 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Neurocomputation: A Framework for Interfacing Biological Neural Cultures with Scaled Task-Driven Validation
May 13, 2026Biological neural networks (BNNs) have been established as a powerful and adaptive substrate that offer the potential for incredibly energy and data efficient information processing with distinct learning mechanisms. Yet a core challenge to utilizing BNN for neurocomputation is determining the optimal encoding and decoding mechanisms between the traditional silicon computing interface and the living biology. Here, we propose an Embodied Neurocomputation framework as a systems-level approach to this multi-variable optimization encoding/decoding problem. We operationalize this approach through the first large-scale parameter optimization of encoding configurations for a BNN agent performing closed-loop navigation along an odor-style gradient in a simulated grid-world. Despite the relative simplicity of the task, the biological interactions gave rise to a massive multi-combinatorial search space for optimal parameters. By considering how the components of the system are interconnected and parameterized, we evaluated approximately 1,300 parameter combinations, over 4,000 hours of real-time agent-environment interactions, to identify 12 configurations that consistently demonstrated learning across multiple episodes. These configurations achieved significantly higher task performances than optimized silicon-based DQN agents under the same interaction budget. These findings represent an initial step toward robust and scalable goal-oriented learning using BNNs. Our framework establishes a foundation for applying task-driven neurocomputing and supports the development of field-wide benchmarks. In the long term, this work supports the development of hybrid bio-silicon architectures capable of efficient, adaptive and real-time computation, including the potential for robotic control applications.
MERGE: Guided Vision-Language Models for Multi-Actor Event Reasoning and Grounding in Human-Robot Interaction
Mar 19, 2026We introduce MERGE, a system for situational grounding of actors, objects, and events in dynamic human-robot group interactions. Effective collaboration in such settings requires consistent situational awareness, built on persistent representations of people and objects and an episodic abstraction of events. MERGE achieves this by uniquely identifying physical instances of actors (humans or robots) and objects and structuring them into actor-action-object relations, ensuring temporal consistency across interactions. Central to MERGE is the integration of Vision-Language Models (VLMs) guided with a perception pipeline: a lightweight streaming module continuously processes visual input to detect changes and selectively invokes the VLM only when necessary. This decoupled design preserves the reasoning power and zero-shot generalization of VLMs while improving efficiency, avoiding both the high monetary cost and the latency of frame-by-frame captioning that leads to fragmented and delayed outputs. To address the absence of suitable benchmarks for multi-actor collaboration, we introduce the GROUND dataset, which offers fine-grained situational annotations of multi-person and human-robot interactions. On this dataset, our approach improves the average grounding score by a factor of 2 compared to the performance of VLM-only baselines - including GPT-4o, GPT-5 and Gemini 2.5 Flash - while also reducing run-time by a factor of 4. The code and data are available at www.github.com/HRI-EU/merge.
Local Pairwise Distance Matching for Backpropagation-Free Reinforcement Learning
Jul 15, 2025Training neural networks with reinforcement learning (RL) typically relies on backpropagation (BP), necessitating storage of activations from the forward pass for subsequent backward updates. Furthermore, backpropagating error signals through multiple layers often leads to vanishing or exploding gradients, which can degrade learning performance and stability. We propose a novel approach that trains each layer of the neural network using local signals during the forward pass in RL settings. Our approach introduces local, layer-wise losses leveraging the principle of matching pairwise distances from multi-dimensional scaling, enhanced with optional reward-driven guidance. This method allows each hidden layer to be trained using local signals computed during forward propagation, thus eliminating the need for backward passes and storing intermediate activations. Our experiments, conducted with policy gradient methods across common RL benchmarks, demonstrate that this backpropagation-free method achieves competitive performance compared to their classical BP-based counterpart. Additionally, the proposed method enhances stability and consistency within and across runs, and improves performance especially in challenging environments.
Neuro-Symbolic Imitation Learning: Discovering Symbolic Abstractions for Skill Learning
Mar 27, 2025Imitation learning is a popular method for teaching robots new behaviors. However, most existing methods focus on teaching short, isolated skills rather than long, multi-step tasks. To bridge this gap, imitation learning algorithms must not only learn individual skills but also an abstract understanding of how to sequence these skills to perform extended tasks effectively. This paper addresses this challenge by proposing a neuro-symbolic imitation learning framework. Using task demonstrations, the system first learns a symbolic representation that abstracts the low-level state-action space. The learned representation decomposes a task into easier subtasks and allows the system to leverage symbolic planning to generate abstract plans. Subsequently, the system utilizes this task decomposition to learn a set of neural skills capable of refining abstract plans into actionable robot commands. Experimental results in three simulated robotic environments demonstrate that, compared to baselines, our neuro-symbolic approach increases data efficiency, improves generalization capabilities, and facilitates interpretability.
