 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Robot's Inner Critic: Self-Refinement of Social Behaviors through VLM-based Replanning
Mar 20, 2026Conventional robot social behavior generation has been limited in flexibility and autonomy, relying on predefined motions or human feedback. This study proposes CRISP (Critique-and-Replan for Interactive Social Presence), an autonomous framework where a robot critiques and replans its own actions by leveraging a Vision-Language Model (VLM) as a `human-like social critic.' CRISP integrates (1) extraction of movable joints and constraints by analyzing the robot's description file (e.g., MJCF), (2) generation of step-by-step behavior plans based on situational context, (3) generation of low-level joint control code by referencing visual information (joint range-of-motion visualizations), (4) VLM-based evaluation of social appropriateness and naturalness, including pinpointing erroneous steps, and (5) iterative refinement of behaviors through reward-based search. This approach is not tied to a specific robot API; it can generate subtly different, human-like motions on various platforms using only the robot's structure file. In a user study involving five different robot types and 20 scenarios, including mobile manipulators and humanoids, our proposed method achieved significantly higher preference and situational appropriateness ratings compared to previous methods. This research presents a general framework that minimizes human intervention while expanding the robot's autonomous interaction capabilities and cross-platform applicability. Detailed result videos and supplementary information regarding this work are available at: https://limjiyu99.github.io/inner-critic/
Learning Dexterous Bimanual Catch Skills through Adversarial-Cooperative Heterogeneous-Agent Reinforcement Learning
Feb 17, 2025
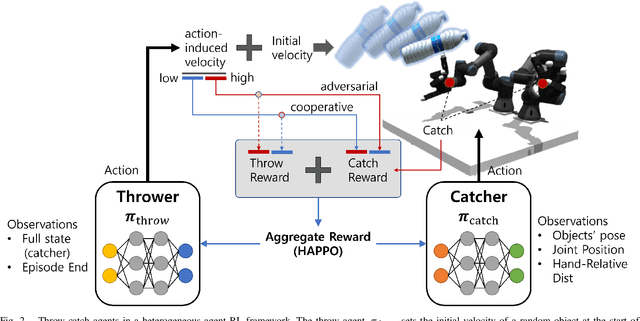


Robotic catching has traditionally focused on single-handed systems, which are limited in their ability to handle larger or more complex objects. In contrast, bimanual catching offers significant potential for improved dexterity and object handling but introduces new challenges in coordination and control. In this paper, we propose a novel framework for learning dexterous bimanual catching skills using Heterogeneous-Agent Reinforcement Learning (HARL). Our approach introduces an adversarial reward scheme, where a throw agent increases the difficulty of throws-adjusting speed-while a catch agent learns to coordinate both hands to catch objects under these evolving conditions. We evaluate the framework in simulated environments using 15 different objects, demonstrating robustness and versatility in handling diverse objects. Our method achieved approximately a 2x increase in catching reward compared to single-agent baselines across 15 diverse objects.
Towards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Oct 08, 2024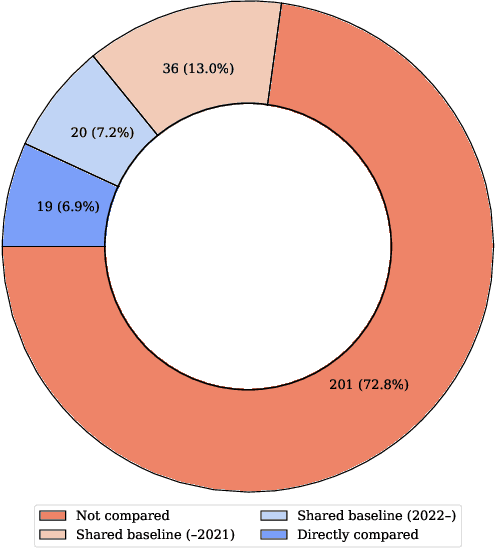

