 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend-and-Refine: Interactive keypoint estimation and quantitative cervical vertebrae analysis for bone age assessment
Jul 10, 2025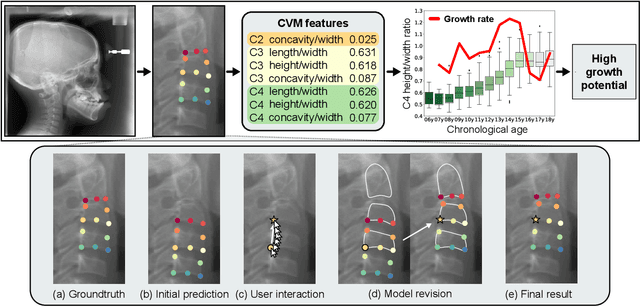
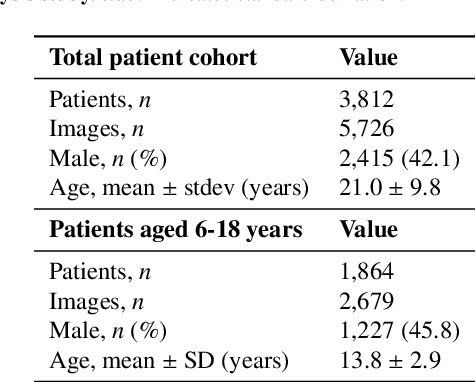
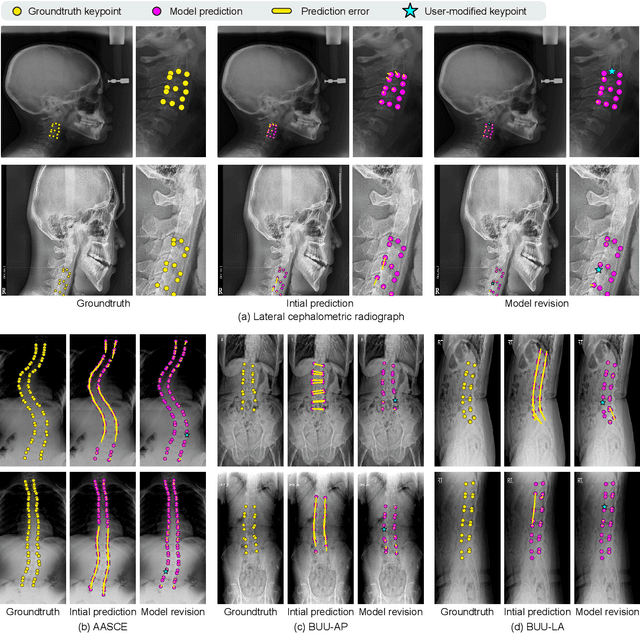
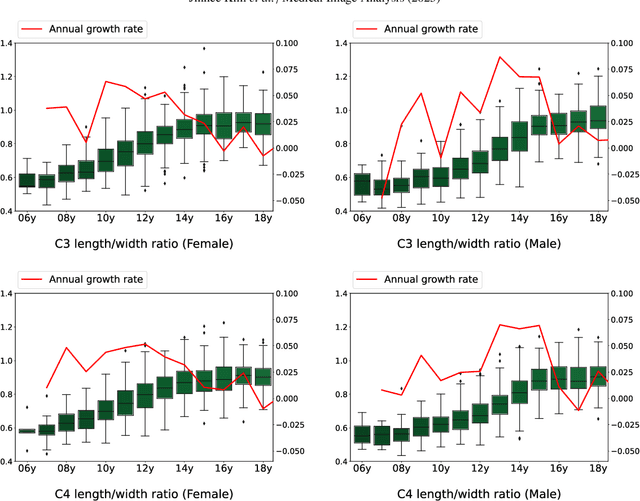
In pediatric orthodontics, accurate estimation of growth potential is essential for developing effective treatment strategies. Our research aims to predict this potential by identifying the growth peak and analyzing cervical vertebra morphology solely through lateral cephalometric radiographs. We accomplish this by comprehensively analyzing cervical vertebral maturation (CVM) features from these radiographs. This methodology provides clinicians with a reliable and efficient tool to determine the optimal timings for orthodontic interventions, ultimately enhancing patient outcomes. A crucial aspect of this approach is the meticulous annotation of keypoints on the cervical vertebrae, a task often challenged by its labor-intensive nature. To mitigate this, we introduce Attend-and-Refine Network (ARNet), a user-interactive, deep learning-based model designed to streamline the annotation process. ARNet features Interaction-guided recalibration network, which adaptively recalibrates image features in response to user feedback, coupled with a morphology-aware loss function that preserves the structural consistency of keypoints. This novel approach substantially reduces manual effort in keypoint identification, thereby enhancing the efficiency and accuracy of the process. Extensively validated across various datasets, ARNet demonstrates remarkable performance and exhibits wide-ranging applicability in medical imaging. In conclusion, our research offers an effective AI-assisted diagnostic tool for assessing growth potential in pediatric orthodontics, marking a significant advancement in the field.