Tulip Agent -- Enabling LLM-Based Agents to Solve Tasks Using Large Tool Libraries
Jul 31, 2024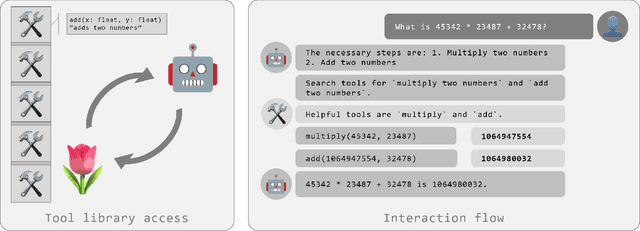
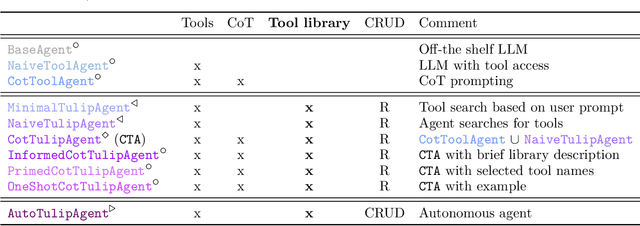
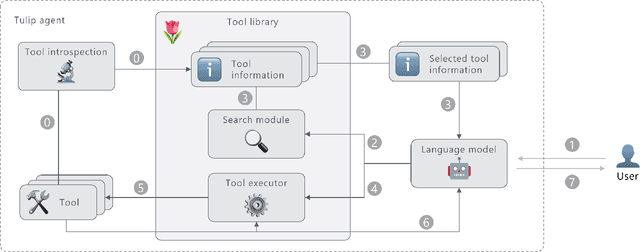
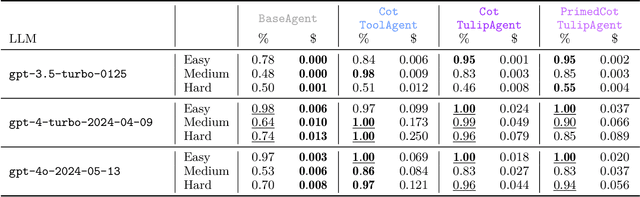
We introduce tulip agent, an architecture for autonomous LLM-based agents with Create, Read, Update, and Delete access to a tool library containing a potentially large number of tools. In contrast to state-of-the-art implementations, tulip agent does not encode the descriptions of all available tools in the system prompt, which counts against the model's context window, or embed the entire prompt for retrieving suitable tools. Instead, the tulip agent can recursively search for suitable tools in its extensible tool library, implemented exemplarily as a vector store. The tulip agent architecture significantly reduces inference costs, allows using even large tool libraries, and enables the agent to adapt and extend its set of tools. We evaluate the architecture with several ablation studies in a mathematics context and demonstrate its generalizability with an application to robotics. A reference implementation and the benchmark are available at github.com/HRI-EU/tulip_agent.
Efficient Symbolic Planning with Views
May 06, 2024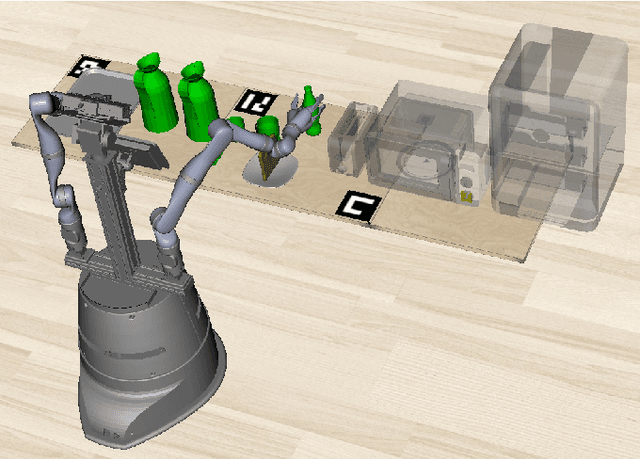

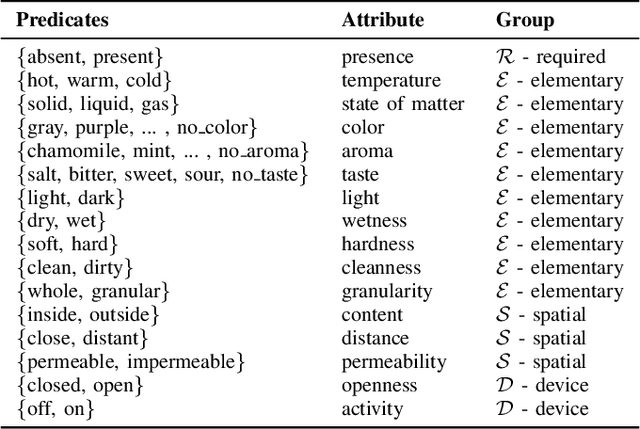
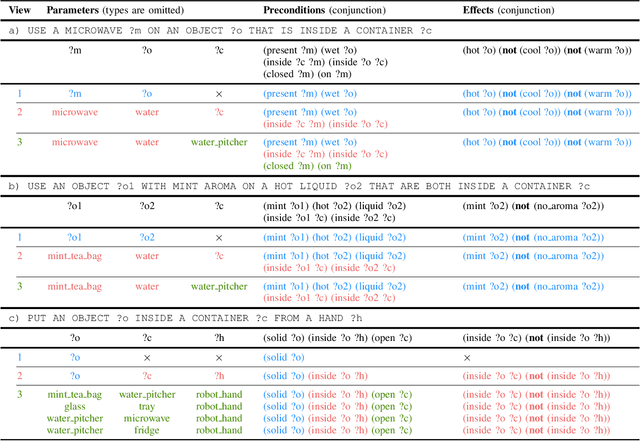
Robotic planning systems model spatial relations in detail as these are needed for manipulation tasks. In contrast to this, other physical attributes of objects and the effect of devices are usually oversimplified and expressed by abstract compound attributes. This limits the ability of planners to find alternative solutions. We propose to break these compound attributes down into a shared set of elementary attributes. This strongly facilitates generalization between different tasks and environments and thus helps to find innovative solutions. On the down-side, this generalization comes with an increased complexity of the solution space. Therefore, as the main contribution of the paper, we propose a method that splits the planning problem into a sequence of views, where in each view only an increasing subset of attributes is considered. We show that this view-based strategy offers a good compromise between planning speed and quality of the found plan, and discuss its general applicability and limitations.
To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group Interactions
