 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human-Robot Teaching by Quantifying and Reducing Mental Model Mismatch
Jan 08, 2025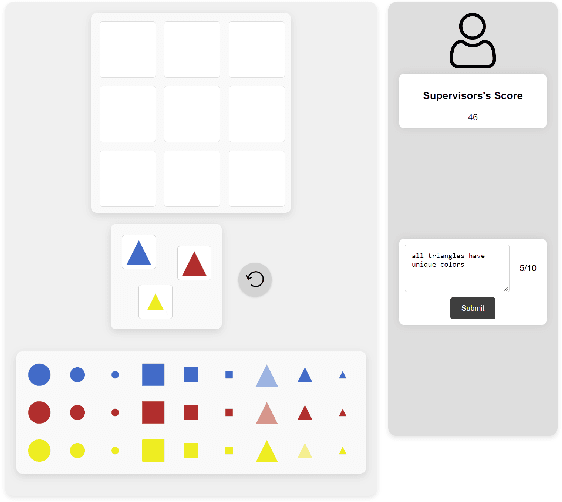
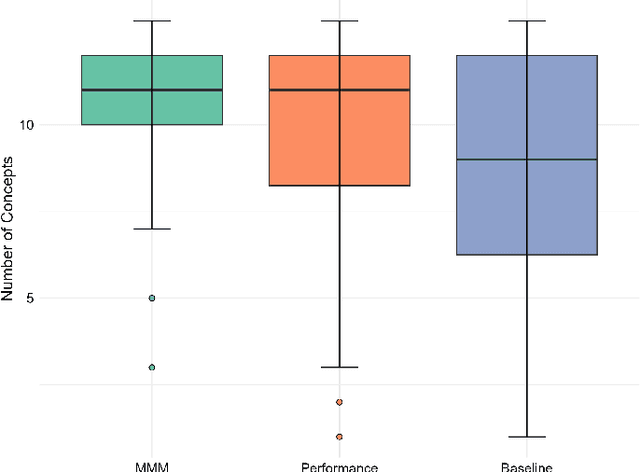
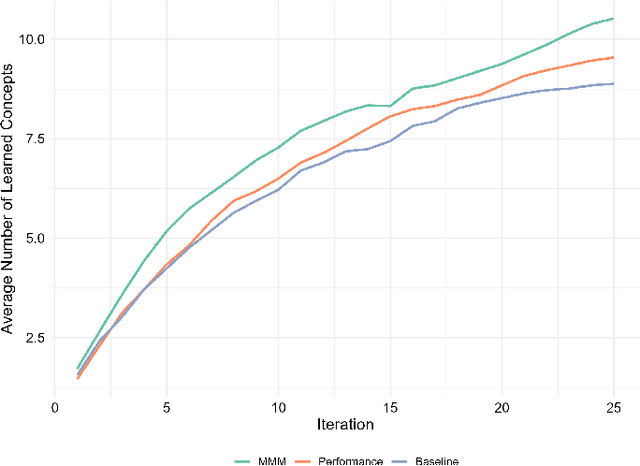
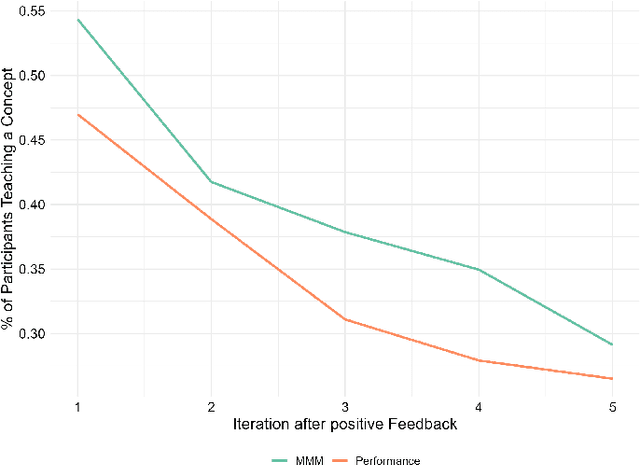
The rapid development of artificial intelligence and robotics has had a significant impact on our lives, with intelligent systems increasingly performing tasks traditionally performed by humans. Efficient knowledge transfer requires matching the mental model of the human teacher with the capabilities of the robot learner. This paper introduces the Mental Model Mismatch (MMM) Score, a feedback mechanism designed to quantify and reduce mismatches by aligning human teaching behavior with robot learning behavior. Using Large Language Models (LLMs), we analyze teacher intentions in natural language to generate adaptive feedback. A study with 150 participants teaching a virtual robot to solve a puzzle game shows that intention-based feedback significantly outperforms traditional performance-based feedback or no feedback. The results suggest that intention-based feedback improves instructional outcomes, improves understanding of the robot's learning process and reduces misconceptions. This research addresses a critical gap in human-robot interaction (HRI) by providing a method to quantify and mitigate discrepancies between human mental models and robot capabilities, with the goal of improving robot learning and human teaching effectiveness.