Instance-Specific Test-Time Training for Speech Editing in the Wild
Jun 16, 2025Speech editing systems aim to naturally modify speech content while preserving acoustic consistency and speaker identity. However, previous studies often struggle to adapt to unseen and diverse acoustic conditions, resulting in degraded editing performance in real-world scenarios. To address this, we propose an instance-specific test-time training method for speech editing in the wild. Our approach employs direct supervision from ground-truth acoustic features in unedited regions, and indirect supervision in edited regions via auxiliary losses based on duration constraints and phoneme prediction. This strategy mitigates the bandwidth discontinuity problem in speech editing, ensuring smooth acoustic transitions between unedited and edited regions. Additionally, it enables precise control over speech rate by adapting the model to target durations via mask length adjustment during test-time training. Experiments on in-the-wild benchmark datasets demonstrate that our method outperforms existing speech editing systems in both objective and subjective evaluations.
Naturalness-Aware Curriculum Learning with Dynamic Temperature for Speech Deepfake Detection
May 20, 2025Recent advances in speech deepfake detection (SDD) have significantly improved artifacts-based detection in spoofed speech. However, most models overlook speech naturalness, a crucial cue for distinguishing bona fide speech from spoofed speech. This study proposes naturalness-aware curriculum learning, a novel training framework that leverages speech naturalness to enhance the robustness and generalization of SDD. This approach measures sample difficulty using both ground-truth labels and mean opinion scores, and adjusts the training schedule to progressively introduce more challenging samples. To further improve generalization, a dynamic temperature scaling method based on speech naturalness is incorporated into the training process. A 23% relative reduction in the EER was achieved in the experiments on the ASVspoof 2021 DF dataset, without modifying the model architecture. Ablation studies confirmed the effectiveness of naturalness-aware training strategies for SDD tasks.
Learning Dexterous Bimanual Catch Skills through Adversarial-Cooperative Heterogeneous-Agent Reinforcement Learning
Feb 17, 2025
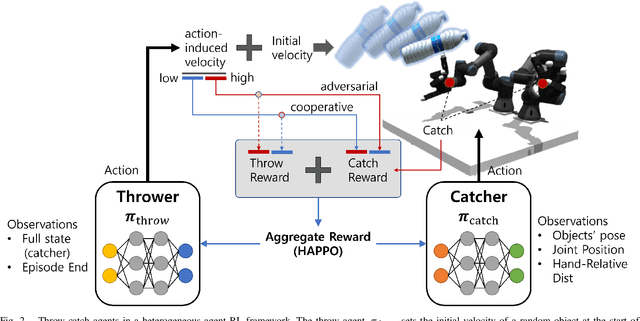


