 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERGE: Guided Vision-Language Models for Multi-Actor Event Reasoning and Grounding in Human-Robot Interaction
Mar 19, 2026We introduce MERGE, a system for situational grounding of actors, objects, and events in dynamic human-robot group interactions. Effective collaboration in such settings requires consistent situational awareness, built on persistent representations of people and objects and an episodic abstraction of events. MERGE achieves this by uniquely identifying physical instances of actors (humans or robots) and objects and structuring them into actor-action-object relations, ensuring temporal consistency across interactions. Central to MERGE is the integration of Vision-Language Models (VLMs) guided with a perception pipeline: a lightweight streaming module continuously processes visual input to detect changes and selectively invokes the VLM only when necessary. This decoupled design preserves the reasoning power and zero-shot generalization of VLMs while improving efficiency, avoiding both the high monetary cost and the latency of frame-by-frame captioning that leads to fragmented and delayed outputs. To address the absence of suitable benchmarks for multi-actor collaboration, we introduce the GROUND dataset, which offers fine-grained situational annotations of multi-person and human-robot interactions. On this dataset, our approach improves the average grounding score by a factor of 2 compared to the performance of VLM-only baselines - including GPT-4o, GPT-5 and Gemini 2.5 Flash - while also reducing run-time by a factor of 4. The code and data are available at www.github.com/HRI-EU/merge.
XR$^3$: An Extended Reality Platform for Social-Physical Human-Robot Interaction
Jan 23, 2026Social-physical human-robot interaction (spHRI) is difficult to study: building and programming robots that integrate multiple interaction modalities is costly and slow, while VR-based prototypes often lack physical contact, breaking users' visuo-tactile expectations. We present XR$^3$, a co-located dual-VR-headset platform for HRI research in which an attendee and a hidden operator share the same physical space while experiencing different virtual embodiments. The attendee sees an expressive virtual robot that interacts face-to-face in a shared virtual environment. In real time, the robot's upper-body motion, head and gaze behavior, and facial expressions are mapped from the operator's tracked limbs and face signals. Because the operator is co-present and calibrated in the same coordinate frame, the operator can also touch the attendee, enabling perceived robot touch synchronized with the robot's visible hands. Finger and hand motion is mapped to the robot avatar using inverse kinematics to support precise contact. Beyond motion retargeting, XR$^3$ supports social retargeting of multiple nonverbal cues that can be experimentally varied while keeping physical interaction constant. We detail the system design and calibration, and demonstrate the platform in a touch-based Wizard-of-Oz study, lowering the barrier to prototyping and evaluating embodied, contact-based robot behaviors.
VR$^2$: A Co-Located Dual-Headset Platform for Touch-Enabled Human-Robot Interaction Research
Jan 21, 2026Social-physical human-robot interaction (HRI) is difficult to study: building and programming robots integrating multiple interaction modalities is costly and slow, while VR-based prototypes often lack physical contact capabilities, breaking the visuo-tactile expectations of the user. We present VR2VR, a co-located dual-VR-headset platform for HRI research in which a participant and a hidden operator share the same physical space while experiencing different virtual embodiments. The participant sees an expressive virtual robot that interacts face-to-face in a shared virtual environment. In real time, the robot's upper-body movements, head and gaze behaviors, and facial expressions are mapped from the operator's tracked limbs and face signals. Since the operator is physically co-present and calibrated into the same coordinate frame, the operator can also touch the participant, enabling the participant to perceive robot touch synchronized with the visual perception of the robot's hands on their hands: the operator's finger and hand motion is mapped to the robot avatar using inverse kinematics to support precise contact. Beyond faithful motion retargeting for limb control, our VR2VR system supports social retargeting of multiple nonverbal cues, which can be experimentally varied and investigated while keeping the physical interaction constant. We detail the system design, calibration workflow, and safety considerations, and demonstrate how the platform can be used for experimentation and data collection in a touch-based Wizard-of-Oz HRI study, thus illustrating how VR2VR lowers barriers for rapidly prototyping and rigorously evaluating embodied, contact-based robot behaviors.
