 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Free Event-based Object Recognition via Joint Learning with Image Reconstruction from Events
Aug 18, 2023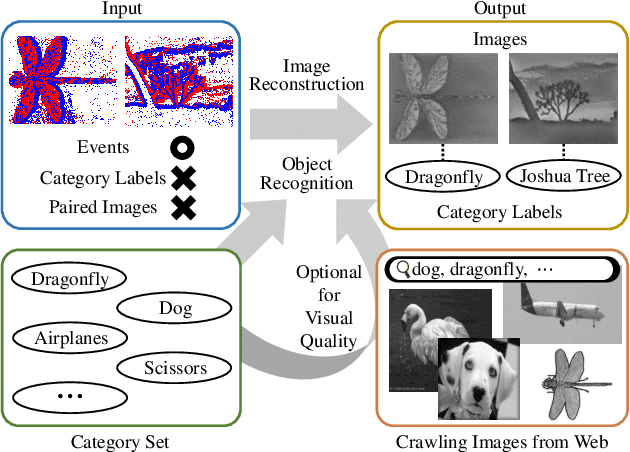
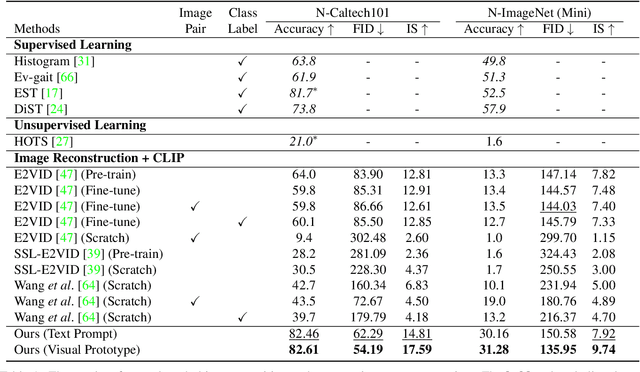
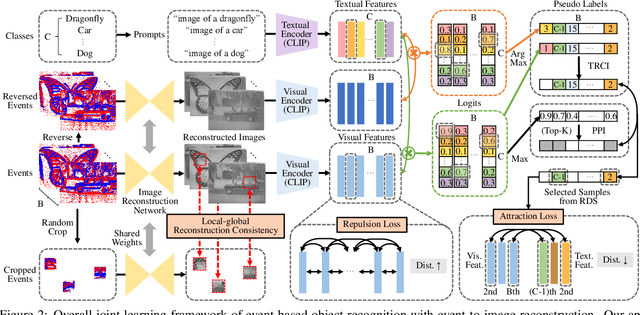
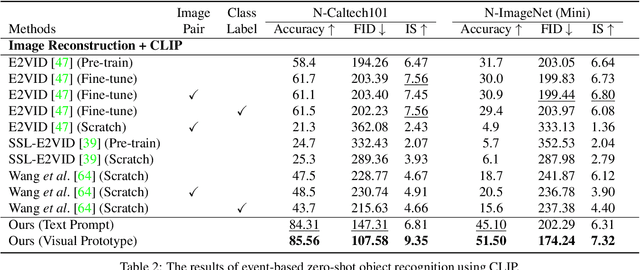
Recognizing objects from sparse and noisy events becomes extremely difficult when paired images and category labels do not exist. In this paper, we study label-free event-based object recognition where category labels and paired images are not available. To this end, we propose a joint formulation of object recognition and image reconstruction in a complementary manner. Our method first reconstructs images from events and performs object recognition through Contrastive Language-Image Pre-training (CLIP), enabling better recognition through a rich context of images. Since the category information is essential in reconstructing images, we propose category-guided attraction loss and category-agnostic repulsion loss to bridge the textual features of predicted categories and the visual features of reconstructed images using CLIP. Moreover, we introduce a reliable data sampling strategy and local-global reconstruction consistency to boost joint learning of two tasks. To enhance the accuracy of prediction and quality of reconstruction, we also propose a prototype-based approach using unpaired images. Extensive experiments demonstrate the superiority of our method and its extensibility for zero-shot object recognition. Our project code is available at \url{https://github.com/Chohoonhee/Ev-LaFOR}.
