 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSERT-RoLL: Robust Multi-Modal Perception for Diverse Driving Conditions with Stereo Event-RGB-Thermal Cameras, 4D Radar, and Dual-LiDAR
Apr 04, 2026In this paper, we present DSERT-RoLL, a driving dataset that incorporates stereo event, RGB, and thermal cameras together with 4D radar and dual LiDAR, collected across diverse weather and illumination conditions. The dataset provides precise 2D and 3D bounding boxes with track IDs and ego vehicle odometry, enabling fair comparisons within and across sensor combinations. It is designed to alleviate data scarcity for novel sensors such as event cameras and 4D radar and to support systematic studies of their behavior. We establish unified 3D and 2D benchmarks that enable direct comparison of characteristics and strengths across sensor families and within each family. We report baselines for representative single modality and multimodal methods and provide protocols that encourage research on different fusion strategies and sensor combinations. In addition, we propose a fusion framework that integrates sensor specific cues into a unified feature space and improves 3D detection robustness under varied weather and lighting.
From Sharp to Blur: Unsupervised Domain Adaptation for 2D Human Pose Estimation Under Extreme Motion Blur Using Event Cameras
Jul 30, 2025Human pose estimation is critical for applications such as rehabilitation, sports analytics, and AR/VR systems. However, rapid motion and low-light conditions often introduce motion blur, significantly degrading pose estimation due to the domain gap between sharp and blurred images. Most datasets assume stable conditions, making models trained on sharp images struggle in blurred environments. To address this, we introduce a novel domain adaptation approach that leverages event cameras, which capture high temporal resolution motion data and are inherently robust to motion blur. Using event-based augmentation, we generate motion-aware blurred images, effectively bridging the domain gap between sharp and blurred domains without requiring paired annotations. Additionally, we develop a student-teacher framework that iteratively refines pseudo-labels, leveraging mutual uncertainty masking to eliminate incorrect labels and enable more effective learning. Experimental results demonstrate that our approach outperforms conventional domain-adaptive human pose estimation methods, achieving robust pose estimation under motion blur without requiring annotations in the target domain. Our findings highlight the potential of event cameras as a scalable and effective solution for domain adaptation in real-world motion blur environments. Our project codes are available at https://github.com/kmax2001/EvSharp2Blur.
Ev-3DOD: Pushing the Temporal Boundaries of 3D Object Detection with Event Cameras
Feb 26, 2025Detecting 3D objects in point clouds plays a crucial role in autonomous driving systems. Recently, advanced multi-modal methods incorporating camera information have achieved notable performance. For a safe and effective autonomous driving system, algorithms that excel not only in accuracy but also in speed and low latency are essential. However, existing algorithms fail to meet these requirements due to the latency and bandwidth limitations of fixed frame rate sensors, e.g., LiDAR and camera. To address this limitation, we introduce asynchronous event cameras into 3D object detection for the first time. We leverage their high temporal resolution and low bandwidth to enable high-speed 3D object detection. Our method enables detection even during inter-frame intervals when synchronized data is unavailable, by retrieving previous 3D information through the event camera. Furthermore, we introduce the first event-based 3D object detection dataset, DSEC-3DOD, which includes ground-truth 3D bounding boxes at 100 FPS, establishing the first benchmark for event-based 3D detectors. The code and dataset are available at https://github.com/mickeykang16/Ev3DOD.
