 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Randomization via Entropy Maximization
Nov 03, 2023Varying dynamics parameters in simulation is a popular Domain Randomization (DR) approach for overcoming the reality gap in Reinforcement Learning (RL). Nevertheless, DR heavily hinges on the choice of the sampling distribution of the dynamics parameters, since high variability is crucial to regularize the agent's behavior but notoriously leads to overly conservative policies when randomizing excessively. In this paper, we propose a novel approach to address sim-to-real transfer, which automatically shapes dynamics distributions during training in simulation without requiring real-world data. We introduce DOmain RAndomization via Entropy MaximizatiON (DORAEMON), a constrained optimization problem that directly maximizes the entropy of the training distribution while retaining generalization capabilities. In achieving this, DORAEMON gradually increases the diversity of sampled dynamics parameters as long as the probability of success of the current policy is sufficiently high. We empirically validate the consistent benefits of DORAEMON in obtaining highly adaptive and generalizable policies, i.e. solving the task at hand across the widest range of dynamics parameters, as opposed to representative baselines from the DR literature. Notably, we also demonstrate the Sim2Real applicability of DORAEMON through its successful zero-shot transfer in a robotic manipulation setup under unknown real-world parameters.
On the Benefit of Optimal Transport for Curriculum Reinforcement Learning
Sep 25, 2023



Curriculum reinforcement learning (CRL) allows solving complex tasks by generating a tailored sequence of learning tasks, starting from easy ones and subsequently increasing their difficulty. Although the potential of curricula in RL has been clearly shown in various works, it is less clear how to generate them for a given learning environment, resulting in various methods aiming to automate this task. In this work, we focus on framing curricula as interpolations between task distributions, which has previously been shown to be a viable approach to CRL. Identifying key issues of existing methods, we frame the generation of a curriculum as a constrained optimal transport problem between task distributions. Benchmarks show that this way of curriculum generation can improve upon existing CRL methods, yielding high performance in various tasks with different characteristics.
Tracking Control for a Spherical Pendulum via Curriculum Reinforcement Learning
Sep 25, 2023Reinforcement Learning (RL) allows learning non-trivial robot control laws purely from data. However, many successful applications of RL have relied on ad-hoc regularizations, such as hand-crafted curricula, to regularize the learning performance. In this paper, we pair a recent algorithm for automatically building curricula with RL on massively parallelized simulations to learn a tracking controller for a spherical pendulum on a robotic arm via RL. Through an improved optimization scheme that better respects the non-Euclidean task structure, we allow the method to reliably generate curricula of trajectories to be tracked, resulting in faster and more robust learning compared to an RL baseline that does not exploit this form of structured learning. The learned policy matches the performance of an optimal control baseline on the real system, demonstrating the potential of curriculum RL to jointly learn state estimation and control for non-linear tracking tasks.
Function-Space Regularization for Deep Bayesian Classification
Jul 12, 2023



Bayesian deep learning approaches assume model parameters to be latent random variables and infer posterior distributions to quantify uncertainty, increase safety and trust, and prevent overconfident and unpredictable behavior. However, weight-space priors are model-specific, can be difficult to interpret and are hard to specify. Instead, we apply a Dirichlet prior in predictive space and perform approximate function-space variational inference. To this end, we interpret conventional categorical predictions from stochastic neural network classifiers as samples from an implicit Dirichlet distribution. By adapting the inference, the same function-space prior can be combined with different models without affecting model architecture or size. We illustrate the flexibility and efficacy of such a prior with toy experiments and demonstrate scalability, improved uncertainty quantification and adversarial robustness with large-scale image classification experiments.
Self-Paced Absolute Learning Progress as a Regularized Approach to Curriculum Learning
Jun 09, 2023



The usability of Reinforcement Learning is restricted by the large computation times it requires. Curriculum Reinforcement Learning speeds up learning by defining a helpful order in which an agent encounters tasks, i.e. from simple to hard. Curricula based on Absolute Learning Progress (ALP) have proven successful in different environments, but waste computation on repeating already learned behaviour in new tasks. We solve this problem by introducing a new regularization method based on Self-Paced (Deep) Learning, called Self-Paced Absolute Learning Progress (SPALP). We evaluate our method in three different environments. Our method achieves performance comparable to original ALP in all cases, and reaches it quicker than ALP in two of them. We illustrate possibilities to further improve the efficiency and performance of SPALP.