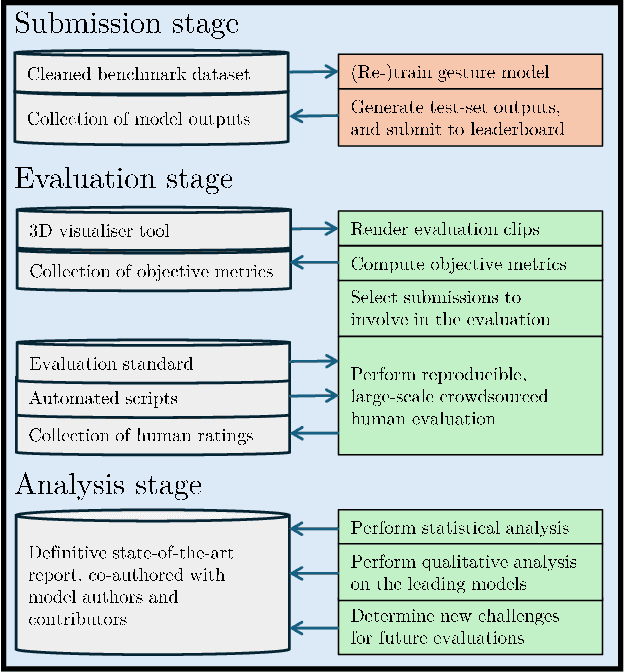

Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
Universal Gloss-level Representation for Gloss-free Sign Language Translation and Production
Jul 03, 2024



Sign language, essential for the deaf and hard-of-hearing, presents unique challenges in translation and production due to its multimodal nature and the inherent ambiguity in mapping sign language motion to spoken language words. Previous methods often rely on gloss annotations, requiring time-intensive labor and specialized expertise in sign language. Gloss-free methods have emerged to address these limitations, but they often depend on external sign language data or dictionaries, failing to completely eliminate the need for gloss annotations. There is a clear demand for a comprehensive approach that can supplant gloss annotations and be utilized for both Sign Language Translation (SLT) and Sign Language Production (SLP). We introduce Universal Gloss-level Representation (UniGloR), a unified and self-supervised solution for both SLT and SLP, trained on multiple datasets including PHOENIX14T, How2Sign, and NIASL2021. Our results demonstrate UniGloR's effectiveness in the translation and production tasks. We further report an encouraging result for the Sign Language Recognition (SLR) on previously unseen data. Our study suggests that self-supervised learning can be made in a unified manner, paving the way for innovative and practical applications in future research.
LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents
Feb 13, 2024