Learning Robot Manipulation from Audio World Models
Dec 09, 2025
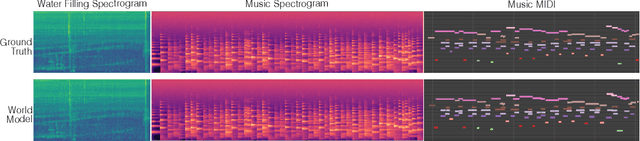
World models have demonstrated impressive performance on robotic learning tasks. Many such tasks inherently demand multimodal reasoning; for example, filling a bottle with water will lead to visual information alone being ambiguous or incomplete, thereby requiring reasoning over the temporal evolution of audio, accounting for its underlying physical properties and pitch patterns. In this paper, we propose a generative latent flow matching model to anticipate future audio observations, enabling the system to reason about long-term consequences when integrated into a robot policy. We demonstrate the superior capabilities of our system through two manipulation tasks that require perceiving in-the-wild audio or music signals, compared to methods without future lookahead. We further emphasize that successful robot action learning for these tasks relies not merely on multi-modal input, but critically on the accurate prediction of future audio states that embody intrinsic rhythmic patterns.
Bimanual Robot-Assisted Dressing: A Spherical Coordinate-Based Strategy for Tight-Fitting Garments
Aug 17, 2025Robot-assisted dressing is a popular but challenging topic in the field of robotic manipulation, offering significant potential to improve the quality of life for individuals with mobility limitations. Currently, the majority of research on robot-assisted dressing focuses on how to put on loose-fitting clothing, with little attention paid to tight garments. For the former, since the armscye is larger, a single robotic arm can usually complete the dressing task successfully. However, for the latter, dressing with a single robotic arm often fails due to the narrower armscye and the property of diminishing rigidity in the armscye, which eventually causes the armscye to get stuck. This paper proposes a bimanual dressing strategy suitable for dressing tight-fitting clothing. To facilitate the encoding of dressing trajectories that adapt to different human arm postures, a spherical coordinate system for dressing is established. We uses the azimuthal angle of the spherical coordinate system as a task-relevant feature for bimanual manipulation. Based on this new coordinate, we employ Gaussian Mixture Model (GMM) and Gaussian Mixture Regression (GMR) for imitation learning of bimanual dressing trajectories, generating dressing strategies that adapt to different human arm postures. The effectiveness of the proposed method is validated through various experiments.
Generation of Real-time Robotic Emotional Expressions Learning from Human Demonstration in Mixed Reality
Aug 12, 2025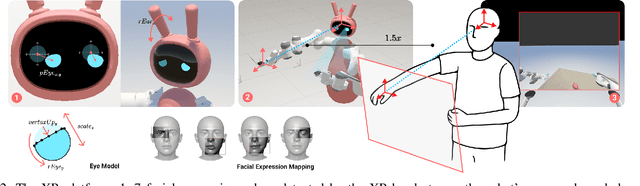
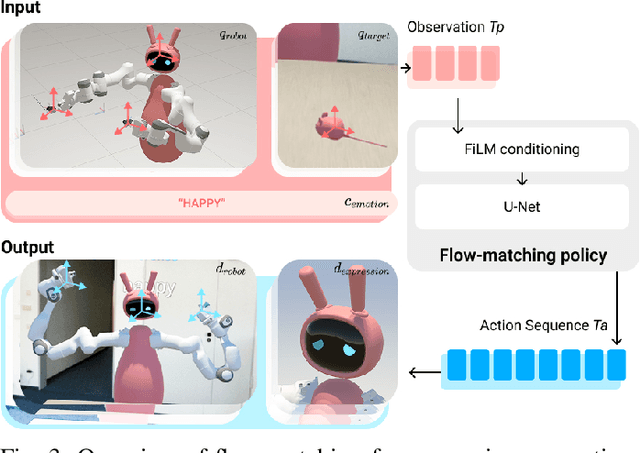
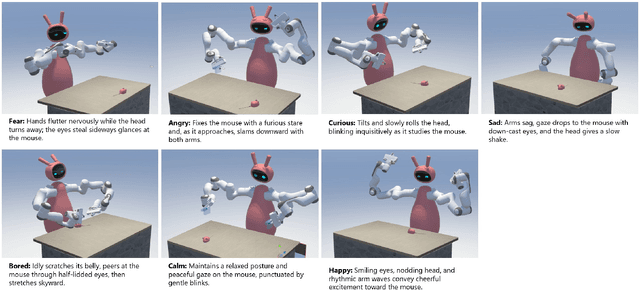
Expressive behaviors in robots are critical for effectively conveying their emotional states during interactions with humans. In this work, we present a framework that autonomously generates realistic and diverse robotic emotional expressions based on expert human demonstrations captured in Mixed Reality (MR). Our system enables experts to teleoperate a virtual robot from a first-person perspective, capturing their facial expressions, head movements, and upper-body gestures, and mapping these behaviors onto corresponding robotic components including eyes, ears, neck, and arms. Leveraging a flow-matching-based generative process, our model learns to produce coherent and varied behaviors in real-time in response to moving objects, conditioned explicitly on given emotional states. A preliminary test validated the effectiveness of our approach for generating autonomous expressions.