The Illusion of Competence: Evaluating the Effect of Explanations on Users' Mental Models of Visual Question Answering Systems
Jun 27, 2024



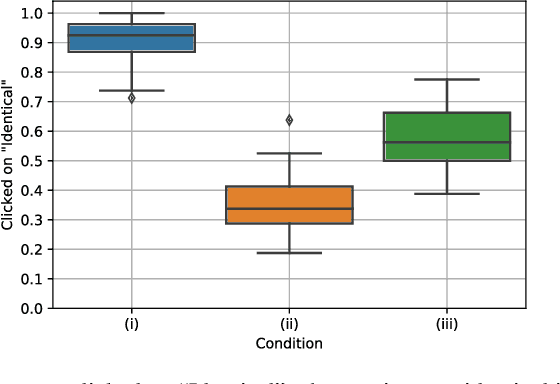
We examine how users perceive the limitations of an AI system when it encounters a task that it cannot perform perfectly and whether providing explanations alongside its answers aids users in constructing an appropriate mental model of the system's capabilities and limitations. We employ a visual question answer and explanation task where we control the AI system's limitations by manipulating the visual inputs: during inference, the system either processes full-color or grayscale images. Our goal is to determine whether participants can perceive the limitations of the system. We hypothesize that explanations will make limited AI capabilities more transparent to users. However, our results show that explanations do not have this effect. Instead of allowing users to more accurately assess the limitations of the AI system, explanations generally increase users' perceptions of the system's competence - regardless of its actual performance.
To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group Interactions
Mar 19, 2024How can a robot provide unobtrusive physical support within a group of humans? We present Attentive Support, a novel interaction concept for robots to support a group of humans. It combines scene perception, dialogue acquisition, situation understanding, and behavior generation with the common-sense reasoning capabilities of Large Language Models (LLMs). In addition to following user instructions, Attentive Support is capable of deciding when and how to support the humans, and when to remain silent to not disturb the group. With a diverse set of scenarios, we show and evaluate the robot's attentive behavior, which supports and helps the humans when required, while not disturbing if no help is needed.
What you need to know about a learning robot: Identifying the enabling architecture of complex systems
Nov 24, 2023Nowadays, we are dealing more and more with robots and AI in everyday life. However, their behavior is not always apparent to most lay users, especially in error situations. As a result, there can be misconceptions about the behavior of the technologies in use. This, in turn, can lead to misuse and rejection by users. Explanation, for example, through transparency, can address these misconceptions. However, it would be confusing and overwhelming for users if the entire software or hardware was explained. Therefore, this paper looks at the 'enabling' architecture. It describes those aspects of a robotic system that might need to be explained to enable someone to use the technology effectively. Furthermore, this paper is concerned with the 'explanandum', which is the corresponding misunderstanding or missing concepts of the enabling architecture that needs to be clarified. We have thus developed and present an approach for determining this 'enabling' architecture and the resulting 'explanandum' of complex technologies.
