 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Cascade: Juggling Vanilla Siteswap Patterns
Oct 25, 2024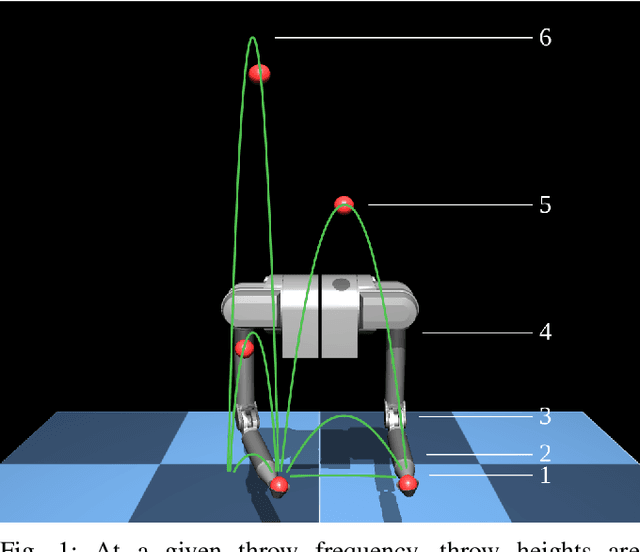
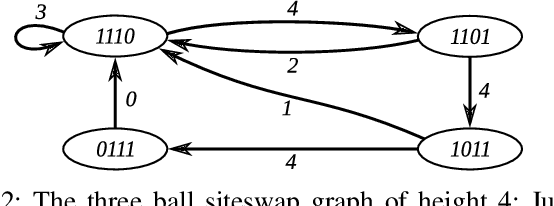
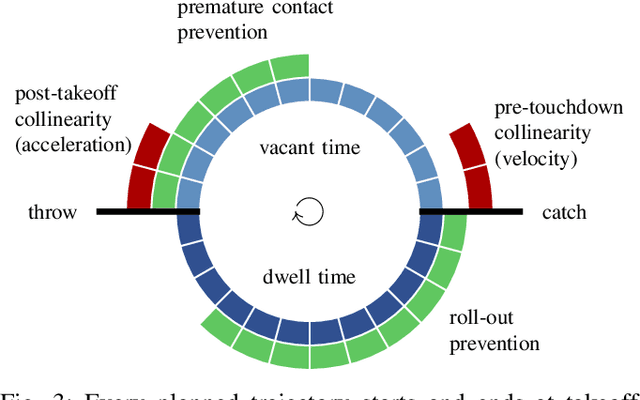
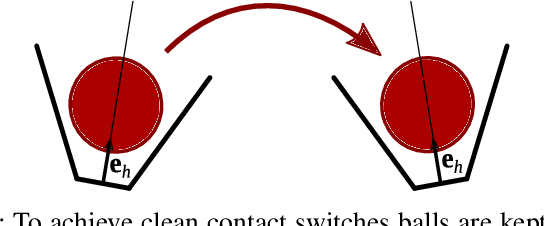
Being widespread in human motor behavior, dynamic movements demonstrate higher efficiency and greater capacity to address a broader range of skill domains compared to their quasi-static counterparts. Among the frequently studied dynamic manipulation problems, robotic juggling tasks stand out due to their inherent ability to scale their difficulty levels to arbitrary extents, making them an excellent subject for investigation. In this study, we explore juggling patterns with mixed throw heights, following the vanilla siteswap juggling notation, which jugglers widely adopted to describe toss juggling patterns. This requires extending our previous analysis of the simpler cascade juggling task by a throw-height sequence planner and further constraints on the end effector trajectory. These are not necessary for cascade patterns but are vital to achieving patterns with mixed throw heights. Using a simulated environment, we demonstrate successful juggling of most common 3-9 ball siteswap patterns up to 9 ball height, transitions between these patterns, and random sequences covering all possible vanilla siteswap patterns with throws between 2 and 9 ball height. https://kai-ploeger.com/beyond-cascades
Tracking Control for a Spherical Pendulum via Curriculum Reinforcement Learning
Sep 25, 2023Reinforcement Learning (RL) allows learning non-trivial robot control laws purely from data. However, many successful applications of RL have relied on ad-hoc regularizations, such as hand-crafted curricula, to regularize the learning performance. In this paper, we pair a recent algorithm for automatically building curricula with RL on massively parallelized simulations to learn a tracking controller for a spherical pendulum on a robotic arm via RL. Through an improved optimization scheme that better respects the non-Euclidean task structure, we allow the method to reliably generate curricula of trajectories to be tracked, resulting in faster and more robust learning compared to an RL baseline that does not exploit this form of structured learning. The learned policy matches the performance of an optimal control baseline on the real system, demonstrating the potential of curriculum RL to jointly learn state estimation and control for non-linear tracking tasks.