Variational Hierarchical Mixtures for Learning Probabilistic Inverse Dynamics
Nov 02, 2022Well-calibrated probabilistic regression models are a crucial learning component in robotics applications as datasets grow rapidly and tasks become more complex. Classical regression models are usually either probabilistic kernel machines with a flexible structure that does not scale gracefully with data or deterministic and vastly scalable automata, albeit with a restrictive parametric form and poor regularization. In this paper, we consider a probabilistic hierarchical modeling paradigm that combines the benefits of both worlds to deliver computationally efficient representations with inherent complexity regularization. The presented approaches are probabilistic interpretations of local regression techniques that approximate nonlinear functions through a set of local linear or polynomial units. Importantly, we rely on principles from Bayesian nonparametrics to formulate flexible models that adapt their complexity to the data and can potentially encompass an infinite number of components. We derive two efficient variational inference techniques to learn these representations and highlight the advantages of hierarchical infinite local regression models, such as dealing with non-smooth functions, mitigating catastrophic forgetting, and enabling parameter sharing and fast predictions. Finally, we validate this approach on a set of large inverse dynamics datasets and test the learned models in real-world control scenarios.
Reinforcement Learning using Guided Observability
Apr 22, 2021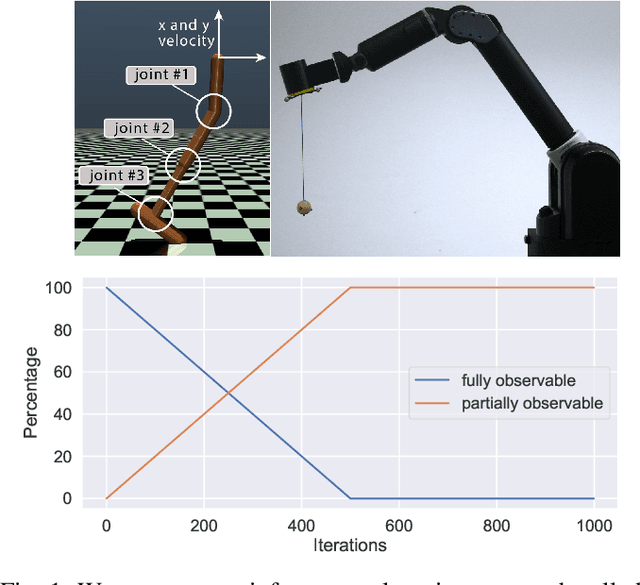

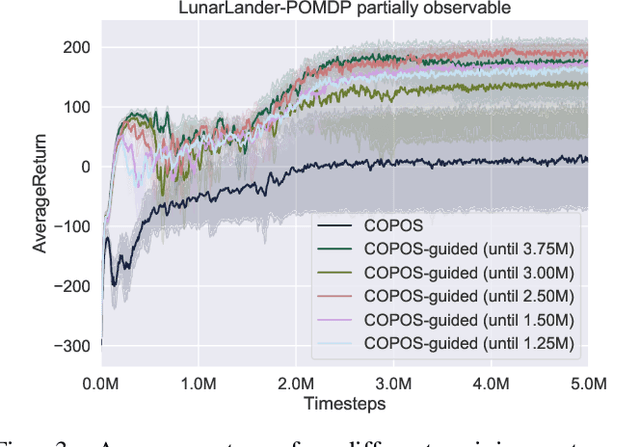
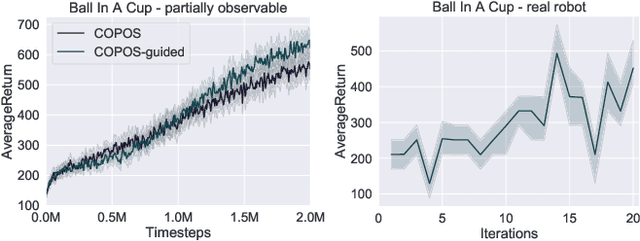
Due to recent breakthroughs, reinforcement learning (RL) has demonstrated impressive performance in challenging sequential decision-making problems. However, an open question is how to make RL cope with partial observability which is prevalent in many real-world problems. Contrary to contemporary RL approaches, which focus mostly on improved memory representations or strong assumptions about the type of partial observability, we propose a simple but efficient approach that can be applied together with a wide variety of RL methods. Our main insight is that smoothly transitioning from full observability to partial observability during the training process yields a high performance policy. The approach, called partially observable guided reinforcement learning (PO-GRL), allows to utilize full state information during policy optimization without compromising the optimality of the final policy. A comprehensive evaluation in discrete partially observableMarkov decision process (POMDP) benchmark problems and continuous partially observable MuJoCo and OpenAI gym tasks shows that PO-GRL improves performance. Finally, we demonstrate PO-GRL in the ball-in-the-cup task on a real Barrett WAM robot under partial observability.