Addressing Data Scarcity in Multimodal User State Recognition by Combining Semi-Supervised and Supervised Learning
Feb 08, 2022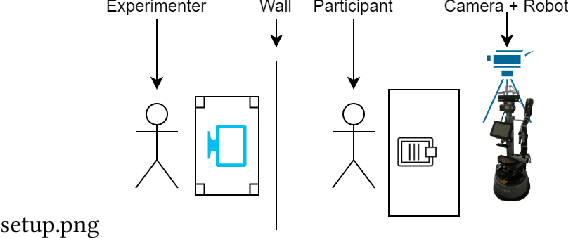
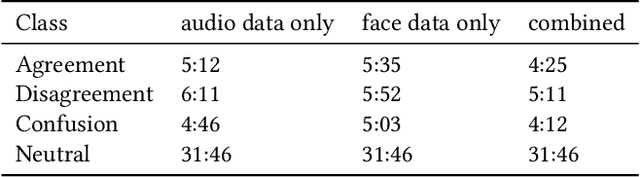
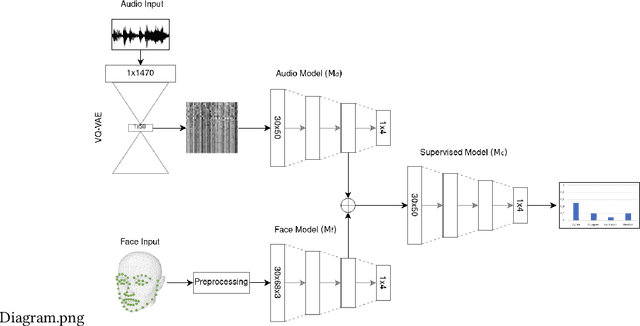
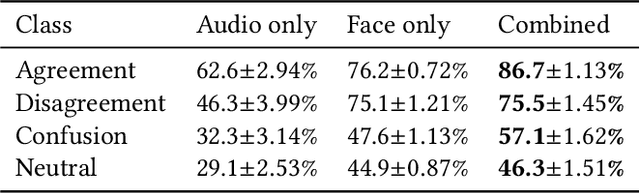
Detecting mental states of human users is crucial for the development of cooperative and intelligent robots, as it enables the robot to understand the user's intentions and desires. Despite their importance, it is difficult to obtain a large amount of high quality data for training automatic recognition algorithms as the time and effort required to collect and label such data is prohibitively high. In this paper we present a multimodal machine learning approach for detecting dis-/agreement and confusion states in a human-robot interaction environment, using just a small amount of manually annotated data. We collect a data set by conducting a human-robot interaction study and develop a novel preprocessing pipeline for our machine learning approach. By combining semi-supervised and supervised architectures, we are able to achieve an average F1-score of 81.1\% for dis-/agreement detection with a small amount of labeled data and a large unlabeled data set, while simultaneously increasing the robustness of the model compared to the supervised approach.
Intuitiveness in Active Teaching
Dec 25, 2020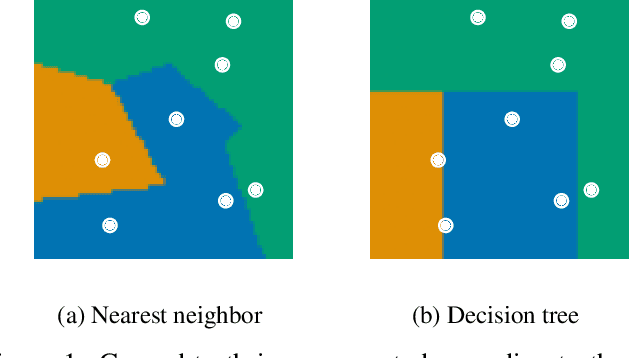
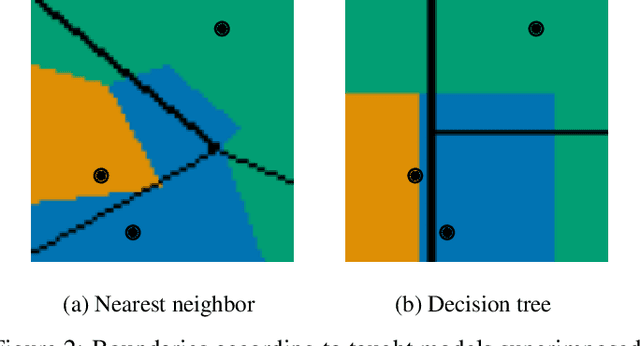
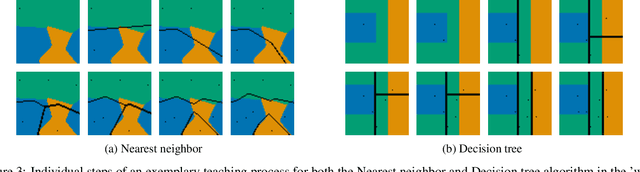
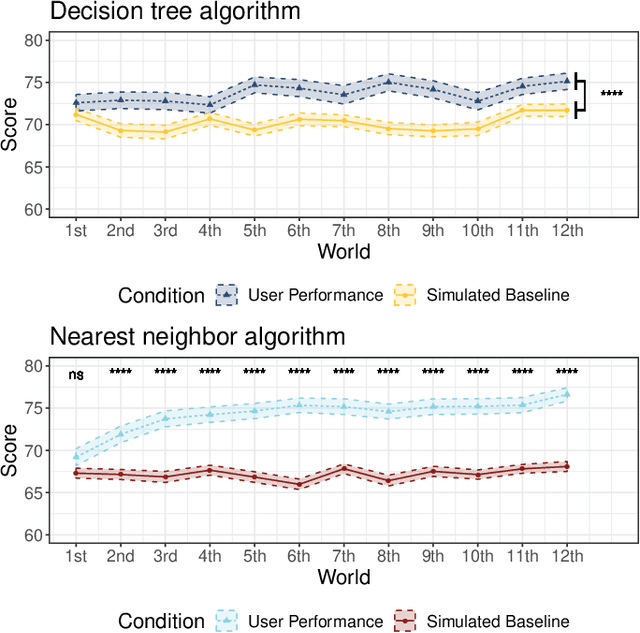
Machine learning is a double-edged sword: it gives rise to astonishing results in automated systems, but at the cost of tremendously large data requirements. This makes many successful algorithms from machine learning unsuitable for human-machine interaction, where the machine must learn from a small number of training samples that can be provided by a user within a reasonable time frame. Fortunately, the user can tailor the training data they create to be as useful as possible, severely limiting its necessary size -- as long as they know about the machine's requirements and limitations. Of course, acquiring this knowledge can in turn be cumbersome and costly. This raises the question how easy machine learning algorithms are to interact with. In this work we address this issue by analyzing the intuitiveness of certain algorithms when they are actively taught by users. After developing a theoretical framework of intuitiveness as a property of algorithms, we present and discuss the results of a large-scale user study into the performance and teaching strategies of 800 users interacting with prominent machine learning algorithms. Via this extensive examination we offer a systematic method to judge the efficacy of human-machine interactions and thus, to scrutinize how accessible, understandable, and fair, a system is.
