 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAPE-PM: Building and Utilizing Dynamic Partner Models for Adaptive Explanation Generation
May 19, 2025Adapting to the addressee is crucial for successful explanations, yet poses significant challenges for dialogsystems. We adopt the approach of treating explanation generation as a non-stationary decision process, where the optimal strategy varies according to changing beliefs about the explainee and the interaction context. In this paper we address the questions of (1) how to track the interaction context and the relevant listener features in a formally defined computational partner model, and (2) how to utilize this model in the dynamically adjusted, rational decision process that determines the currently best explanation strategy. We propose a Bayesian inference-based approach to continuously update the partner model based on user feedback, and a non-stationary Markov Decision Process to adjust decision-making based on the partner model values. We evaluate an implementation of this framework with five simulated interlocutors, demonstrating its effectiveness in adapting to different partners with constant and even changing feedback behavior. The results show high adaptivity with distinct explanation strategies emerging for different partners, highlighting the potential of our approach to improve explainable AI systems and dialogsystems in general.
Investigating Co-Constructive Behavior of Large Language Models in Explanation Dialogues
Apr 25, 2025The ability to generate explanations that are understood by explainees is the quintessence of explainable artificial intelligence. Since understanding depends on the explainee's background and needs, recent research has focused on co-constructive explanation dialogues, where the explainer continuously monitors the explainee's understanding and adapts explanations dynamically. We investigate the ability of large language models (LLMs) to engage as explainers in co-constructive explanation dialogues. In particular, we present a user study in which explainees interact with LLMs, of which some have been instructed to explain a predefined topic co-constructively. We evaluate the explainees' understanding before and after the dialogue, as well as their perception of the LLMs' co-constructive behavior. Our results indicate that current LLMs show some co-constructive behaviors, such as asking verification questions, that foster the explainees' engagement and can improve understanding of a topic. However, their ability to effectively monitor the current understanding and scaffold the explanations accordingly remains limited.
Towards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Oct 08, 2024