BIPS: Bi-modal Indoor Panorama Synthesis via Residual Depth-aided Adversarial Learning
Dec 12, 2021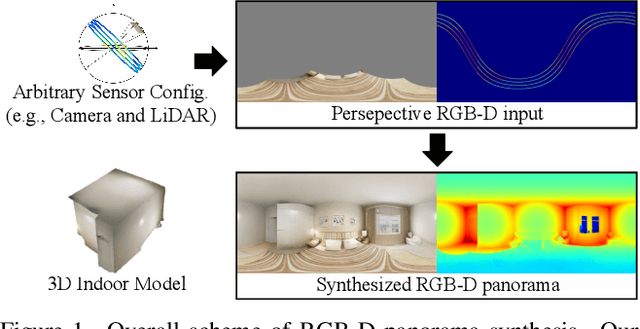
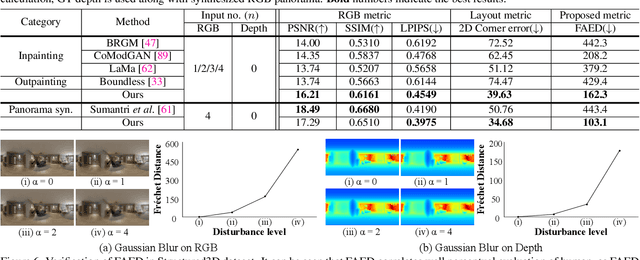
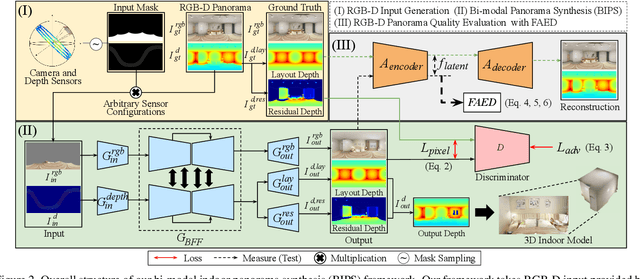
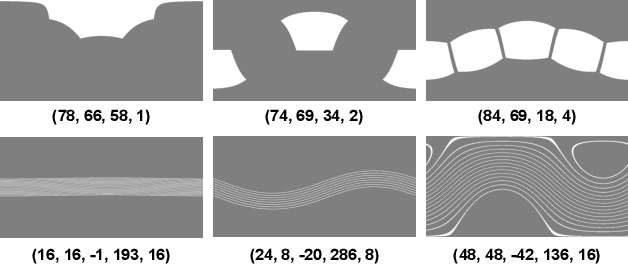
Providing omnidirectional depth along with RGB information is important for numerous applications, eg, VR/AR. However, as omnidirectional RGB-D data is not always available, synthesizing RGB-D panorama data from limited information of a scene can be useful. Therefore, some prior works tried to synthesize RGB panorama images from perspective RGB images; however, they suffer from limited image quality and can not be directly extended for RGB-D panorama synthesis. In this paper, we study a new problem: RGB-D panorama synthesis under the arbitrary configurations of cameras and depth sensors. Accordingly, we propose a novel bi-modal (RGB-D) panorama synthesis (BIPS) framework. Especially, we focus on indoor environments where the RGB-D panorama can provide a complete 3D model for many applications. We design a generator that fuses the bi-modal information and train it with residual-aided adversarial learning (RDAL). RDAL allows to synthesize realistic indoor layout structures and interiors by jointly inferring RGB panorama, layout depth, and residual depth. In addition, as there is no tailored evaluation metric for RGB-D panorama synthesis, we propose a novel metric to effectively evaluate its perceptual quality. Extensive experiments show that our method synthesizes high-quality indoor RGB-D panoramas and provides realistic 3D indoor models than prior methods. Code will be released upon acceptance.