CMTA: Cross-Modal Temporal Alignment for Event-guided Video Deblurring
Aug 28, 2024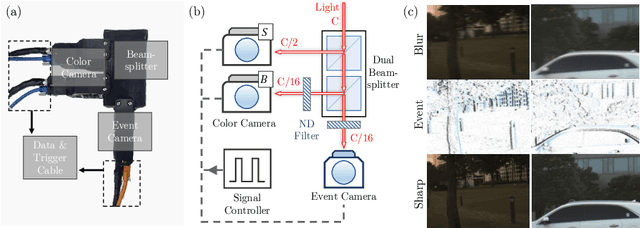

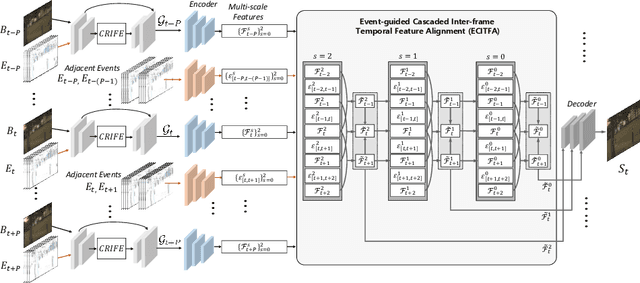

Video deblurring aims to enhance the quality of restored results in motion-blurred videos by effectively gathering information from adjacent video frames to compensate for the insufficient data in a single blurred frame. However, when faced with consecutively severe motion blur situations, frame-based video deblurring methods often fail to find accurate temporal correspondence among neighboring video frames, leading to diminished performance. To address this limitation, we aim to solve the video deblurring task by leveraging an event camera with micro-second temporal resolution. To fully exploit the dense temporal resolution of the event camera, we propose two modules: 1) Intra-frame feature enhancement operates within the exposure time of a single blurred frame, iteratively enhancing cross-modality features in a recurrent manner to better utilize the rich temporal information of events, 2) Inter-frame temporal feature alignment gathers valuable long-range temporal information to target frames, aggregating sharp features leveraging the advantages of the events. In addition, we present a novel dataset composed of real-world blurred RGB videos, corresponding sharp videos, and event data. This dataset serves as a valuable resource for evaluating event-guided deblurring methods. We demonstrate that our proposed methods outperform state-of-the-art frame-based and event-based motion deblurring methods through extensive experiments conducted on both synthetic and real-world deblurring datasets. The code and dataset are available at https://github.com/intelpro/CMTA.
Cross-Modal Temporal Alignment for Event-guided Video Deblurring
Aug 27, 2024Video deblurring aims to enhance the quality of restored results in motion-blurred videos by effectively gathering information from adjacent video frames to compensate for the insufficient data in a single blurred frame. However, when faced with consecutively severe motion blur situations, frame-based video deblurring methods often fail to find accurate temporal correspondence among neighboring video frames, leading to diminished performance. To address this limitation, we aim to solve the video deblurring task by leveraging an event camera with micro-second temporal resolution. To fully exploit the dense temporal resolution of the event camera, we propose two modules: 1) Intra-frame feature enhancement operates within the exposure time of a single blurred frame, iteratively enhancing cross-modality features in a recurrent manner to better utilize the rich temporal information of events, 2) Inter-frame temporal feature alignment gathers valuable long-range temporal information to target frames, aggregating sharp features leveraging the advantages of the events. In addition, we present a novel dataset composed of real-world blurred RGB videos, corresponding sharp videos, and event data. This dataset serves as a valuable resource for evaluating event-guided deblurring methods. We demonstrate that our proposed methods outperform state-of-the-art frame-based and event-based motion deblurring methods through extensive experiments conducted on both synthetic and real-world deblurring datasets. The code and dataset are available at https://github.com/intelpro/CMTA.