A Probabilistic Interpretation of Self-Paced Learning with Applications to Reinforcement Learning
Feb 25, 2021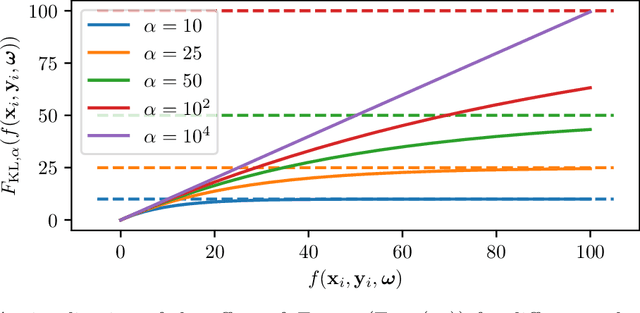
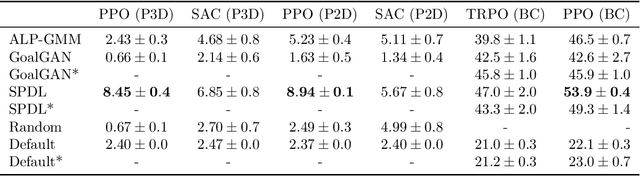
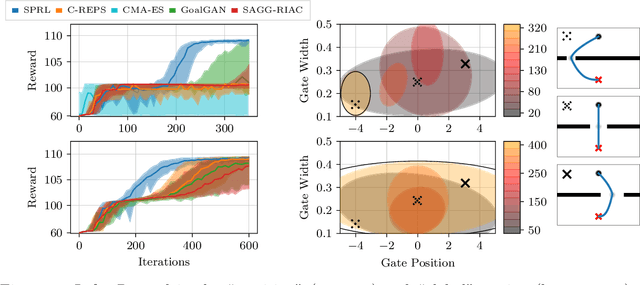
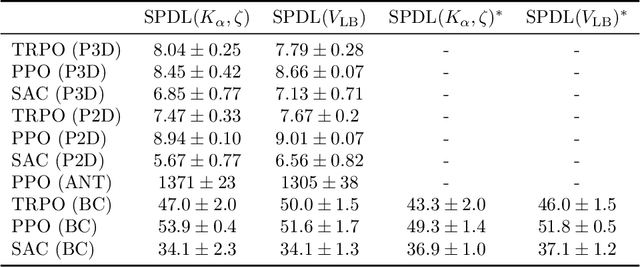
Across machine learning, the use of curricula has shown strong empirical potential to improve learning from data by avoiding local optima of training objectives. For reinforcement learning (RL), curricula are especially interesting, as the underlying optimization has a strong tendency to get stuck in local optima due to the exploration-exploitation trade-off. Recently, a number of approaches for an automatic generation of curricula for RL have been shown to increase performance while requiring less expert knowledge compared to manually designed curricula. However, these approaches are seldomly investigated from a theoretical perspective, preventing a deeper understanding of their mechanics. In this paper, we present an approach for automated curriculum generation in RL with a clear theoretical underpinning. More precisely, we formalize the well-known self-paced learning paradigm as inducing a distribution over training tasks, which trades off between task complexity and the objective to match a desired task distribution. Experiments show that training on this induced distribution helps to avoid poor local optima across RL algorithms in different tasks with uninformative rewards and challenging exploration requirements.
A Variational Infinite Mixture for Probabilistic Inverse Dynamics Learning
Nov 10, 2020
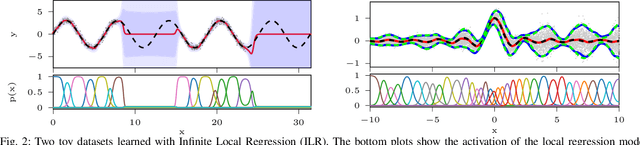
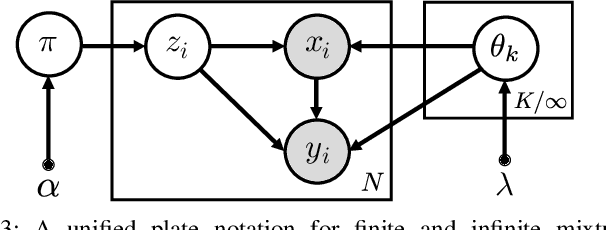
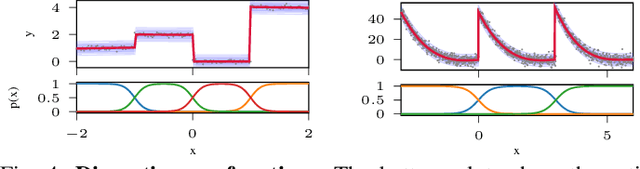
Probabilistic regression techniques in control and robotics applications have to fulfill different criteria of data-driven adaptability, computational efficiency, scalability to high dimensions, and the capacity to deal with different modalities in the data. Classical regressors usually fulfill only a subset of these properties. In this work, we extend seminal work on Bayesian nonparametric mixtures and derive an efficient variational Bayes inference technique for infinite mixtures of probabilistic local polynomial models with well-calibrated certainty quantification. We highlight the model's power in combining data-driven complexity adaptation, fast prediction and the ability to deal with discontinuous functions and heteroscedastic noise. We benchmark this technique on a range of large real inverse dynamics datasets, showing that the infinite mixture formulation is competitive with classical Local Learning methods and regularizes model complexity by adapting the number of components based on data and without relying on heuristics. Moreover, to showcase the practicality of the approach, we use the learned models for online inverse dynamics control of a Barret-WAM manipulator, significantly improving the trajectory tracking performance.