Robotic catching has traditionally focused on single-handed systems, which are limited in their ability to handle larger or more complex objects. In contrast, bimanual catching offers significant potential for improved dexterity and object handling but introduces new challenges in coordination and control. In this paper, we propose a novel framework for learning dexterous bimanual catching skills using Heterogeneous-Agent Reinforcement Learning (HARL). Our approach introduces an adversarial reward scheme, where a throw agent increases the difficulty of throws-adjusting speed-while a catch agent learns to coordinate both hands to catch objects under these evolving conditions. We evaluate the framework in simulated environments using 15 different objects, demonstrating robustness and versatility in handling diverse objects. Our method achieved approximately a 2x increase in catching reward compared to single-agent baselines across 15 diverse objects.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024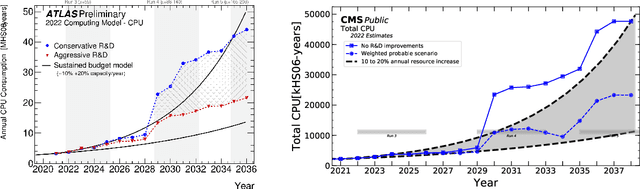
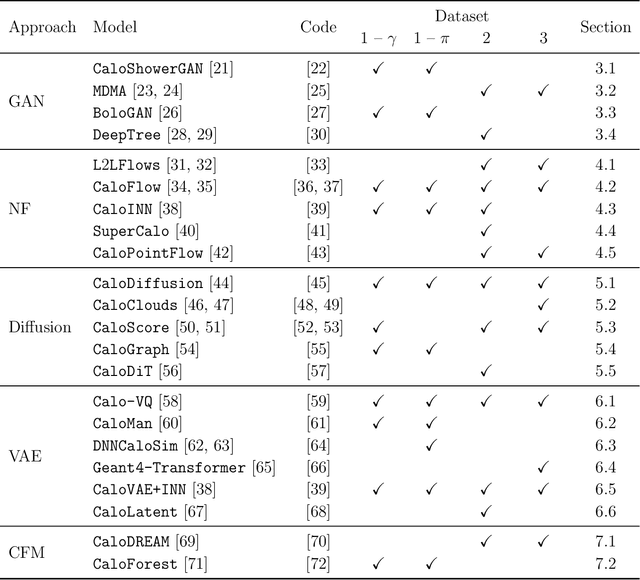
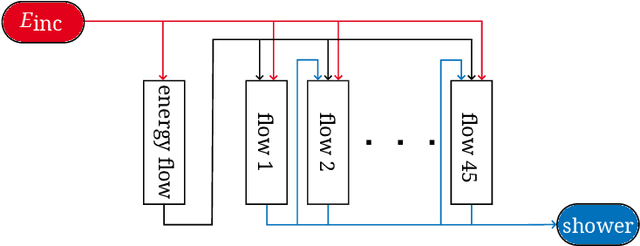
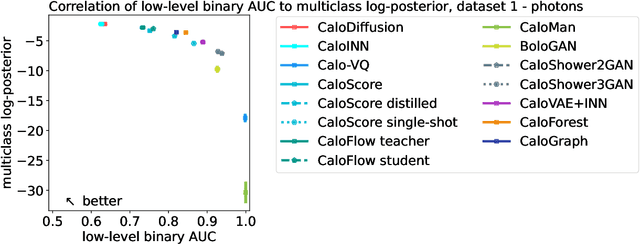
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
CMTA: Cross-Modal Temporal Alignment for Event-guided Video Deblurring
Aug 28, 2024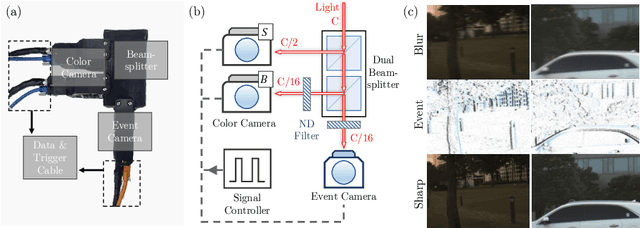

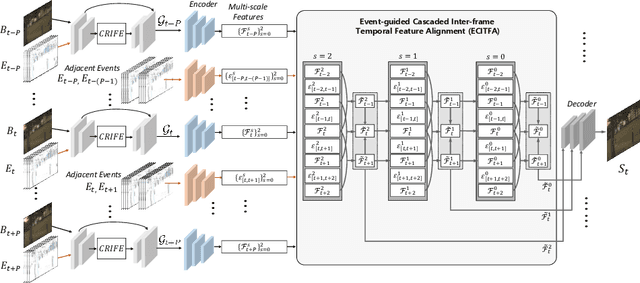

Video deblurring aims to enhance the quality of restored results in motion-blurred videos by effectively gathering information from adjacent video frames to compensate for the insufficient data in a single blurred frame. However, when faced with consecutively severe motion blur situations, frame-based video deblurring methods often fail to find accurate temporal correspondence among neighboring video frames, leading to diminished performance. To address this limitation, we aim to solve the video deblurring task by leveraging an event camera with micro-second temporal resolution. To fully exploit the dense temporal resolution of the event camera, we propose two modules: 1) Intra-frame feature enhancement operates within the exposure time of a single blurred frame, iteratively enhancing cross-modality features in a recurrent manner to better utilize the rich temporal information of events, 2) Inter-frame temporal feature alignment gathers valuable long-range temporal information to target frames, aggregating sharp features leveraging the advantages of the events. In addition, we present a novel dataset composed of real-world blurred RGB videos, corresponding sharp videos, and event data. This dataset serves as a valuable resource for evaluating event-guided deblurring methods. We demonstrate that our proposed methods outperform state-of-the-art frame-based and event-based motion deblurring methods through extensive experiments conducted on both synthetic and real-world deblurring datasets. The code and dataset are available at https://github.com/intelpro/CMTA.
Scaling Up Diffusion and Flow-based XGBoost Models