Controlling the Cascade: Kinematic Planning for N-ball Toss Juggling
Jul 04, 2022

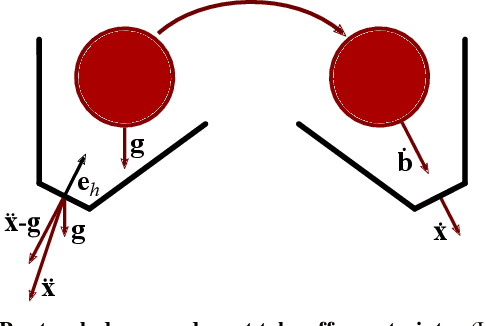
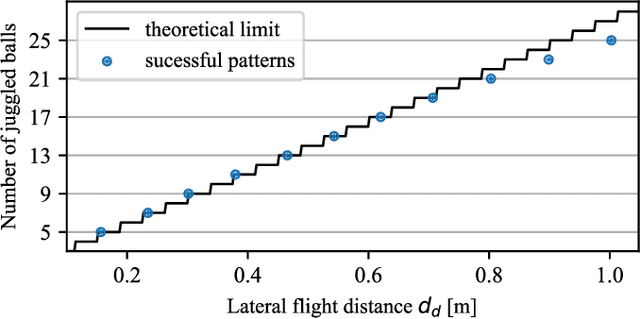
Dynamic movements are ubiquitous in human motor behavior as they tend to be more efficient and can solve a broader range of skill domains than their quasi-static counterparts. For decades, robotic juggling tasks have been among the most frequently studied dynamic manipulation problems since the required dynamic dexterity can be scaled to arbitrarily high difficulty. However, successful approaches have been limited to basic juggling skills, indicating a lack of understanding of the required constraints for dexterous toss juggling. We present a detailed analysis of the toss juggling task, identifying the key challenges and formalizing it as a trajectory optimization problem. Building on our state-of-the-art, real-world toss juggling platform, we reach the theoretical limits of toss juggling in simulation, evaluate a resulting real-time controller in environments of varying difficulty and achieve robust toss juggling of up to 17 balls on two anthropomorphic manipulators.