Towards Real-world Event-guided Low-light Video Enhancement and Deblurring
Aug 27, 2024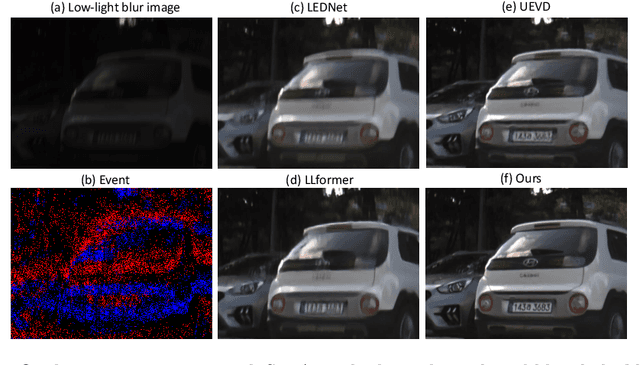

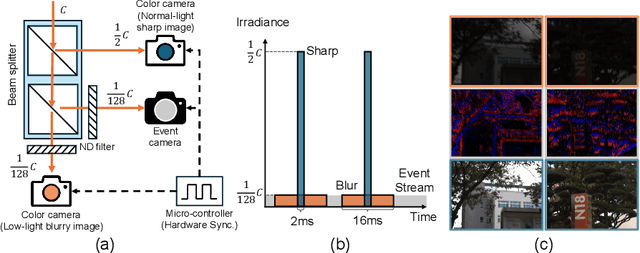
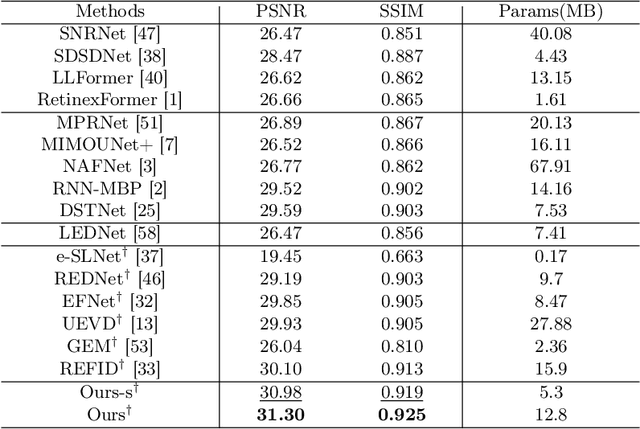
In low-light conditions, capturing videos with frame-based cameras often requires long exposure times, resulting in motion blur and reduced visibility. While frame-based motion deblurring and low-light enhancement have been studied, they still pose significant challenges. Event cameras have emerged as a promising solution for improving image quality in low-light environments and addressing motion blur. They provide two key advantages: capturing scene details well even in low light due to their high dynamic range, and effectively capturing motion information during long exposures due to their high temporal resolution. Despite efforts to tackle low-light enhancement and motion deblurring using event cameras separately, previous work has not addressed both simultaneously. To explore the joint task, we first establish real-world datasets for event-guided low-light enhancement and deblurring using a hybrid camera system based on beam splitters. Subsequently, we introduce an end-to-end framework to effectively handle these tasks. Our framework incorporates a module to efficiently leverage temporal information from events and frames. Furthermore, we propose a module to utilize cross-modal feature information to employ a low-pass filter for noise suppression while enhancing the main structural information. Our proposed method significantly outperforms existing approaches in addressing the joint task. Our project pages are available at https://github.com/intelpro/ELEDNet.
Towards Robust Event-based Networks for Nighttime via Unpaired Day-to-Night Event Translation
Jul 15, 2024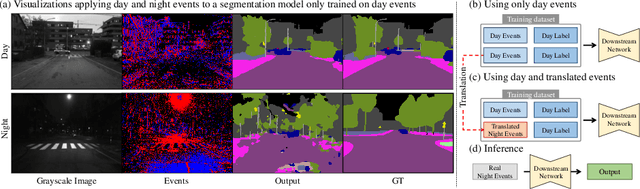
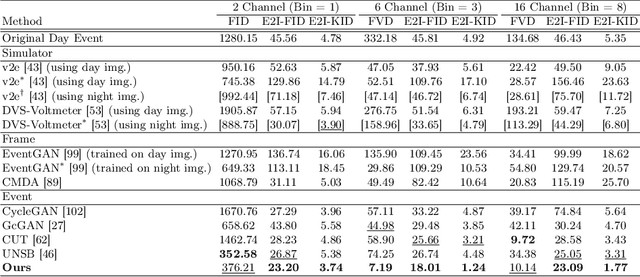
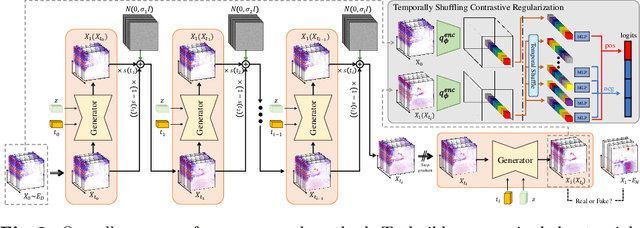
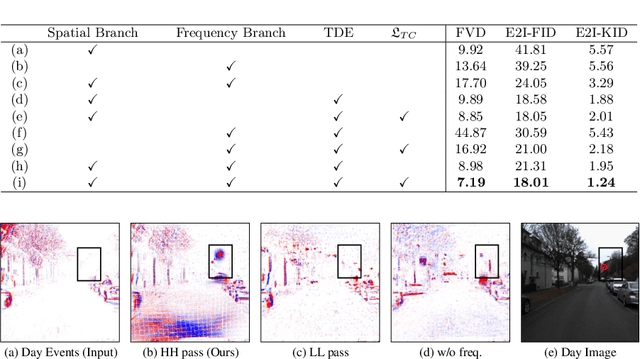
Event cameras with high dynamic range ensure scene capture even in low-light conditions. However, night events exhibit patterns different from those captured during the day. This difference causes performance degradation when applying night events to a model trained solely on day events. This limitation persists due to a lack of annotated night events. To overcome the limitation, we aim to alleviate data imbalance by translating annotated day data into night events. However, generating events from different modalities challenges reproducing their unique properties. Accordingly, we propose an unpaired event-to-event day-to-night translation model that effectively learns to map from one domain to another