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation
Nov 24, 2021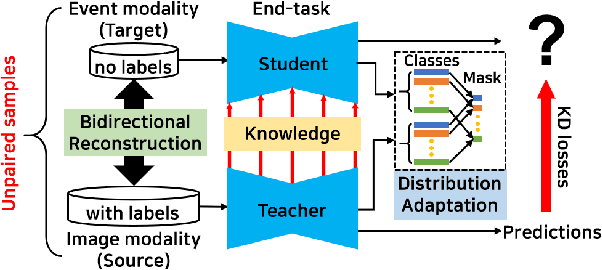

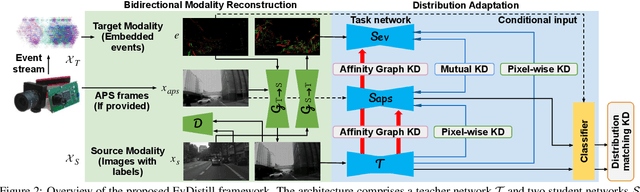

Event cameras sense per-pixel intensity changes and produce asynchronous event streams with high dynamic range and less motion blur, showing advantages over conventional cameras. A hurdle of training event-based models is the lack of large qualitative labeled data. Prior works learning end-tasks mostly rely on labeled or pseudo-labeled datasets obtained from the active pixel sensor (APS) frames; however, such datasets' quality is far from rivaling those based on the canonical images. In this paper, we propose a novel approach, called \textbf{EvDistill}, to learn a student network on the unlabeled and unpaired event data (target modality) via knowledge distillation (KD) from a teacher network trained with large-scale, labeled image data (source modality). To enable KD across the unpaired modalities, we first propose a bidirectional modality reconstruction (BMR) module to bridge both modalities and simultaneously exploit them to distill knowledge via the crafted pairs, causing no extra computation in the inference. The BMR is improved by the end-tasks and KD losses in an end-to-end manner. Second, we leverage the structural similarities of both modalities and adapt the knowledge by matching their distributions. Moreover, as most prior feature KD methods are uni-modality and less applicable to our problem, we propose to leverage an affinity graph KD loss to boost the distillation. Our extensive experiments on semantic segmentation and object recognition demonstrate that EvDistill achieves significantly better results than the prior works and KD with only events and APS frames.
SiamEvent: Event-based Object Tracking via Edge-aware Similarity Learning with Siamese Networks
Sep 28, 2021



Event cameras are novel sensors that perceive the per-pixel intensity changes and output asynchronous event streams, showing lots of advantages over traditional cameras, such as high dynamic range (HDR) and no motion blur. It has been shown that events alone can be used for object tracking by motion compensation or prediction. However, existing methods assume that the target always moves and is the stand-alone object. Moreover, they fail to track the stopped non-independent moving objects on fixed scenes. In this paper, we propose a novel event-based object tracking framework, called SiamEvent, using Siamese networks via edge-aware similarity learning. Importantly, to find the part having the most similar edge structure of target, we propose to correlate the embedded events at two timestamps to compute the target edge similarity. The Siamese network enables tracking arbitrary target edge by finding the part with the highest similarity score. This extends the possibility of event-based object tracking applied not only for the independent stand-alone moving objects, but also for various settings of the camera and scenes. In addition, target edge initialization and edge detector are also proposed to prevent SiamEvent from the drifting problem. Lastly, we built an open dataset including various synthetic and real scenes to train and evaluate SiamEvent. Extensive experiments demonstrate that SiamEvent achieves up to 15% tracking performance enhancement than the baselines on the real-world scenes and more robust tracking performance in the challenging HDR and motion blur conditions.
Dual Transfer Learning for Event-based End-task Prediction via Pluggable Event to Image Translation
Sep 04, 2021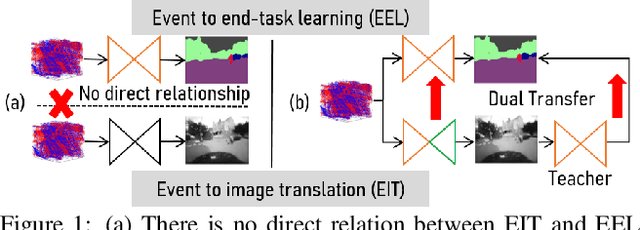



Event cameras are novel sensors that perceive the per-pixel intensity changes and output asynchronous event streams with high dynamic range and less motion blur. It has been shown that events alone can be used for end-task learning, \eg, semantic segmentation, based on encoder-decoder-like networks. However, as events are sparse and mostly reflect edge information, it is difficult to recover original details merely relying on the decoder. Moreover, most methods resort to pixel-wise loss alone for supervision, which might be insufficient to fully exploit the visual details from sparse events, thus leading to less optimal performance. In this paper, we propose a simple yet flexible two-stream framework named Dual Transfer Learning (DTL) to effectively enhance the performance on the end-tasks without adding extra inference cost. The proposed approach consists of three parts: event to end-task learning (EEL) branch, event to image translation (EIT) branch, and transfer learning (TL) module that simultaneously explores the feature-level affinity information and pixel-level knowledge from the EIT branch to improve the EEL branch. This simple yet novel method leads to strong representation learning from events and is evidenced by the significant performance boost on the end-tasks such as semantic segmentation and depth estimation.