 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Quality-Diversity Search for Efficient Robot Learning
Aug 11, 2020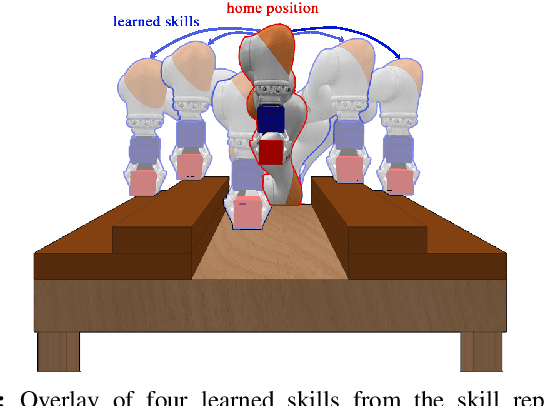
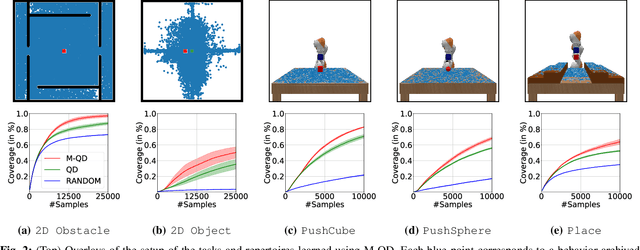
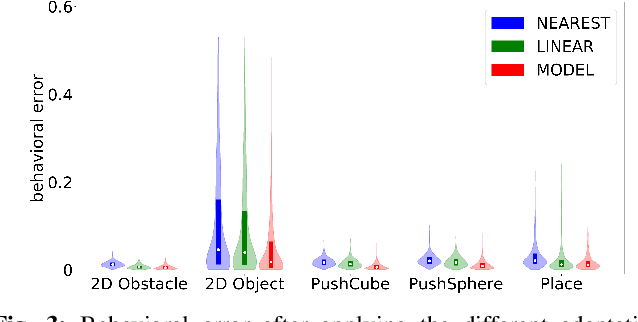
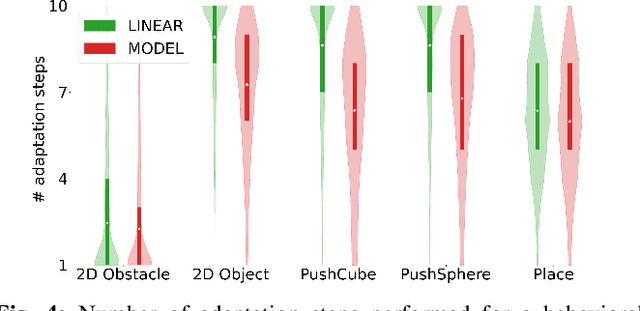
Despite recent progress in robot learning, it still remains a challenge to program a robot to deal with open-ended object manipulation tasks. One approach that was recently used to autonomously generate a repertoire of diverse skills is a novelty based Quality-Diversity~(QD) algorithm. However, as most evolutionary algorithms, QD suffers from sample-inefficiency and, thus, it is challenging to apply it in real-world scenarios. This paper tackles this problem by integrating a neural network that predicts the behavior of the perturbed parameters into a novelty based QD algorithm. In the proposed Model-based Quality-Diversity search (M-QD), the network is trained concurrently to the repertoire and is used to avoid executing unpromising actions in the novelty search process. Furthermore, it is used to adapt the skills of the final repertoire in order to generalize the skills to different scenarios. Our experiments show that enhancing a QD algorithm with such a forward model improves the sample-efficiency and performance of the evolutionary process and the skill adaptation.