Locally Adaptive Nearest Neighbors
Nov 08, 2020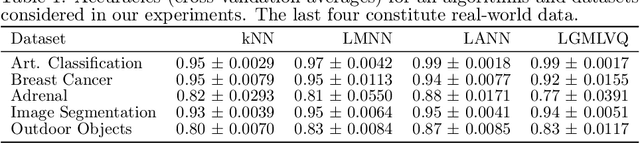

When training automated systems, it has been shown to be beneficial to adapt the representation of data by learning a problem-specific metric. This metric is global. We extend this idea and, for the widely used family of k nearest neighbors algorithms, develop a method that allows learning locally adaptive metrics. To demonstrate important aspects of how our approach works, we conduct a number of experiments on synthetic data sets, and we show its usefulness on real-world benchmark data sets.
Recovering Localized Adversarial Attacks
Oct 21, 2019
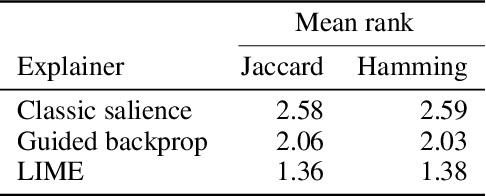

Deep convolutional neural networks have achieved great successes over recent years, particularly in the domain of computer vision. They are fast, convenient, and -- thanks to mature frameworks -- relatively easy to implement and deploy. However, their reasoning is hidden inside a black box, in spite of a number of proposed approaches that try to provide human-understandable explanations for the predictions of neural networks. It is still a matter of debate which of these explainers are best suited for which situations, and how to quantitatively evaluate and compare them. In this contribution, we focus on the capabilities of explainers for convolutional deep neural networks in an extreme situation: a setting in which humans and networks fundamentally disagree. Deep neural networks are susceptible to adversarial attacks that deliberately modify input samples to mislead a neural network's classification, without affecting how a human observer interprets the input. Our goal with this contribution is to evaluate explainers by investigating whether they can identify adversarially attacked regions of an image. In particular, we quantitatively and qualitatively investigate the capability of three popular explainers of classifications -- classic salience, guided backpropagation, and LIME -- with respect to their ability to identify regions of attack as the explanatory regions for the (incorrect) prediction in representative examples from image classification. We find that LIME outperforms the other explainers.
