 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticScanpath: Combining Gaze and Speech for Situated Human-Robot Interaction Using LLMs
Mar 19, 2025Large Language Models (LLMs) have substantially improved the conversational capabilities of social robots. Nevertheless, for an intuitive and fluent human-robot interaction, robots should be able to ground the conversation by relating ambiguous or underspecified spoken utterances to the current physical situation and to the intents expressed non verbally by the user, for example by using referential gaze. Here we propose a representation integrating speech and gaze to enable LLMs to obtain higher situated awareness and correctly resolve ambiguous requests. Our approach relies on a text-based semantic translation of the scanpath produced by the user along with the verbal requests and demonstrates LLM's capabilities to reason about gaze behavior, robustly ignoring spurious glances or irrelevant objects. We validate the system across multiple tasks and two scenarios, showing its generality and accuracy, and demonstrate its implementation on a robotic platform, closing the loop from request interpretation to execution.
To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group Interactions
Mar 19, 2024How can a robot provide unobtrusive physical support within a group of humans? We present Attentive Support, a novel interaction concept for robots to support a group of humans. It combines scene perception, dialogue acquisition, situation understanding, and behavior generation with the common-sense reasoning capabilities of Large Language Models (LLMs). In addition to following user instructions, Attentive Support is capable of deciding when and how to support the humans, and when to remain silent to not disturb the group. With a diverse set of scenarios, we show and evaluate the robot's attentive behavior, which supports and helps the humans when required, while not disturbing if no help is needed.
CoPAL: Corrective Planning of Robot Actions with Large Language Models
Oct 11, 2023In the pursuit of fully autonomous robotic systems capable of taking over tasks traditionally performed by humans, the complexity of open-world environments poses a considerable challenge. Addressing this imperative, this study contributes to the field of Large Language Models (LLMs) applied to task and motion planning for robots. We propose a system architecture that orchestrates a seamless interplay between multiple cognitive levels, encompassing reasoning, planning, and motion generation. At its core lies a novel replanning strategy that handles physically grounded, logical, and semantic errors in the generated plans. We demonstrate the efficacy of the proposed feedback architecture, particularly its impact on executability, correctness, and time complexity via empirical evaluation in the context of a simulation and two intricate real-world scenarios: blocks world, barman and pizza preparation.
Communicating Robot's Intentions while Assisting Users via Augmented Reality
Aug 21, 2023
This paper explores the challenges faced by assistive robots in effectively cooperating with humans, requiring them to anticipate human behavior, predict their actions' impact, and generate understandable robot actions. The study focuses on a use-case involving a user with limited mobility needing assistance with pouring a beverage, where tasks like unscrewing a cap or reaching for objects demand coordinated support from the robot. Yet, anticipating the robot's intentions can be challenging for the user, which can hinder effective collaboration. To address this issue, we propose an innovative solution that utilizes Augmented Reality (AR) to communicate the robot's intentions and expected movements to the user, fostering a seamless and intuitive interaction.
Gaze-based intention estimation: principles, methodologies, and applications in HRI
Feb 09, 2023Intention prediction has become a relevant field of research in Human-Machine and Human-Robot Interaction. Indeed, any artificial system (co)-operating with and along humans, designed to assist and coordinate its actions with a human partner, would benefit from first inferring the human's current intention. To spare the user the cognitive burden of explicitly uttering their goals, this inference relies mostly on behavioral cues deemed indicative of the current action. It has been long known that eye movements are highly anticipatory of the single steps unfolding during a task, hence they can serve as a very early and reliable behavioural cue for intention recognition. This review aims to draw a line between insights in the psychological literature on visuomotor control and relevant applications of gaze-based intention recognition in technical domains, with a focus on teleoperated and assistive robotic systems. Starting from the cognitive principles underlying the relationship between intentions, eye movements, and action, the use of eye tracking and gaze-based models for intent recognition in Human-Robot Interaction is considered, with prevalent methodologies and their diverse applications. Finally, special consideration is given to relevant human factors issues and current limitations to be factored in when designing such systems.
Intention estimation from gaze and motion features for human-robot shared-control object manipulation
Aug 18, 2022
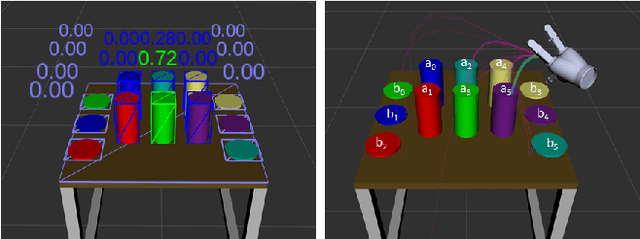
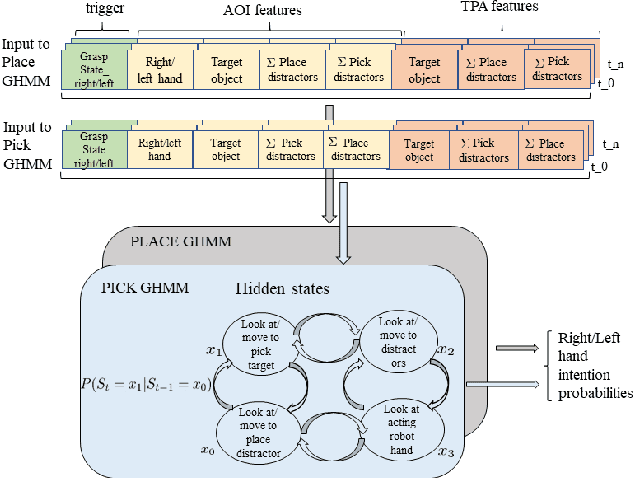
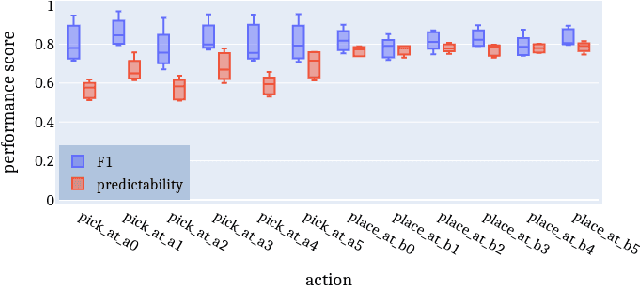
Shared control can help in teleoperated object manipulation by assisting with the execution of the user's intention. To this end, robust and prompt intention estimation is needed, which relies on behavioral observations. Here, an intention estimation framework is presented, which uses natural gaze and motion features to predict the current action and the target object. The system is trained and tested in a simulated environment with pick and place sequences produced in a relatively cluttered scene and with both hands, with possible hand-over to the other hand. Validation is conducted across different users and hands, achieving good accuracy and earliness of prediction. An analysis of the predictive power of single features shows the predominance of the grasping trigger and the gaze features in the early identification of the current action. In the current framework, the same probabilistic model can be used for the two hands working in parallel and independently, while a rule-based model is proposed to identify the resulting bimanual action. Finally, limitations and perspectives of this approach to more complex, full-bimanual manipulations are discussed.