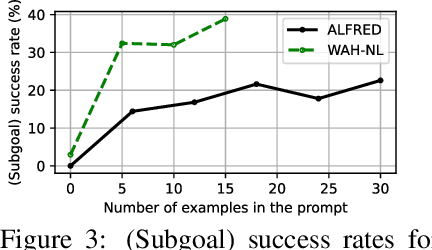
Large language models (LLMs) have recently received considerable attention as alternative solutions for task planning. However, comparing the performance of language-oriented task planners becomes difficult, and there exists a dearth of detailed exploration regarding the effects of various factors such as pre-trained model selection and prompt construction. To address this, we propose a benchmark system for automatically quantifying performance of task planning for home-service embodied agents. Task planners are tested on two pairs of datasets and simulators: 1) ALFRED and AI2-THOR, 2) an extension of Watch-And-Help and VirtualHome. Using the proposed benchmark system, we perform extensive experiments with LLMs and prompts, and explore several enhancements of the baseline planner. We expect that the proposed benchmark tool would accelerate the development of language-oriented task planners.
The GENEA Challenge 2023: A large scale evaluation of gesture generation models in monadic and dyadic settings
Aug 24, 2023This paper reports on the GENEA Challenge 2023, in which participating teams built speech-driven gesture-generation systems using the same speech and motion dataset, followed by a joint evaluation. This year's challenge provided data on both sides of a dyadic interaction, allowing teams to generate full-body motion for an agent given its speech (text and audio) and the speech and motion of the interlocutor. We evaluated 12 submissions and 2 baselines together with held-out motion-capture data in several large-scale user studies. The studies focused on three aspects: 1) the human-likeness of the motion, 2) the appropriateness of the motion for the agent's own speech whilst controlling for the human-likeness of the motion, and 3) the appropriateness of the motion for the behaviour of the interlocutor in the interaction, using a setup that controls for both the human-likeness of the motion and the agent's own speech. We found a large span in human-likeness between challenge submissions, with a few systems rated close to human mocap. Appropriateness seems far from being solved, with most submissions performing in a narrow range slightly above chance, far behind natural motion. The effect of the interlocutor is even more subtle, with submitted systems at best performing barely above chance. Interestingly, a dyadic system being highly appropriate for agent speech does not necessarily imply high appropriateness for the interlocutor. Additional material is available via the project website at https://svito-zar.github.io/GENEAchallenge2023/ .
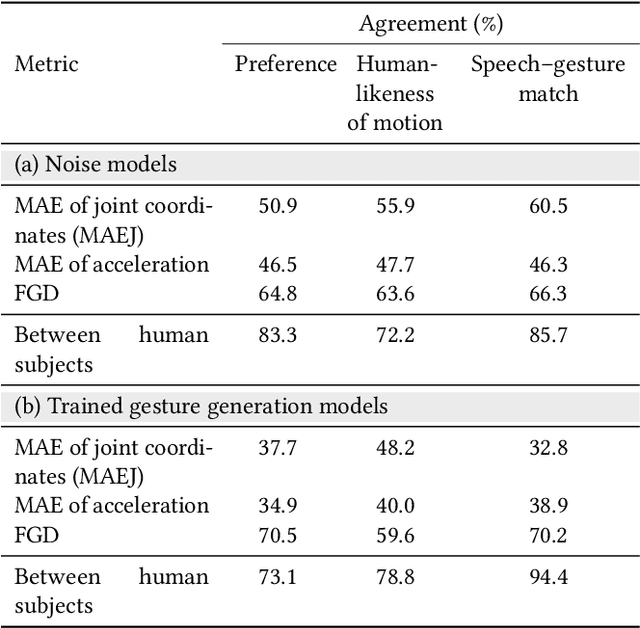
Evaluating gesture-generation in a large-scale open challenge: The GENEA Challenge 2022
Mar 15, 2023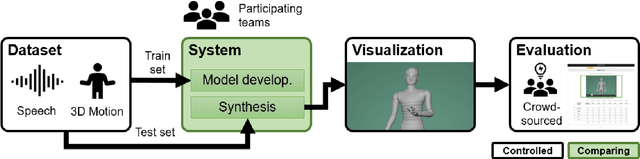
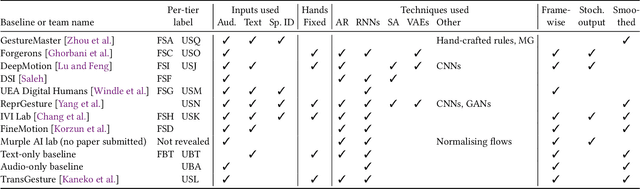
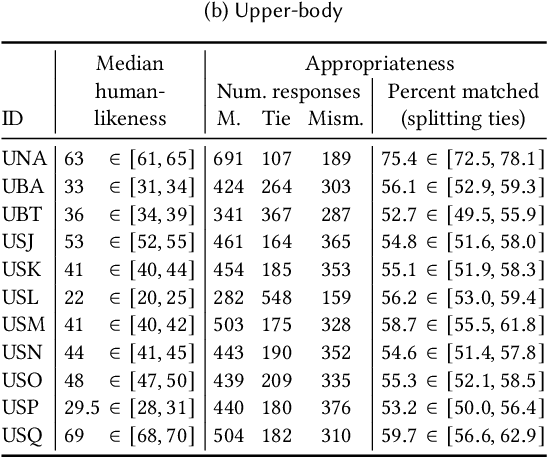
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. The dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in a dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier, we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which has been a difficult problem in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. We also find that conventional objective metrics do not correlate well with subjective human-likeness ratings in this large evaluation. The one exception is the Fr\'echet gesture distance (FGD), which achieves a Kendall's tau rank correlation of around -0.5. Based on the challenge results we formulate numerous recommendations for system building and evaluation.
The GENEA Challenge 2022: A large evaluation of data-driven co-speech gesture generation
Aug 22, 2022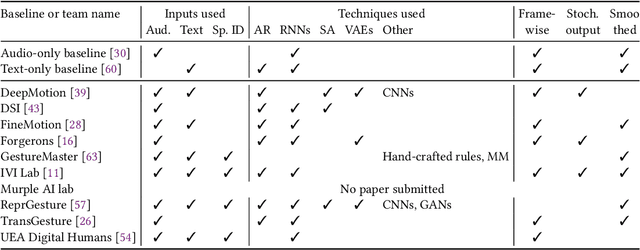
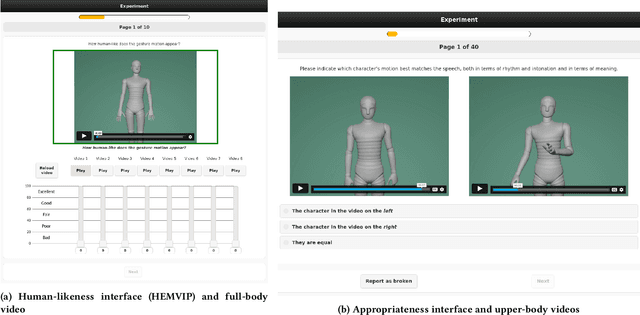
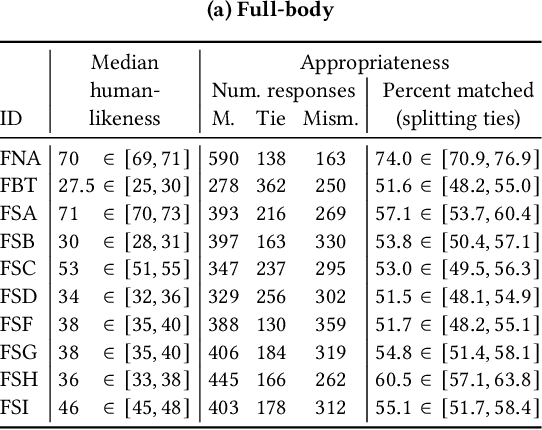
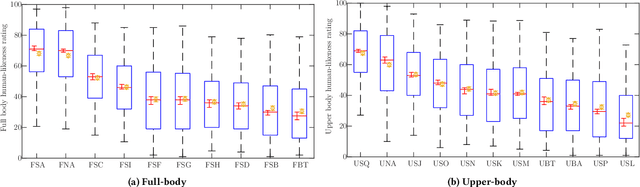
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. This year's dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which previously was a major challenge in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. Additional material is available via the project website at https://youngwoo-yoon.github.io/GENEAchallenge2022/
Evaluating the Quality of a Synthesized Motion with the Fréchet Motion Distance
Apr 27, 2022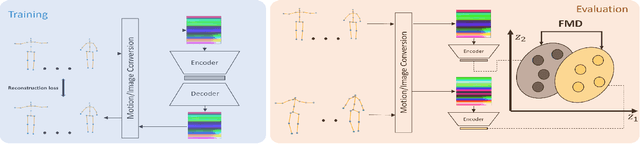