using Diffusion GAN. The proposed translation model analyzes events in spatio-temporal dimension with wavelet decomposition and disentangled convolution layers. We also propose a new temporal contrastive learning with a novel shuffling and sampling strategy to regularize temporal continuity. To validate the efficacy of the proposed methodology, we redesign metrics for evaluating events translated in an unpaired setting, aligning them with the event modality for the first time. Our framework shows the successful day-to-night event translation while preserving the characteristics of events. In addition, through our translation method, we facilitate event-based modes to learn about night events by translating annotated day events into night events. Our approach effectively mitigates the performance degradation of applying real night events to downstream tasks. The code is available at https://github.com/jeongyh98/UDNET.
Finding Meaning in Points: Weakly Supervised Semantic Segmentation for Event Cameras
Jul 15, 2024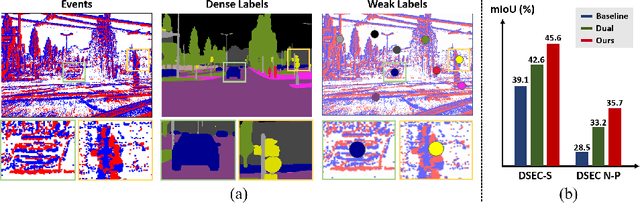
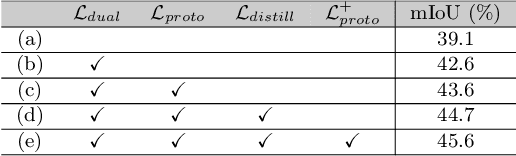
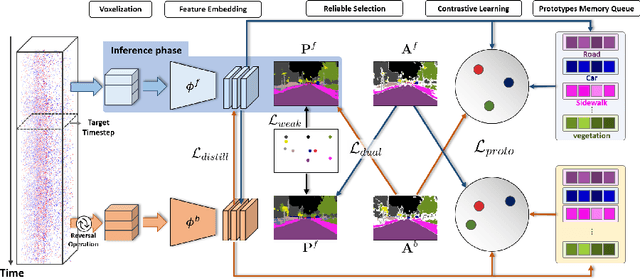
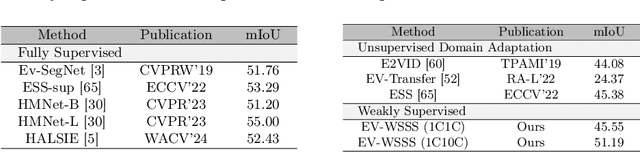
Event cameras excel in capturing high-contrast scenes and dynamic objects, offering a significant advantage over traditional frame-based cameras. Despite active research into leveraging event cameras for semantic segmentation, generating pixel-wise dense semantic maps for such challenging scenarios remains labor-intensive. As a remedy, we present EV-WSSS: a novel weakly supervised approach for event-based semantic segmentation that utilizes sparse point annotations. To fully leverage the temporal characteristics of event data, the proposed framework performs asymmetric dual-student learning between 1) the original forward event data and 2) the longer reversed event data, which contain complementary information from the past and the future, respectively. Besides, to mitigate the challenges posed by sparse supervision, we propose feature-level contrastive learning based on class-wise prototypes, carefully aggregated at both spatial region and sample levels. Additionally, we further excavate the potential of our dual-student learning model by exchanging prototypes between the two learning paths, thereby harnessing their complementary strengths. With extensive experiments on various datasets, including DSEC Night-Point with sparse point annotations newly provided by this paper, the proposed method achieves substantial segmentation results even without relying on pixel-level dense ground truths. The code and dataset are available at https://github.com/Chohoonhee/EV-WSSS.
