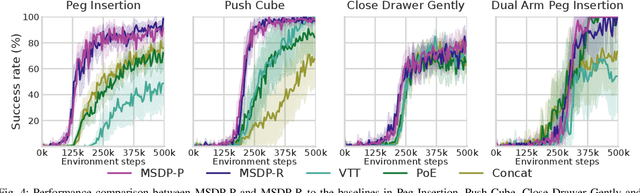
Effective contact-rich manipulation requires robots to synergistically leverage vision, force, and proprioception. However, Reinforcement Learning agents struggle to learn in such multisensory settings, especially amidst sensory noise and dynamic changes. We propose MultiSensory Dynamic Pretraining (MSDP), a novel framework for learning expressive multisensory representations tailored for task-oriented policy learning. MSDP is based on masked autoencoding and trains a transformer-based encoder by reconstructing multisensory observations from only a subset of sensor embeddings, leading to cross-modal prediction and sensor fusion. For downstream policy learning, we introduce a novel asymmetric architecture, where a cross-attention mechanism allows the critic to extract dynamic, task-specific features from the frozen embeddings, while the actor receives a stable pooled representation to guide its actions. Our method demonstrates accelerated learning and robust performance under diverse perturbations, including sensor noise, and changes in object dynamics. Evaluations in multiple challenging, contact-rich robot manipulation tasks in simulation and the real world showcase the effectiveness of MSDP. Our approach exhibits strong robustness to perturbations and achieves high success rates on the real robot with as few as 6,000 online interactions, offering a simple yet powerful solution for complex multisensory robotic control.
Sim-is-More: Randomizing HW-NAS with Synthetic Devices
Apr 01, 2025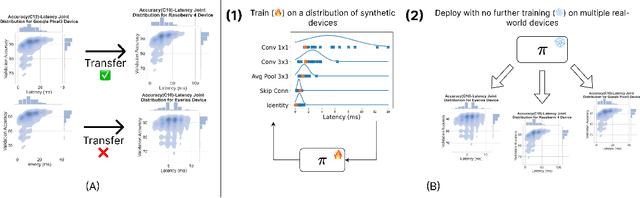
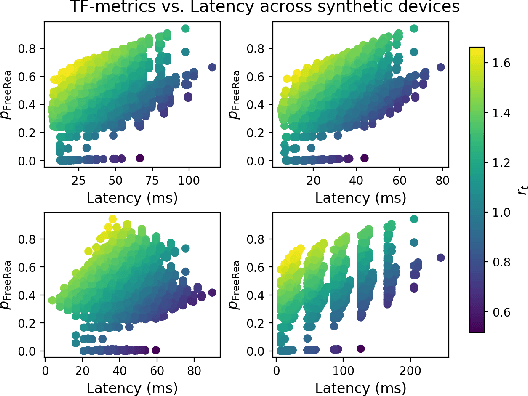
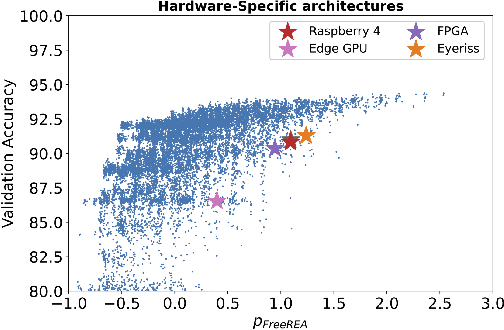
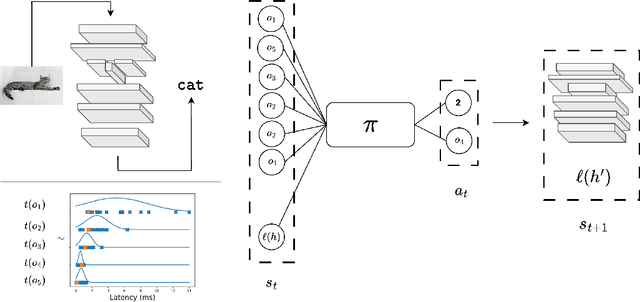
Existing hardware-aware NAS (HW-NAS) methods typically assume access to precise information circa the target device, either via analytical approximations of the post-compilation latency model, or through learned latency predictors. Such approximate approaches risk introducing estimation errors that may prove detrimental in risk-sensitive applications. In this work, we propose a two-stage HW-NAS framework, in which we first learn an architecture controller on a distribution of synthetic devices, and then directly deploy the controller on a target device. At test-time, our network controller deploys directly to the target device without relying on any pre-collected information, and only exploits direct interactions. In particular, the pre-training phase on synthetic devices enables the controller to design an architecture for the target device by interacting with it through a small number of high-fidelity latency measurements. To guarantee accessibility of our method, we only train our controller with training-free accuracy proxies, allowing us to scale the meta-training phase without incurring the overhead of full network training. We benchmark on HW-NATS-Bench, demonstrating that our method generalizes to unseen devices and searches for latency-efficient architectures by in-context adaptation using only a few real-world latency evaluations at test-time.