Fast Flow-based Visuomotor Policies via Conditional Optimal Transport Couplings
May 02, 2025Diffusion and flow matching policies have recently demonstrated remarkable performance in robotic applications by accurately capturing multimodal robot trajectory distributions. However, their computationally expensive inference, due to the numerical integration of an ODE or SDE, limits their applicability as real-time controllers for robots. We introduce a methodology that utilizes conditional Optimal Transport couplings between noise and samples to enforce straight solutions in the flow ODE for robot action generation tasks. We show that naively coupling noise and samples fails in conditional tasks and propose incorporating condition variables into the coupling process to improve few-step performance. The proposed few-step policy achieves a 4% higher success rate with a 10x speed-up compared to Diffusion Policy on a diverse set of simulation tasks. Moreover, it produces high-quality and diverse action trajectories within 1-2 steps on a set of real-world robot tasks. Our method also retains the same training complexity as Diffusion Policy and vanilla Flow Matching, in contrast to distillation-based approaches.
SemanticScanpath: Combining Gaze and Speech for Situated Human-Robot Interaction Using LLMs
Mar 19, 2025Large Language Models (LLMs) have substantially improved the conversational capabilities of social robots. Nevertheless, for an intuitive and fluent human-robot interaction, robots should be able to ground the conversation by relating ambiguous or underspecified spoken utterances to the current physical situation and to the intents expressed non verbally by the user, for example by using referential gaze. Here we propose a representation integrating speech and gaze to enable LLMs to obtain higher situated awareness and correctly resolve ambiguous requests. Our approach relies on a text-based semantic translation of the scanpath produced by the user along with the verbal requests and demonstrates LLM's capabilities to reason about gaze behavior, robustly ignoring spurious glances or irrelevant objects. We validate the system across multiple tasks and two scenarios, showing its generality and accuracy, and demonstrate its implementation on a robotic platform, closing the loop from request interpretation to execution.
CCDP: Composition of Conditional Diffusion Policies with Guided Sampling
Mar 19, 2025Imitation Learning offers a promising approach to learn directly from data without requiring explicit models, simulations, or detailed task definitions. During inference, actions are sampled from the learned distribution and executed on the robot. However, sampled actions may fail for various reasons, and simply repeating the sampling step until a successful action is obtained can be inefficient. In this work, we propose an enhanced sampling strategy that refines the sampling distribution to avoid previously unsuccessful actions. We demonstrate that by solely utilizing data from successful demonstrations, our method can infer recovery actions without the need for additional exploratory behavior or a high-level controller. Furthermore, we leverage the concept of diffusion model decomposition to break down the primary problem (which may require long-horizon history to manage failures) into multiple smaller, more manageable sub-problems in learning, data collection, and inference, thereby enabling the system to adapt to variable failure counts. Our approach yields a low-level controller that dynamically adjusts its sampling space to improve efficiency when prior samples fall short. We validate our method across several tasks, including door opening with unknown directions, object manipulation, and button-searching scenarios, demonstrating that our approach outperforms traditional baselines.
Affordance-based Robot Manipulation with Flow Matching
Sep 02, 2024



We present a framework for assistive robot manipulation, which focuses on two fundamental challenges: first, efficiently adapting large-scale models to downstream scene affordance understanding tasks, especially in daily living scenarios where gathering multi-task data involving humans requires strenuous effort; second, effectively learning robot trajectories by grounding the visual affordance model. We tackle the first challenge by employing a parameter-efficient prompt tuning method that prepends learnable text prompts to the frozen vision model to predict manipulation affordances in multi-task scenarios. Then we propose to learn robot trajectories guided by affordances in a supervised Flow Matching method. Flow matching represents a robot visuomotor policy as a conditional process of flowing random waypoints to desired robot trajectories. Finally, we introduce a real-world dataset with 10 tasks across Activities of Daily Living to test our framework. Our extensive evaluation highlights that the proposed prompt tuning method for learning manipulation affordance with language prompter achieves competitive performance and even outperforms other finetuning protocols across data scales, while satisfying parameter efficiency. Learning multi-task robot trajectories with a single flow matching policy also leads to consistently better performance than alternative behavior cloning methods, especially given multimodal robot action distributions. Our framework seamlessly unifies affordance model learning and trajectory generation with flow matching for robot manipulation.