Temporal Event Stereo via Joint Learning with Stereoscopic Flow
Jul 15, 2024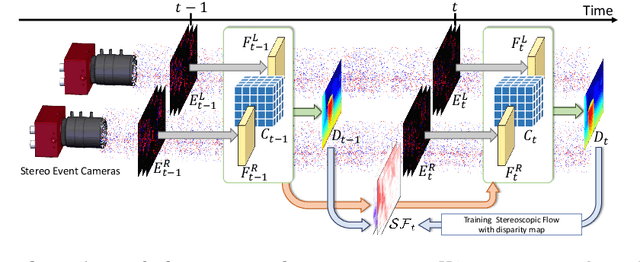
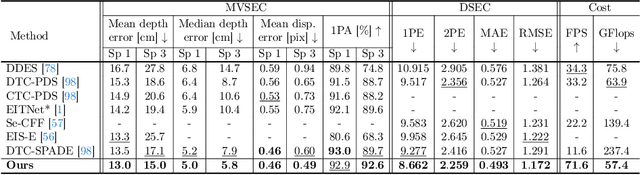
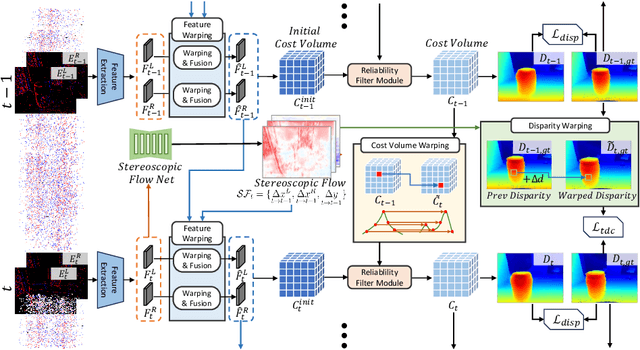
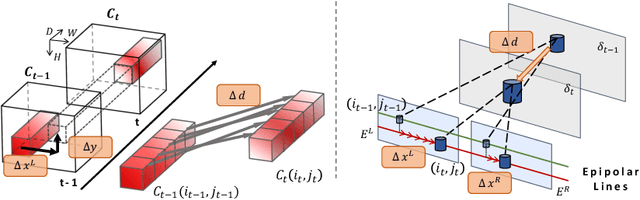
Event cameras are dynamic vision sensors inspired by the biological retina, characterized by their high dynamic range, high temporal resolution, and low power consumption. These features make them capable of perceiving 3D environments even in extreme conditions. Event data is continuous across the time dimension, which allows a detailed description of each pixel's movements. To fully utilize the temporally dense and continuous nature of event cameras, we propose a novel temporal event stereo, a framework that continuously uses information from previous time steps. This is accomplished through the simultaneous training of an event stereo matching network alongside stereoscopic flow, a new concept that captures all pixel movements from stereo cameras. Since obtaining ground truth for optical flow during training is challenging, we propose a method that uses only disparity maps to train the stereoscopic flow. The performance of event-based stereo matching is enhanced by temporally aggregating information using the flows. We have achieved state-of-the-art performance on the MVSEC and the DSEC datasets. The method is computationally efficient, as it stacks previous information in a cascading manner. The code is available at https://github.com/mickeykang16/TemporalEventStereo.