Experience Reuse with Probabilistic Movement Primitives
Aug 11, 2019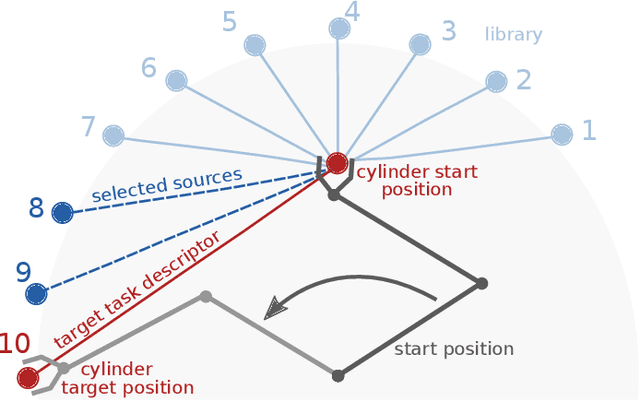
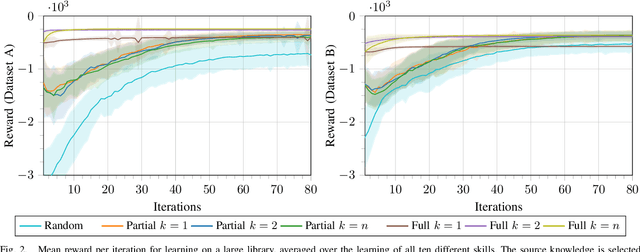
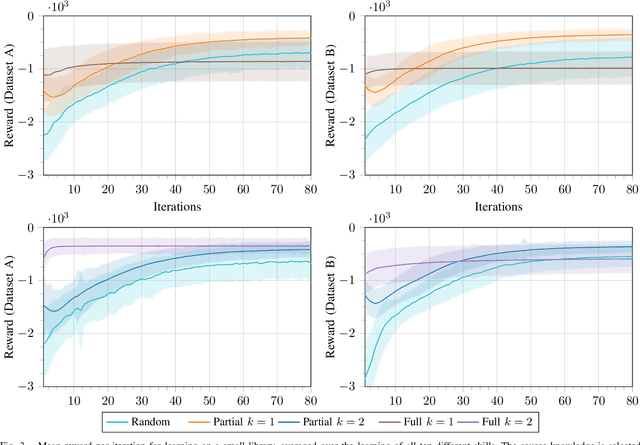
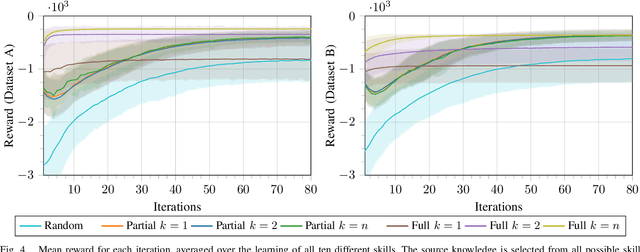
Acquiring new robot motor skills is cumbersome, as learning a skill from scratch and without prior knowledge requires the exploration of a large space of motor configurations. Accordingly, for learning a new task, time could be saved by restricting the parameter search space by initializing it with the solution of a similar task. We present a framework which is able of such knowledge transfer from already learned movement skills to a new learning task. The framework combines probabilistic movement primitives with descriptions of their effects for skill representation. New skills are first initialized with parameters inferred from related movement primitives and thereafter adapted to the new task through relative entropy policy search. We compare two different transfer approaches to initialize the search space distribution with data of known skills with a similar effect. We show the different benefits of the two knowledge transfer approaches on an object pushing task for a simulated 3-DOF robot. We can show that the quality of the learned skills improves and the required iterations to learn a new task can be reduced by more than 60% when past experiences are utilized.
Local Online Motor Babbling: Learning Motor Abundance of A Musculoskeletal Robot Arm
Jun 21, 2019
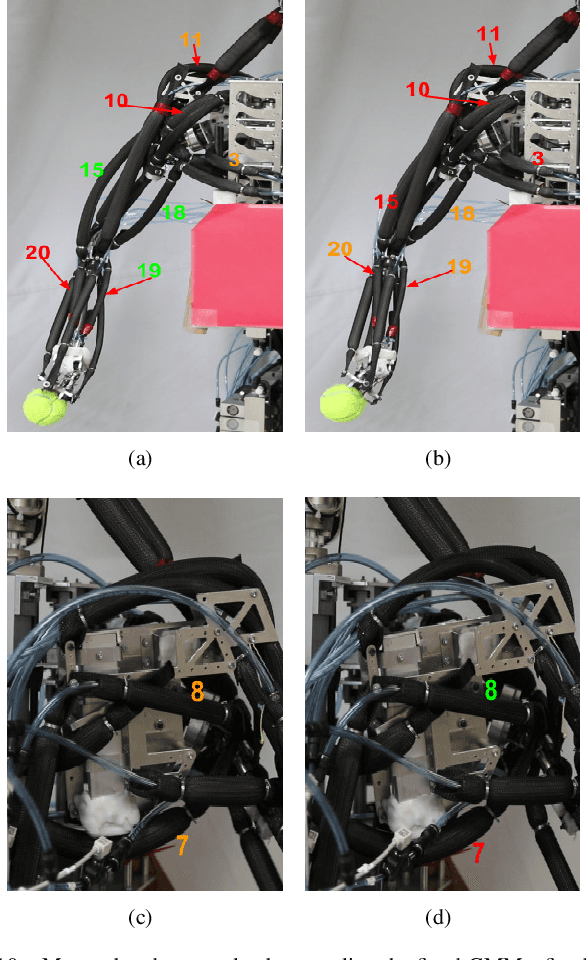
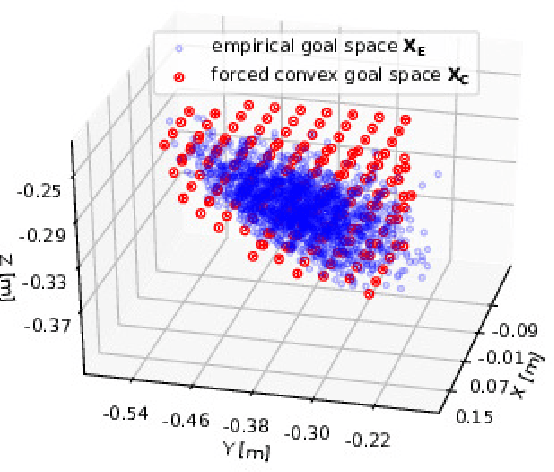
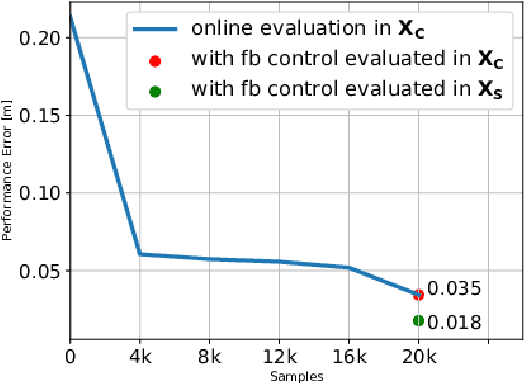
