 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAQ-GT: a Temporally Aligned and Quantized GRU-Transformer for Co-Speech Gesture Synthesis
May 08, 2023The generation of realistic and contextually relevant co-speech gestures is a challenging yet increasingly important task in the creation of multimodal artificial agents. Prior methods focused on learning a direct correspondence between co-speech gesture representations and produced motions, which created seemingly natural but often unconvincing gestures during human assessment. We present an approach to pre-train partial gesture sequences using a generative adversarial network with a quantization pipeline. The resulting codebook vectors serve as both input and output in our framework, forming the basis for the generation and reconstruction of gestures. By learning the mapping of a latent space representation as opposed to directly mapping it to a vector representation, this framework facilitates the generation of highly realistic and expressive gestures that closely replicate human movement and behavior, while simultaneously avoiding artifacts in the generation process. We evaluate our approach by comparing it with established methods for generating co-speech gestures as well as with existing datasets of human behavior. We also perform an ablation study to assess our findings. The results show that our approach outperforms the current state of the art by a clear margin and is partially indistinguishable from human gesturing. We make our data pipeline and the generation framework publicly available.
Addressing Data Scarcity in Multimodal User State Recognition by Combining Semi-Supervised and Supervised Learning
Feb 08, 2022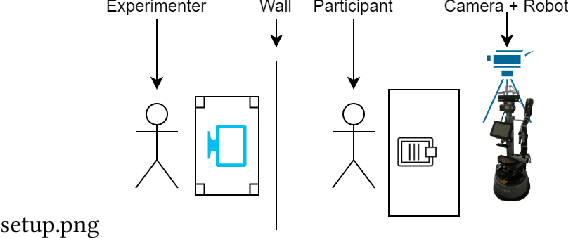
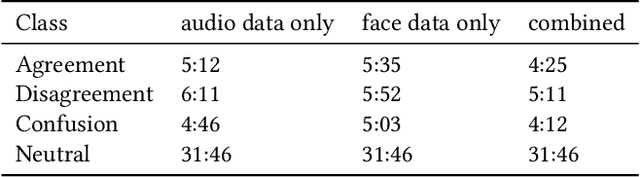
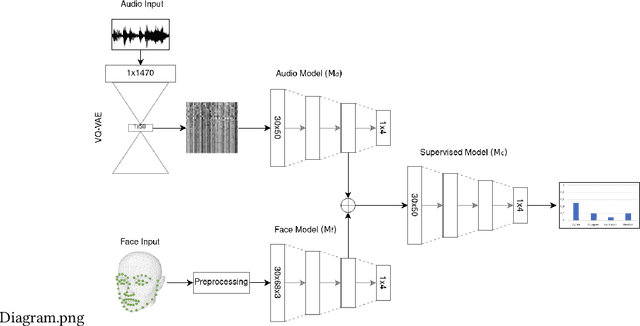
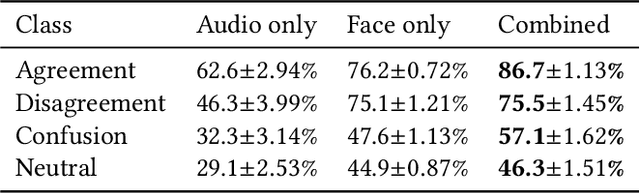
Detecting mental states of human users is crucial for the development of cooperative and intelligent robots, as it enables the robot to understand the user's intentions and desires. Despite their importance, it is difficult to obtain a large amount of high quality data for training automatic recognition algorithms as the time and effort required to collect and label such data is prohibitively high. In this paper we present a multimodal machine learning approach for detecting dis-/agreement and confusion states in a human-robot interaction environment, using just a small amount of manually annotated data. We collect a data set by conducting a human-robot interaction study and develop a novel preprocessing pipeline for our machine learning approach. By combining semi-supervised and supervised architectures, we are able to achieve an average F1-score of 81.1\% for dis-/agreement detection with a small amount of labeled data and a large unlabeled data set, while simultaneously increasing the robustness of the model compared to the supervised approach.