Self-Paced Deep Reinforcement Learning
May 06, 2020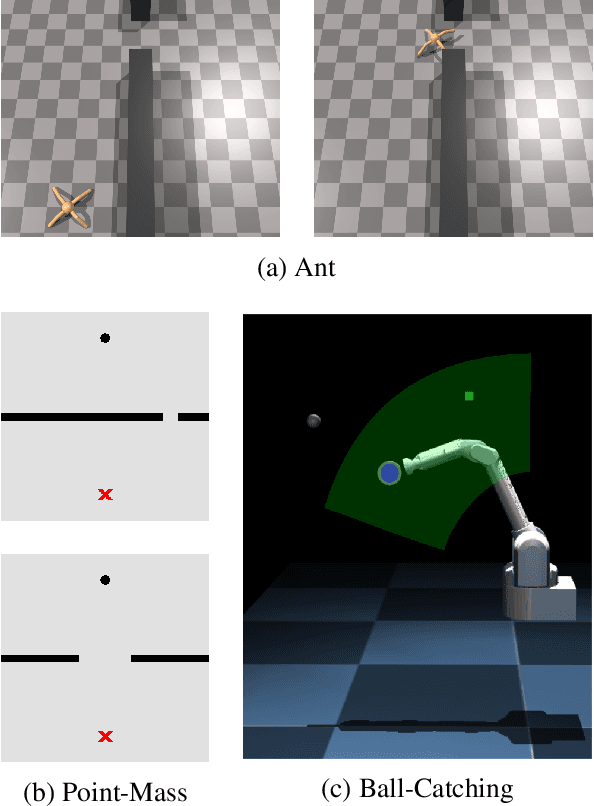

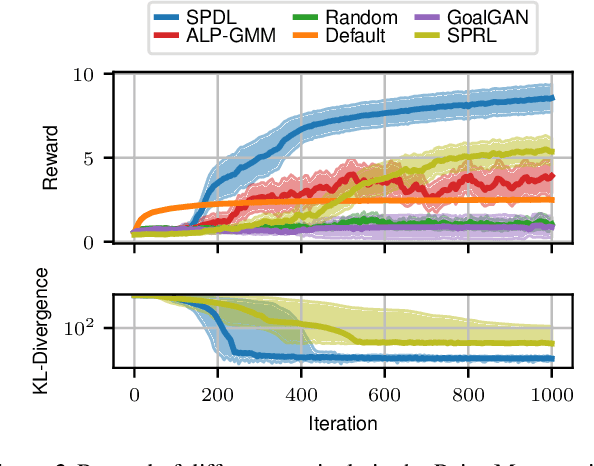
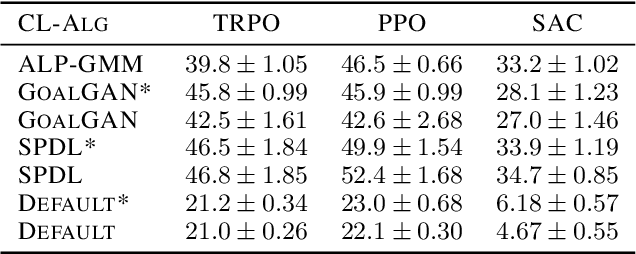
Generalization and reuse of agent behaviour across a variety of learning tasks promises to carry the next wave of breakthroughs in Reinforcement Learning (RL). The field of Curriculum Learning proposes strategies that aim to support a learning agent by exposing it to a tailored series of tasks throughout learning, e.g. by progressively increasing their complexity. In this paper, we consider recently established results in Curriculum Learning for episodic RL, proposing an extension that is easily integrated with well-known RL algorithms and providing a theoretical formulation from an RL-as-Inference perspective. We evaluate the proposed scheme with different Deep RL algorithms on representative tasks, demonstrating that it is capable of significantly improving learning performance.