Motor babbling and goal babbling has been used for sensorimotor learning of highly redundant systems in soft robotics. Recent works in goal babbling has demonstrated successful learning of inverse kinematics (IK) on such systems, and suggests that babbling in the goal space better resolves motor redundancy by learning as few sensorimotor mapping as possible. However, for musculoskeletal robot systems, motor redundancy can be of useful information to explain muscle activation patterns, thus the term motor abundance. In this work, we introduce some simple heuristics to empirically define the unknown goal space, and learn the inverse kinematics of a 10 DoF musculoskeletal robot arm using directed goal babbling. We then further propose local online motor babbling using Covariance Matrix Adaptation Evolution Strategy (CMA-ES), which bootstraps on the collected samples in goal babbling for initialization, such that motor abundance can be queried for any static goal within the defined goal space. The result shows that our motor babbling approach can efficiently explore motor abundance, and gives useful insights in terms of muscle stiffness and synergy.
Learning walk and trot from the same objective using different types of exploration
Apr 28, 2019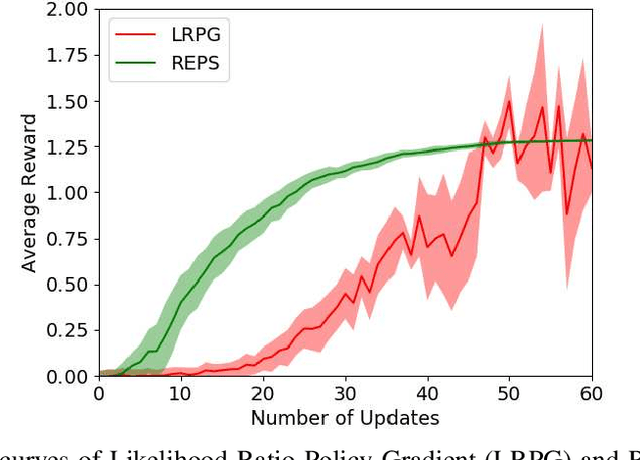
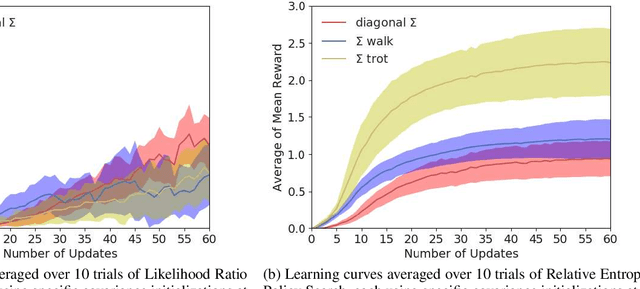
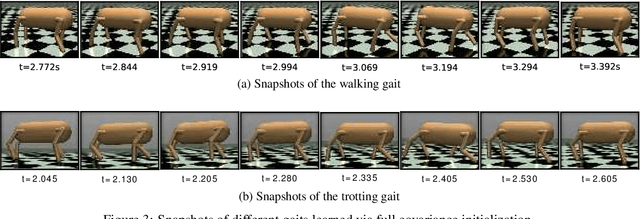
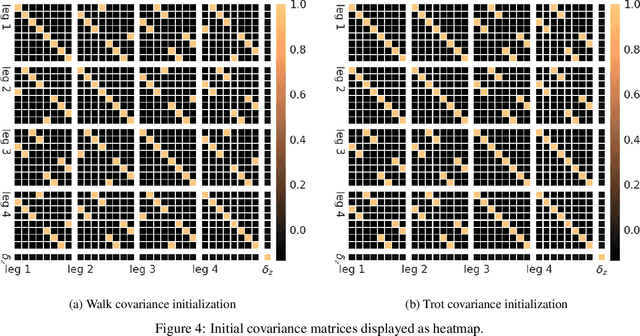
In quadruped gait learning, policy search methods that scale high dimensional continuous action spaces are commonly used. In most approaches, it is necessary to introduce prior knowledge on the gaits to limit the highly non-convex search space of the policies. In this work, we propose a new approach to encode the symmetry properties of the desired gaits, on the initial covariance of the Gaussian search distribution, allowing for strategic exploration. Using episode-based likelihood ratio policy gradient and relative entropy policy search, we learned the gaits walk and trot on a simulated quadruped. Comparing these gaits to random gaits learned by initialized diagonal covariance matrix, we show that the performance can be significantly enhanced.