Mar 19, 2024How can a robot provide unobtrusive physical support within a group of humans? We present Attentive Support, a novel interaction concept for robots to support a group of humans. It combines scene perception, dialogue acquisition, situation understanding, and behavior generation with the common-sense reasoning capabilities of Large Language Models (LLMs). In addition to following user instructions, Attentive Support is capable of deciding when and how to support the humans, and when to remain silent to not disturb the group. With a diverse set of scenarios, we show and evaluate the robot's attentive behavior, which supports and helps the humans when required, while not disturbing if no help is needed.
Large Language Models for Multi-Modal Human-Robot Interaction
Jan 26, 2024



This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating "atomics" for actions and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers' defined guidelines. Simultaneously, it coordinates the robot's lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system's potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach.
CoPAL: Corrective Planning of Robot Actions with Large Language Models
Oct 11, 2023In the pursuit of fully autonomous robotic systems capable of taking over tasks traditionally performed by humans, the complexity of open-world environments poses a considerable challenge. Addressing this imperative, this study contributes to the field of Large Language Models (LLMs) applied to task and motion planning for robots. We propose a system architecture that orchestrates a seamless interplay between multiple cognitive levels, encompassing reasoning, planning, and motion generation. At its core lies a novel replanning strategy that handles physically grounded, logical, and semantic errors in the generated plans. We demonstrate the efficacy of the proposed feedback architecture, particularly its impact on executability, correctness, and time complexity via empirical evaluation in the context of a simulation and two intricate real-world scenarios: blocks world, barman and pizza preparation.
Learning Type-Generalized Actions for Symbolic Planning
Aug 09, 2023



Symbolic planning is a powerful technique to solve complex tasks that require long sequences of actions and can equip an intelligent agent with complex behavior. The downside of this approach is the necessity for suitable symbolic representations describing the state of the environment as well as the actions that can change it. Traditionally such representations are carefully hand-designed by experts for distinct problem domains, which limits their transferability to different problems and environment complexities. In this paper, we propose a novel concept to generalize symbolic actions using a given entity hierarchy and observed similar behavior. In a simulated grid-based kitchen environment, we show that type-generalized actions can be learned from few observations and generalize to novel situations. Incorporating an additional on-the-fly generalization mechanism during planning, unseen task combinations, involving longer sequences, novel entities and unexpected environment behavior, can be solved.