Label-Free Event-based Object Recognition via Joint Learning with Image Reconstruction from Events
Aug 18, 2023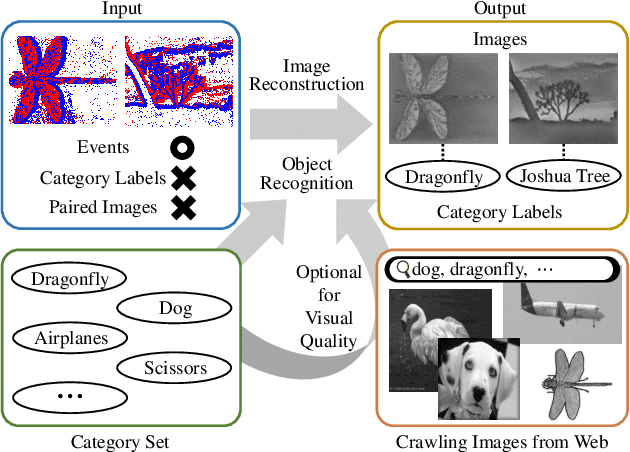
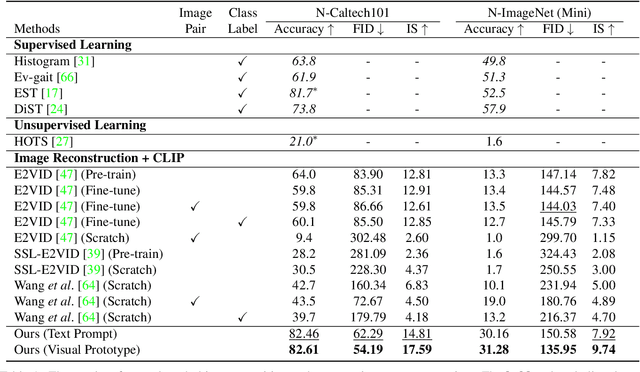
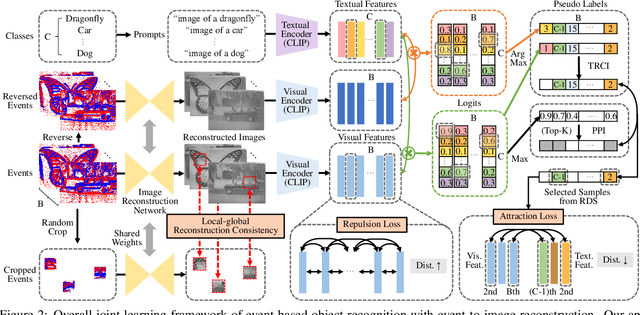
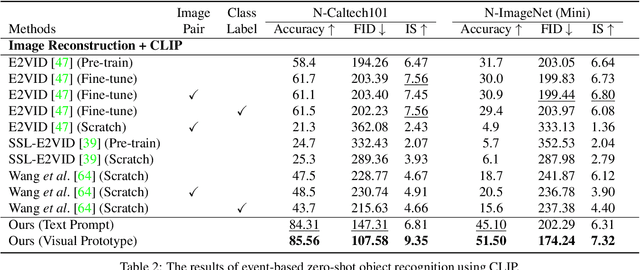
Recognizing objects from sparse and noisy events becomes extremely difficult when paired images and category labels do not exist. In this paper, we study label-free event-based object recognition where category labels and paired images are not available. To this end, we propose a joint formulation of object recognition and image reconstruction in a complementary manner. Our method first reconstructs images from events and performs object recognition through Contrastive Language-Image Pre-training (CLIP), enabling better recognition through a rich context of images. Since the category information is essential in reconstructing images, we propose category-guided attraction loss and category-agnostic repulsion loss to bridge the textual features of predicted categories and the visual features of reconstructed images using CLIP. Moreover, we introduce a reliable data sampling strategy and local-global reconstruction consistency to boost joint learning of two tasks. To enhance the accuracy of prediction and quality of reconstruction, we also propose a prototype-based approach using unpaired images. Extensive experiments demonstrate the superiority of our method and its extensibility for zero-shot object recognition. Our project code is available at \url{https://github.com/Chohoonhee/Ev-LaFOR}.