Aug 28, 2024Novel machine learning methods for tabular data generation are often developed on small datasets which do not match the scale required for scientific applications. We investigate a recent proposal to use XGBoost as the function approximator in diffusion and flow-matching models on tabular data, which proved to be extremely memory intensive, even on tiny datasets. In this work, we conduct a critical analysis of the existing implementation from an engineering perspective, and show that these limitations are not fundamental to the method; with better implementation it can be scaled to datasets 370x larger than previously used. Our efficient implementation also unlocks scaling models to much larger sizes which we show directly leads to improved performance on benchmark tasks. We also propose algorithmic improvements that can further benefit resource usage and model performance, including multi-output trees which are well-suited to generative modeling. Finally, we present results on large-scale scientific datasets derived from experimental particle physics as part of the Fast Calorimeter Simulation Challenge. Code is available at https://github.com/layer6ai-labs/calo-forest.
Towards Real-world Event-guided Low-light Video Enhancement and Deblurring
Aug 27, 2024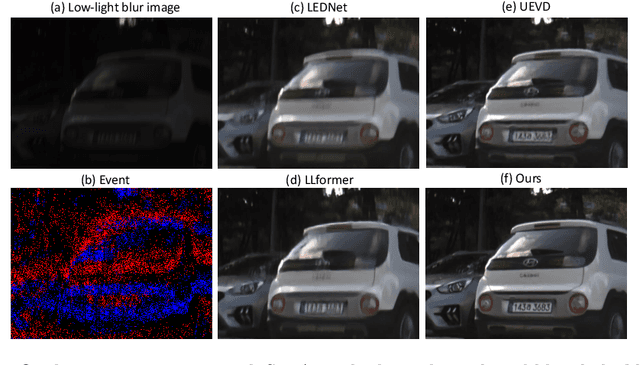

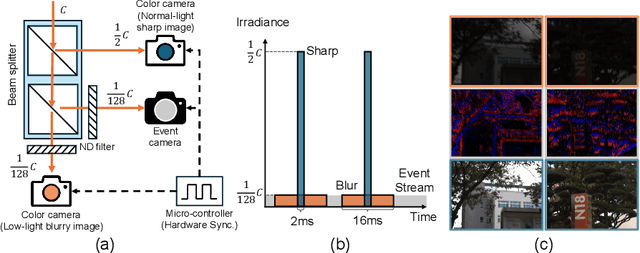
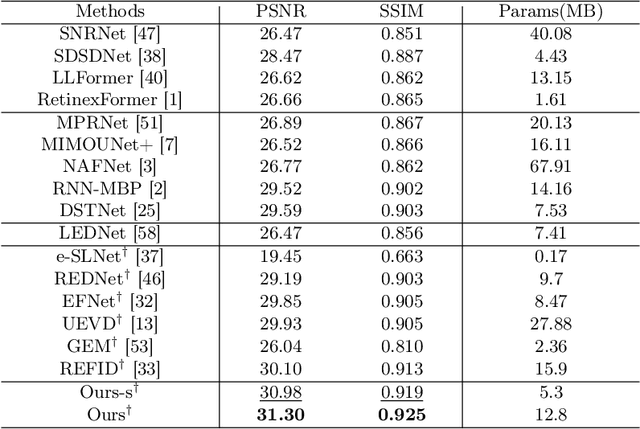
In low-light conditions, capturing videos with frame-based cameras often requires long exposure times, resulting in motion blur and reduced visibility. While frame-based motion deblurring and low-light enhancement have been studied, they still pose significant challenges. Event cameras have emerged as a promising solution for improving image quality in low-light environments and addressing motion blur. They provide two key advantages: capturing scene details well even in low light due to their high dynamic range, and effectively capturing motion information during long exposures due to their high temporal resolution. Despite efforts to tackle low-light enhancement and motion deblurring using event cameras separately, previous work has not addressed both simultaneously. To explore the joint task, we first establish real-world datasets for event-guided low-light enhancement and deblurring using a hybrid camera system based on beam splitters. Subsequently, we introduce an end-to-end framework to effectively handle these tasks. Our framework incorporates a module to efficiently leverage temporal information from events and frames. Furthermore, we propose a module to utilize cross-modal feature information to employ a low-pass filter for noise suppression while enhancing the main structural information. Our proposed method significantly outperforms existing approaches in addressing the joint task. Our project pages are available at https://github.com/intelpro/ELEDNet.
