 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Help or Not to Help: LLM-based Attentive Support for Human-Robot Group Interactions
Mar 19, 2024How can a robot provide unobtrusive physical support within a group of humans? We present Attentive Support, a novel interaction concept for robots to support a group of humans. It combines scene perception, dialogue acquisition, situation understanding, and behavior generation with the common-sense reasoning capabilities of Large Language Models (LLMs). In addition to following user instructions, Attentive Support is capable of deciding when and how to support the humans, and when to remain silent to not disturb the group. With a diverse set of scenarios, we show and evaluate the robot's attentive behavior, which supports and helps the humans when required, while not disturbing if no help is needed.
Large Language Models for Multi-Modal Human-Robot Interaction
Jan 26, 2024



This paper presents an innovative large language model (LLM)-based robotic system for enhancing multi-modal human-robot interaction (HRI). Traditional HRI systems relied on complex designs for intent estimation, reasoning, and behavior generation, which were resource-intensive. In contrast, our system empowers researchers and practitioners to regulate robot behavior through three key aspects: providing high-level linguistic guidance, creating "atomics" for actions and expressions the robot can use, and offering a set of examples. Implemented on a physical robot, it demonstrates proficiency in adapting to multi-modal inputs and determining the appropriate manner of action to assist humans with its arms, following researchers' defined guidelines. Simultaneously, it coordinates the robot's lid, neck, and ear movements with speech output to produce dynamic, multi-modal expressions. This showcases the system's potential to revolutionize HRI by shifting from conventional, manual state-and-flow design methods to an intuitive, guidance-based, and example-driven approach.
CoPAL: Corrective Planning of Robot Actions with Large Language Models
Oct 11, 2023In the pursuit of fully autonomous robotic systems capable of taking over tasks traditionally performed by humans, the complexity of open-world environments poses a considerable challenge. Addressing this imperative, this study contributes to the field of Large Language Models (LLMs) applied to task and motion planning for robots. We propose a system architecture that orchestrates a seamless interplay between multiple cognitive levels, encompassing reasoning, planning, and motion generation. At its core lies a novel replanning strategy that handles physically grounded, logical, and semantic errors in the generated plans. We demonstrate the efficacy of the proposed feedback architecture, particularly its impact on executability, correctness, and time complexity via empirical evaluation in the context of a simulation and two intricate real-world scenarios: blocks world, barman and pizza preparation.
A Glimpse in ChatGPT Capabilities and its impact for AI research
May 10, 2023Large language models (LLMs) have recently become a popular topic in the field of Artificial Intelligence (AI) research, with companies such as Google, Amazon, Facebook, Amazon, Tesla, and Apple (GAFA) investing heavily in their development. These models are trained on massive amounts of data and can be used for a wide range of tasks, including language translation, text generation, and question answering. However, the computational resources required to train and run these models are substantial, and the cost of hardware and electricity can be prohibitive for research labs that do not have the funding and resources of the GAFA. In this paper, we will examine the impact of LLMs on AI research. The pace at which such models are generated as well as the range of domains covered is an indication of the trend which not only the public but also the scientific community is currently experiencing. We give some examples on how to use such models in research by focusing on GPT3.5/ChatGPT3.4 and ChatGPT4 at the current state and show that such a range of capabilities in a single system is a strong sign of approaching general intelligence. Innovations integrating such models will also expand along the maturation of such AI systems and exhibit unforeseeable applications that will have important impacts on several aspects of our societies.
Designing Interaction for Multi-agent Cooperative System in an Office Environment
Feb 15, 2020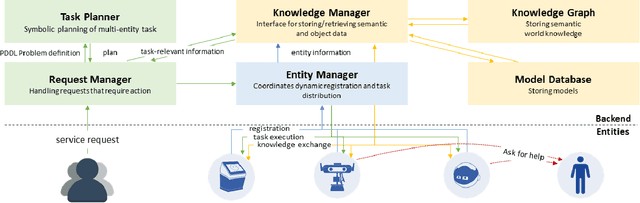
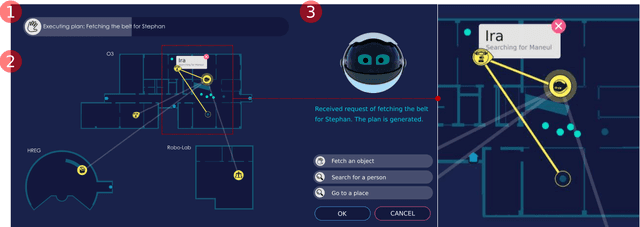


Future intelligent system will involve very various types of artificial agents, such as mobile robots, smart home infrastructure or personal devices, which share data and collaborate with each other to execute certain tasks.Designing an efficient human-machine interface, which can support users to express needs to the system, supervise the collaboration progress of different entities and evaluate the result, will be challengeable. This paper presents the design and implementation of the human-machine interface of Intelligent Cyber-Physical system (ICPS),which is a multi-entity coordination system of robots and other smart devices in a working environment. ICPS gathers sensory data from entities and then receives users' command, then optimizes plans to utilize the capability of different entities to serve people. Using multi-model interaction methods, e.g. graphical interfaces, speech interaction, gestures and facial expressions, ICPS is able to receive inputs from users through different entities, keep users aware of the progress and accomplish the task efficiently