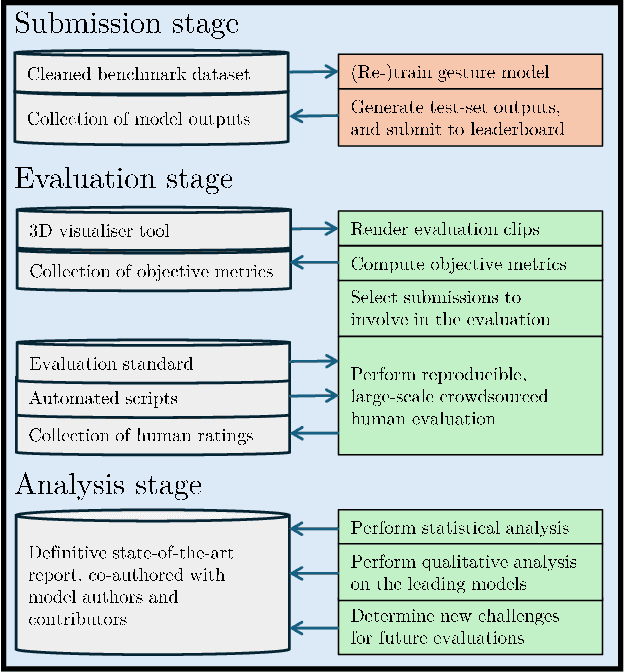

Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
Towards an Analysis of Discourse and Interactional Pragmatic Reasoning Capabilities of Large Language Models
Aug 06, 2024In this work, we want to give an overview on which pragmatic abilities have been tested in LLMs so far and how these tests have been carried out. To do this, we first discuss the scope of the field of pragmatics and suggest a subdivision into discourse pragmatics and interactional pragmatics. We give a non-exhaustive overview of the phenomena of those two subdomains and the methods traditionally used to analyze them. We subsequently consider the resulting heterogeneous set of phenomena and methods as a starting point for our survey of work on discourse pragmatics and interactional pragmatics in the context of LLMs.
Integrating Representational Gestures into Automatically Generated Embodied Explanations and its Effects on Understanding and Interaction Quality
Jun 18, 2024In human interaction, gestures serve various functions such as marking speech rhythm, highlighting key elements, and supplementing information. These gestures are also observed in explanatory contexts. However, the impact of gestures on explanations provided by virtual agents remains underexplored. A user study was carried out to investigate how different types of gestures influence perceived interaction quality and listener understanding. This study addresses the effect of gestures in explanation by developing an embodied virtual explainer integrating both beat gestures and iconic gestures to enhance its automatically generated verbal explanations. Our model combines beat gestures generated by a learned speech-driven synthesis module with manually captured iconic gestures, supporting the agent's verbal expressions about the board game Quarto! as an explanation scenario. Findings indicate that neither the use of iconic gestures alone nor their combination with beat gestures outperforms the baseline or beat-only conditions in terms of understanding. Nonetheless, compared to prior research, the embodied agent significantly enhances understanding.
AQ-GT: a Temporally Aligned and Quantized GRU-Transformer for Co-Speech Gesture Synthesis
May 08, 2023The generation of realistic and contextually relevant co-speech gestures is a challenging yet increasingly important task in the creation of multimodal artificial agents. Prior methods focused on learning a direct correspondence between co-speech gesture representations and produced motions, which created seemingly natural but often unconvincing gestures during human assessment. We present an approach to pre-train partial gesture sequences using a generative adversarial network with a quantization pipeline. The resulting codebook vectors serve as both input and output in our framework, forming the basis for the generation and reconstruction of gestures. By learning the mapping of a latent space representation as opposed to directly mapping it to a vector representation, this framework facilitates the generation of highly realistic and expressive gestures that closely replicate human movement and behavior, while simultaneously avoiding artifacts in the generation process. We evaluate our approach by comparing it with established methods for generating co-speech gestures as well as with existing datasets of human behavior. We also perform an ablation study to assess our findings. The results show that our approach outperforms the current state of the art by a clear margin and is partially indistinguishable from human gesturing. We make our data pipeline and the generation framework publicly available.
Addressing Data Scarcity in Multimodal User State Recognition by Combining Semi-Supervised and Supervised Learning
Feb 08, 2022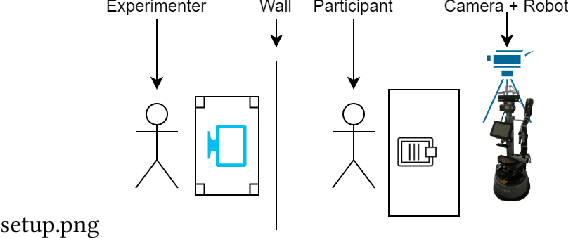
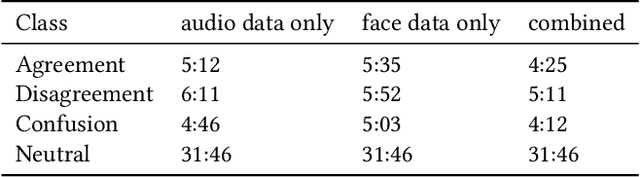
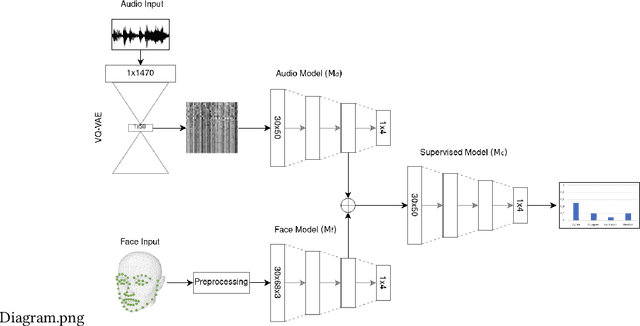
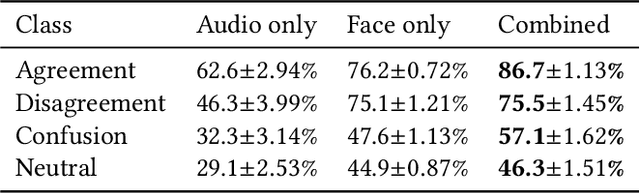
Detecting mental states of human users is crucial for the development of cooperative and intelligent robots, as it enables the robot to understand the user's intentions and desires. Despite their importance, it is difficult to obtain a large amount of high quality data for training automatic recognition algorithms as the time and effort required to collect and label such data is prohibitively high. In this paper we present a multimodal machine learning approach for detecting dis-/agreement and confusion states in a human-robot interaction environment, using just a small amount of manually annotated data. We collect a data set by conducting a human-robot interaction study and develop a novel preprocessing pipeline for our machine learning approach. By combining semi-supervised and supervised architectures, we are able to achieve an average F1-score of 81.1\% for dis-/agreement detection with a small amount of labeled data and a large unlabeled data set, while simultaneously increasing the robustness of the model compared to the supervised approach.
Towards autonomous artificial agents with an active self: modeling sense of control in situated action
Dec 10, 2021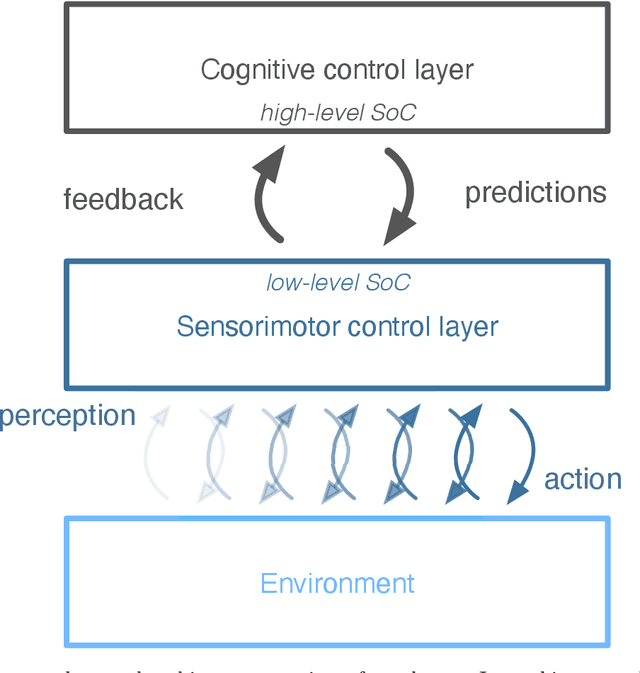