MaskPlanner: Learning-Based Object-Centric Motion Generation from 3D Point Clouds
Feb 26, 2025Object-Centric Motion Generation (OCMG) plays a key role in a variety of industrial applications$\unicode{x2014}$such as robotic spray painting and welding$\unicode{x2014}$requiring efficient, scalable, and generalizable algorithms to plan multiple long-horizon trajectories over free-form 3D objects. However, existing solutions rely on specialized heuristics, expensive optimization routines, or restrictive geometry assumptions that limit their adaptability to real-world scenarios. In this work, we introduce a novel, fully data-driven framework that tackles OCMG directly from 3D point clouds, learning to generalize expert path patterns across free-form surfaces. We propose MaskPlanner, a deep learning method that predicts local path segments for a given object while simultaneously inferring "path masks" to group these segments into distinct paths. This design induces the network to capture both local geometric patterns and global task requirements in a single forward pass. Extensive experimentation on a realistic robotic spray painting scenario shows that our approach attains near-complete coverage (above 99%) for unseen objects, while it remains task-agnostic and does not explicitly optimize for paint deposition. Moreover, our real-world validation on a 6-DoF specialized painting robot demonstrates that the generated trajectories are directly executable and yield expert-level painting quality. Our findings crucially highlight the potential of the proposed learning method for OCMG to reduce engineering overhead and seamlessly adapt to several industrial use cases.
Domain Randomization via Entropy Maximization
Nov 03, 2023Varying dynamics parameters in simulation is a popular Domain Randomization (DR) approach for overcoming the reality gap in Reinforcement Learning (RL). Nevertheless, DR heavily hinges on the choice of the sampling distribution of the dynamics parameters, since high variability is crucial to regularize the agent's behavior but notoriously leads to overly conservative policies when randomizing excessively. In this paper, we propose a novel approach to address sim-to-real transfer, which automatically shapes dynamics distributions during training in simulation without requiring real-world data. We introduce DOmain RAndomization via Entropy MaximizatiON (DORAEMON), a constrained optimization problem that directly maximizes the entropy of the training distribution while retaining generalization capabilities. In achieving this, DORAEMON gradually increases the diversity of sampled dynamics parameters as long as the probability of success of the current policy is sufficiently high. We empirically validate the consistent benefits of DORAEMON in obtaining highly adaptive and generalizable policies, i.e. solving the task at hand across the widest range of dynamics parameters, as opposed to representative baselines from the DR literature. Notably, we also demonstrate the Sim2Real applicability of DORAEMON through its successful zero-shot transfer in a robotic manipulation setup under unknown real-world parameters.
TempoRL: laser pulse temporal shape optimization with Deep Reinforcement Learning
Apr 20, 2023High Power Laser's (HPL) optimal performance is essential for the success of a wide variety of experimental tasks related to light-matter interactions. Traditionally, HPL parameters are optimised in an automated fashion relying on black-box numerical methods. However, these can be demanding in terms of computational resources and usually disregard transient and complex dynamics. Model-free Deep Reinforcement Learning (DRL) offers a promising alternative framework for optimising HPL performance since it allows to tune the control parameters as a function of system states subject to nonlinear temporal dynamics without requiring an explicit dynamics model of those. Furthermore, DRL aims to find an optimal control policy rather than a static parameter configuration, particularly suitable for dynamic processes involving sequential decision-making. This is particularly relevant as laser systems are typically characterised by dynamic rather than static traits. Hence the need for a strategy to choose the control applied based on the current context instead of one single optimal control configuration. This paper investigates the potential of DRL in improving the efficiency and safety of HPL control systems. We apply this technique to optimise the temporal profile of laser pulses in the L1 pump laser hosted at the ELI Beamlines facility. We show how to adapt DRL to the setting of spectral phase control by solely tuning dispersion coefficients of the spectral phase and reaching pulses similar to transform limited with full-width at half-maximum (FWHM) of ca1.6 ps.