Cross-Modal Temporal Alignment for Event-guided Video Deblurring
Aug 27, 2024Video deblurring aims to enhance the quality of restored results in motion-blurred videos by effectively gathering information from adjacent video frames to compensate for the insufficient data in a single blurred frame. However, when faced with consecutively severe motion blur situations, frame-based video deblurring methods often fail to find accurate temporal correspondence among neighboring video frames, leading to diminished performance. To address this limitation, we aim to solve the video deblurring task by leveraging an event camera with micro-second temporal resolution. To fully exploit the dense temporal resolution of the event camera, we propose two modules: 1) Intra-frame feature enhancement operates within the exposure time of a single blurred frame, iteratively enhancing cross-modality features in a recurrent manner to better utilize the rich temporal information of events, 2) Inter-frame temporal feature alignment gathers valuable long-range temporal information to target frames, aggregating sharp features leveraging the advantages of the events. In addition, we present a novel dataset composed of real-world blurred RGB videos, corresponding sharp videos, and event data. This dataset serves as a valuable resource for evaluating event-guided deblurring methods. We demonstrate that our proposed methods outperform state-of-the-art frame-based and event-based motion deblurring methods through extensive experiments conducted on both synthetic and real-world deblurring datasets. The code and dataset are available at https://github.com/intelpro/CMTA.
Period Singer: Integrating Periodic and Aperiodic Variational Autoencoders for Natural-Sounding End-to-End Singing Voice Synthesis
Jun 14, 2024In this paper, we present Period Singer, a novel end-to-end singing voice synthesis (SVS) model that utilizes variational inference for periodic and aperiodic components, aimed at producing natural-sounding waveforms. Recent end-to-end SVS models have demonstrated the capability of synthesizing high-fidelity singing voices. However, owing to deterministic pitch conditioning, they do not fully address the one-to-many problem. To address this problem, we present the Period Singer architecture, which integrates variational autoencoders for the periodic and aperiodic components. Additionally, our methodology eliminates the dependency on an external aligner by estimating the phoneme alignment through a monotonic alignment search within note boundaries. Our empirical evaluations show that Period Singer outperforms existing end-to-end SVS models on Mandarin and Korean datasets. The efficacy of the proposed method was further corroborated by ablation studies.