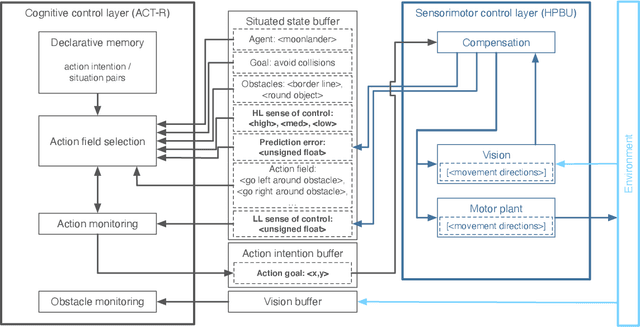

In this paper we present a computational modeling account of an active self in artificial agents. In particular we focus on how an agent can be equipped with a sense of control and how it arises in autonomous situated action and, in turn, influences action control. We argue that this requires laying out an embodied cognitive model that combines bottom-up processes (sensorimotor learning and fine-grained adaptation of control) with top-down processes (cognitive processes for strategy selection and decision-making). We present such a conceptual computational architecture based on principles of predictive processing and free energy minimization. Using this general model, we describe how a sense of control can form across the levels of a control hierarchy and how this can support action control in an unpredictable environment. We present an implementation of this model as well as first evaluations in a simulated task scenario, in which an autonomous agent has to cope with un-/predictable situations and experiences corresponding sense of control. We explore different model parameter settings that lead to different ways of combining low-level and high-level action control. The results show the importance of appropriately weighting information in situations where the need for low/high-level action control varies and they demonstrate how the sense of control can facilitate this.
Resonating Minds -- Emergent Collaboration Through Hierarchical Active Inference
Dec 02, 2021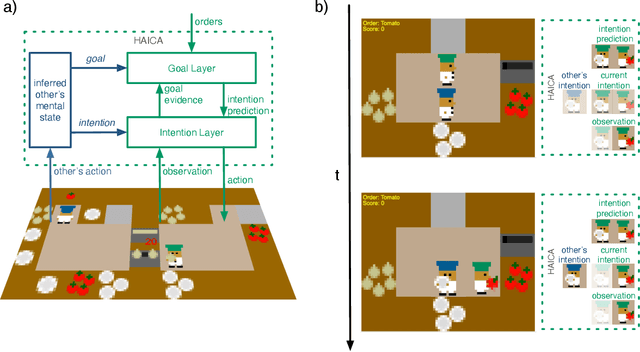