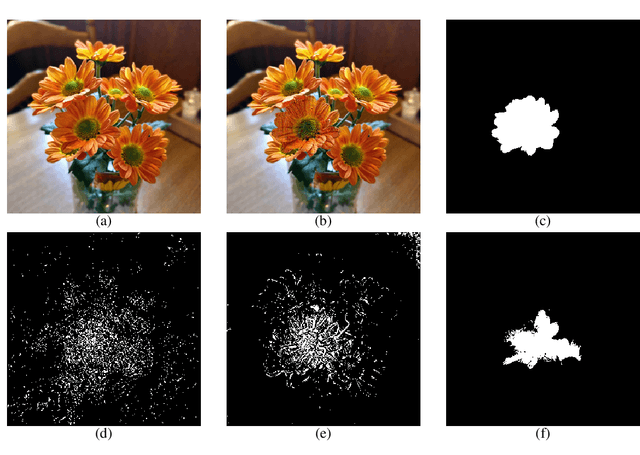
Adversarial attacks hidden in plain sight
Feb 25, 2019


Convolutional neural networks have been used to achieve a string of successes during recent years, but their lack of interpretability remains a serious issue. Adversarial examples are designed to deliberately fool neural networks into making any desired incorrect classification, potentially with very high certainty. We underline the severity of the issue by presenting a technique that allows to hide such adversarial attacks in regions of high complexity, such that they are imperceptible even to an astute observer.
Optimum Reject Options for Prototype-based Classification
Mar 23, 2015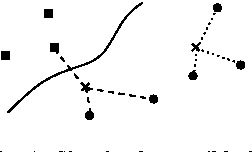
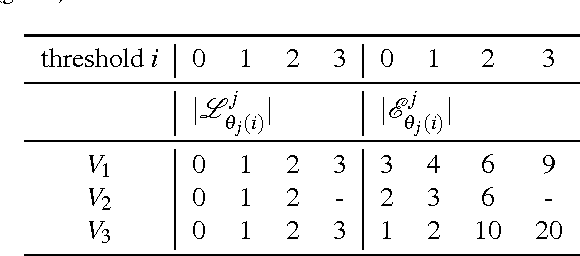
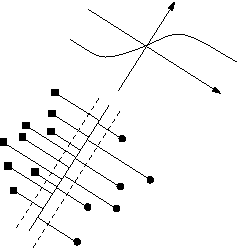
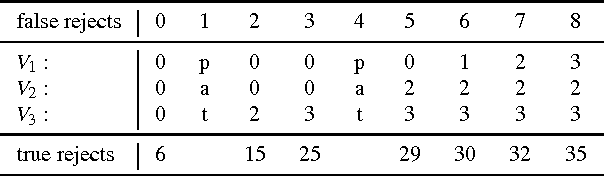
We analyse optimum reject strategies for prototype-based classifiers and real-valued rejection measures, using the distance of a data point to the closest prototype or probabilistic counterparts. We compare reject schemes with global thresholds, and local thresholds for the Voronoi cells of the classifier. For the latter, we develop a polynomial-time algorithm to compute optimum thresholds based on a dynamic programming scheme, and we propose an intuitive linear time, memory efficient approximation thereof with competitive accuracy. Evaluating the performance in various benchmarks, we conclude that local reject options are beneficial in particular for simple prototype-based classifiers, while the improvement is less pronounced for advanced models. For the latter, an accuracy-reject curve which is comparable to support vector machine classifiers with state of the art reject options can be reached.