SKID RAW: Skill Discovery from Raw Trajectories
Mar 26, 2021
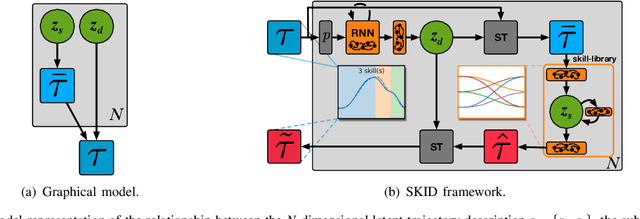
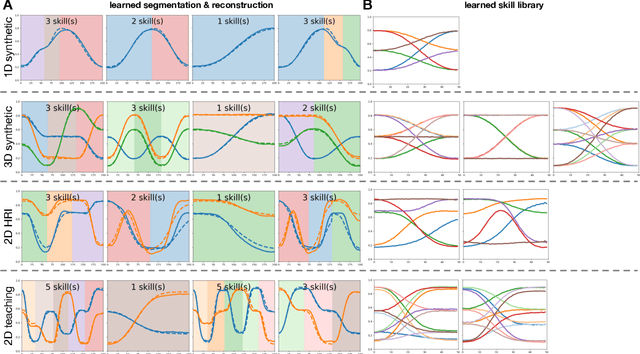
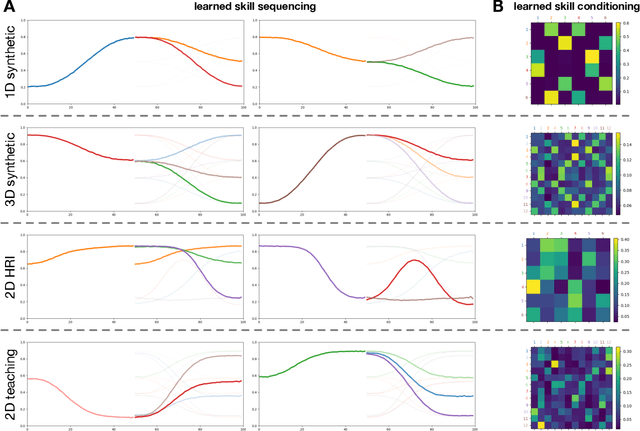
Integrating robots in complex everyday environments requires a multitude of problems to be solved. One crucial feature among those is to equip robots with a mechanism for teaching them a new task in an easy and natural way. When teaching tasks that involve sequences of different skills, with varying order and number of these skills, it is desirable to only demonstrate full task executions instead of all individual skills. For this purpose, we propose a novel approach that simultaneously learns to segment trajectories into reoccurring patterns and the skills to reconstruct these patterns from unlabelled demonstrations without further supervision. Moreover, the approach learns a skill conditioning that can be used to understand possible sequences of skills, a practical mechanism to be used in, for example, human-robot-interactions for a more intelligent and adaptive robot behaviour. The Bayesian and variational inference based approach is evaluated on synthetic and real human demonstrations with varying complexities and dimensionality, showing the successful learning of segmentations and skill libraries from unlabelled data.
High Acceleration Reinforcement Learning for Real-World Juggling with Binary Rewards
Oct 31, 2020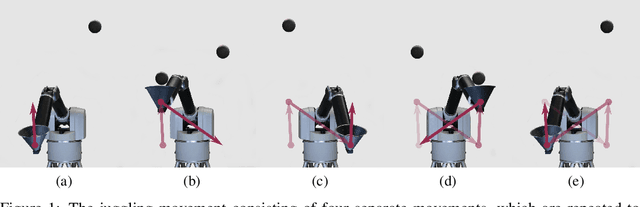

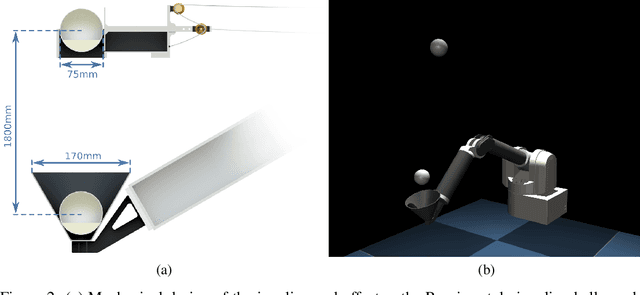
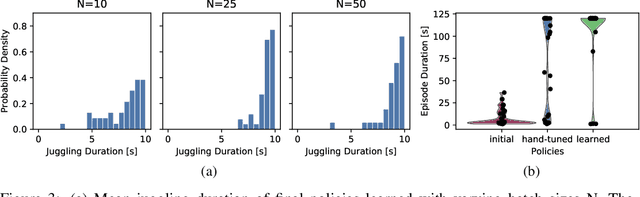