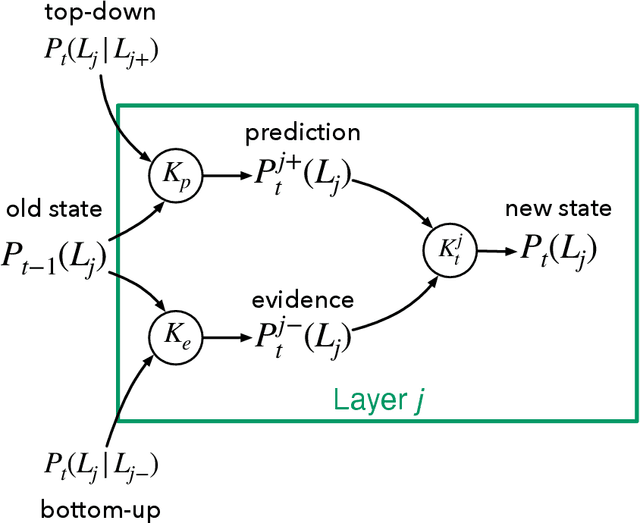

Working together on complex collaborative tasks requires agents to coordinate their actions. Doing this explicitly or completely prior to the actual interaction is not always possible nor sufficient. Agents also need to continuously understand the current actions of others and quickly adapt their own behavior appropriately. Here we investigate how efficient, automatic coordination processes at the level of mental states (intentions, goals), which we call belief resonance, can lead to collaborative situated problem-solving. We present a model of hierarchical active inference for collaborative agents (HAICA). It combines efficient Bayesian Theory of Mind processes with a perception-action system based on predictive processing and active inference. Belief resonance is realized by letting the inferred mental states of one agent influence another agent's predictive beliefs about its own goals and intentions. This way, the inferred mental states influence the agent's own task behavior without explicit collaborative reasoning. We implement and evaluate this model in the Overcooked domain, in which two agents with varying degrees of belief resonance team up to fulfill meal orders. Our results demonstrate that agents based on HAICA achieve a team performance comparable to recent state of the art approaches, while incurring much lower computational costs. We also show that belief resonance is especially beneficial in settings were the agents have asymmetric knowledge about the environment. The results indicate that belief resonance and active inference allow for quick and efficient agent coordination, and thus can serve as a building block for collaborative cognitive agents.
Satisficing Mentalizing: Bayesian Models of Theory of Mind Reasoning in Scenarios with Different Uncertainties
Sep 23, 2019



The ability to interpret the mental state of another agent based on its behavior, also called Theory of Mind (ToM), is crucial for humans in any kind of social interaction. Artificial systems, such as intelligent assistants, would also greatly benefit from such mentalizing capabilities. However, humans and systems alike are bound by limitations in their available computational resources. This raises the need for satisficing mentalizing, reconciling accuracy and efficiency in mental state inference that is good enough for a given situation. In this paper, we present different Bayesian models of ToM reasoning and evaluate them based on actual human behavior data that were generated under different kinds of uncertainties. We propose a Switching approach that combines specialized models, embodying simplifying presumptions, in order to achieve a more statisficing mentalizing compared to a Full Bayesian ToM model.