Evaluating the Quality of a Synthesized Motion with the Fr\'echet Motion Distance
Speech Gesture Generation from the Trimodal Context of Text, Audio, and Speaker Identity
Sep 04, 2020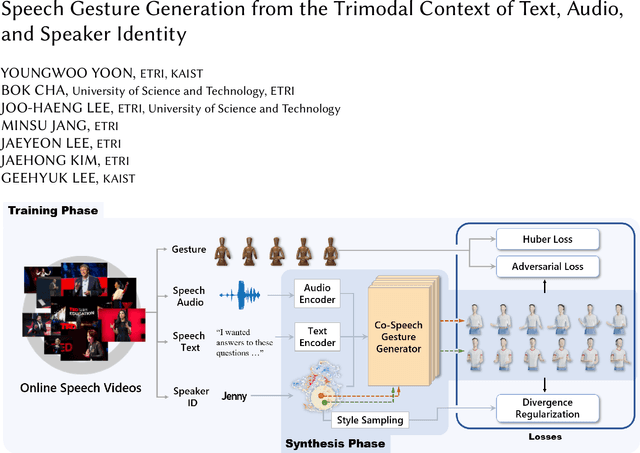
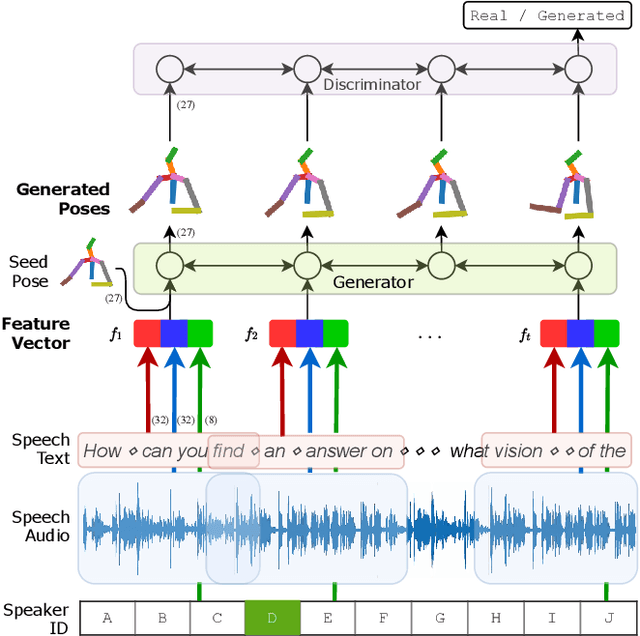

For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.