Domain Randomization for Robust, Affordable and Effective Closed-loop Control of Soft Robots
Mar 07, 2023Soft robots are becoming extremely popular thanks to their intrinsic safety to contacts and adaptability. However, the potentially infinite number of Degrees of Freedom makes their modeling a daunting task, and in many cases only an approximated description is available. This challenge makes reinforcement learning (RL) based approaches inefficient when deployed on a realistic scenario, due to the large domain gap between models and the real platform. In this work, we demonstrate, for the first time, how Domain Randomization (DR) can solve this problem by enhancing RL policies with: i) a higher robustness w.r.t. environmental changes; ii) a higher affordability of learned policies when the target model differs significantly from the training model; iii) a higher effectiveness of the policy, which can even autonomously learn to exploit the environment to increase the robot capabilities (environmental constraints exploitation). Moreover, we introduce a novel algorithmic extension of previous adaptive domain randomization methods for the automatic inference of dynamics parameters for deformable objects. We provide results on four different tasks and two soft robot designs, opening interesting perspectives for future research on Reinforcement Learning for closed-loop soft robot control.
PaintNet: 3D Learning of Pose Paths Generators for Robotic Spray Painting
Nov 13, 2022Optimization and planning methods for tasks involving 3D objects often rely on prior knowledge and ad-hoc heuristics. In this work, we target learning-based long-horizon path generation by leveraging recent advances in 3D deep learning. We present PaintNet, the first dataset for learning robotic spray painting of free-form 3D objects. PaintNet includes more than 800 object meshes and the associated painting strokes collected in a real industrial setting. We then introduce a novel 3D deep learning method to tackle this task and operate on unstructured input spaces -- point clouds -- and mix-structured output spaces -- unordered sets of painting strokes. Our extensive experimental analysis demonstrates the capabilities of our method to predict smooth output strokes that cover up to 95% of previously unseen object surfaces, with respect to ground-truth paint coverage. The PaintNet dataset and an implementation of our proposed approach will be released at https://gabrieletiboni.github.io/paintnet.
Online vs. Offline Adaptive Domain Randomization Benchmark
Jun 29, 2022


Physics simulators have shown great promise for conveniently learning reinforcement learning policies in safe, unconstrained environments. However, transferring the acquired knowledge to the real world can be challenging due to the reality gap. To this end, several methods have been recently proposed to automatically tune simulator parameters with posterior distributions given real data, for use with domain randomization at training time. These approaches have been shown to work for various robotic tasks under different settings and assumptions. Nevertheless, existing literature lacks a thorough comparison of existing adaptive domain randomization methods with respect to transfer performance and real-data efficiency. In this work, we present an open benchmark for both offline and online methods (SimOpt, BayRn, DROID, DROPO), to shed light on which are most suitable for each setting and task at hand. We found that online methods are limited by the quality of the currently learned policy for the next iteration, while offline methods may sometimes fail when replaying trajectories in simulation with open-loop commands. The code used will be released at https://github.com/gabrieletiboni/adr-benchmark.
DROPO: Sim-to-Real Transfer with Offline Domain Randomization
Jan 20, 2022In recent years, domain randomization has gained a lot of traction as a method for sim-to-real transfer of reinforcement learning policies in robotic manipulation; however, finding optimal randomization distributions can be difficult. In this paper, we introduce DROPO, a novel method for estimating domain randomization distributions for safe sim-to-real transfer. Unlike prior work, DROPO only requires a limited, precollected offline dataset of trajectories, and explicitly models parameter uncertainty to match real data. We demonstrate that DROPO is capable of recovering dynamic parameter distributions in simulation and finding a distribution capable of compensating for an unmodelled phenomenon. We also evaluate the method in two zero-shot sim-to-real transfer scenarios, showing successful domain transfer and improved performance over prior methods.