Robots that can learn in the physical world will be important to en-able robots to escape their stiff and pre-programmed movements. For dynamic high-acceleration tasks, such as juggling, learning in the real-world is particularly challenging as one must push the limits of the robot and its actuation without harming the system, amplifying the necessity of sample efficiency and safety for robot learning algorithms. In contrast to prior work which mainly focuses on the learning algorithm, we propose a learning system, that directly incorporates these requirements in the design of the policy representation, initialization, and optimization. We demonstrate that this system enables the high-speed Barrett WAM manipulator to learn juggling two balls from 56 minutes of experience with a binary reward signal. The final policy juggles continuously for up to 33 minutes or about 4500 repeated catches. The videos documenting the learning process and the evaluation can be found at https://sites.google.com/view/jugglingbot
Learning walk and trot from the same objective using different types of exploration
Apr 28, 2019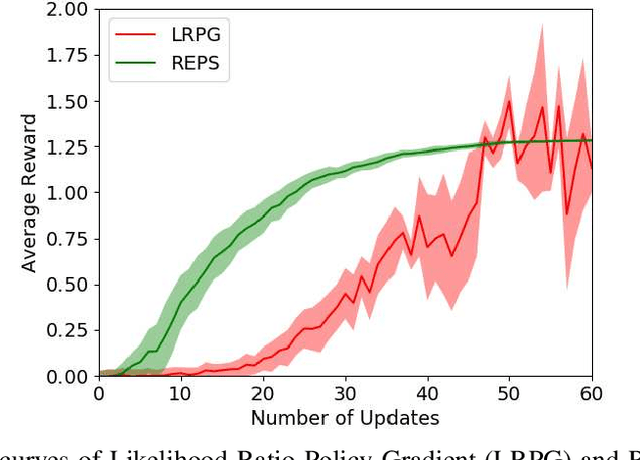
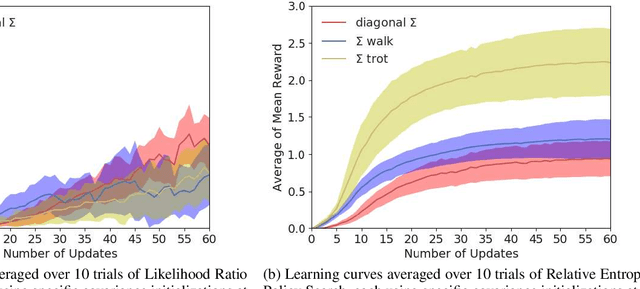
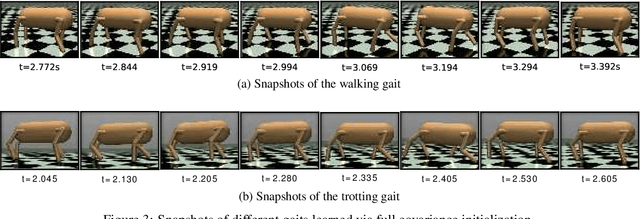
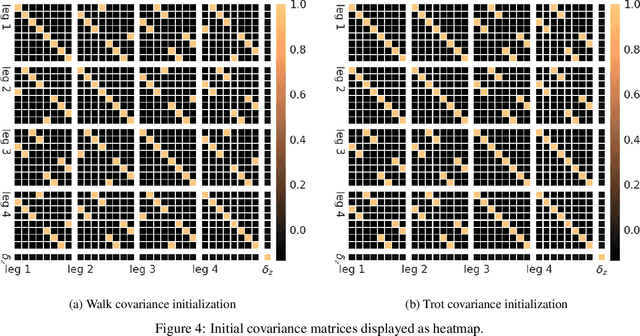
In quadruped gait learning, policy search methods that scale high dimensional continuous action spaces are commonly used. In most approaches, it is necessary to introduce prior knowledge on the gaits to limit the highly non-convex search space of the policies. In this work, we propose a new approach to encode the symmetry properties of the desired gaits, on the initial covariance of the Gaussian search distribution, allowing for strategic exploration. Using episode-based likelihood ratio policy gradient and relative entropy policy search, we learned the gaits walk and trot on a simulated quadruped. Comparing these gaits to random gaits learned by initialized diagonal covariance matrix, we show that the performance can be significantly enhanced.