 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Active Learning for Long-tail Trajectory Prediction via Controllable Diffusion Model
Jul 30, 2025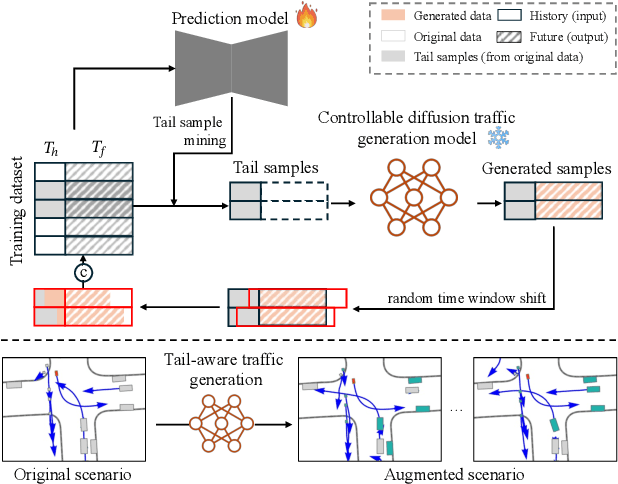

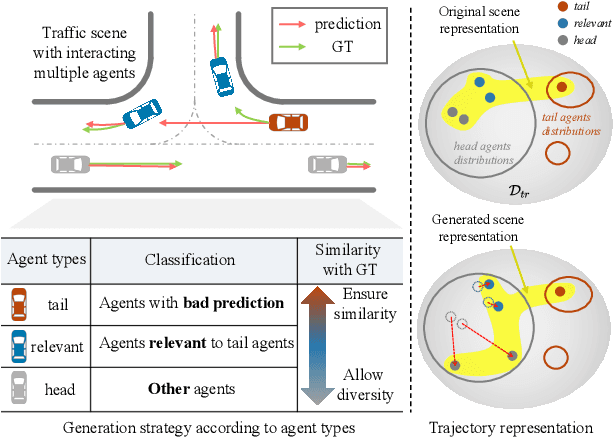
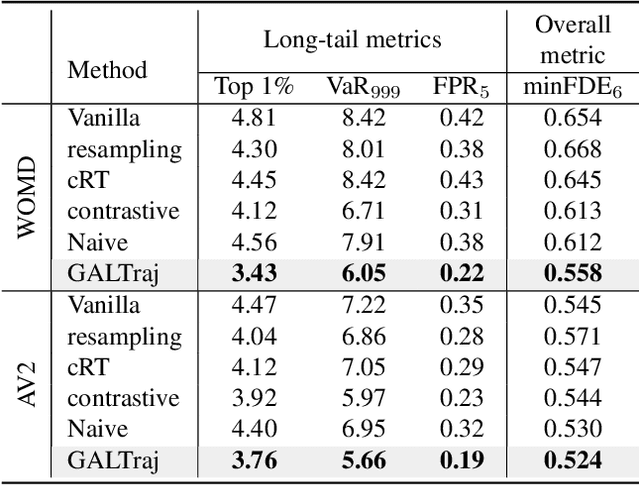
While data-driven trajectory prediction has enhanced the reliability of autonomous driving systems, it still struggles with rarely observed long-tail scenarios. Prior works addressed this by modifying model architectures, such as using hypernetworks. In contrast, we propose refining the training process to unlock each model's potential without altering its structure. We introduce Generative Active Learning for Trajectory prediction (GALTraj), the first method to successfully deploy generative active learning into trajectory prediction. It actively identifies rare tail samples where the model fails and augments these samples with a controllable diffusion model during training. In our framework, generating scenarios that are diverse, realistic, and preserve tail-case characteristics is paramount. Accordingly, we design a tail-aware generation method that applies tailored diffusion guidance to generate trajectories that both capture rare behaviors and respect traffic rules. Unlike prior simulation methods focused solely on scenario diversity, GALTraj is the first to show how simulator-driven augmentation benefits long-tail learning in trajectory prediction. Experiments on multiple trajectory datasets (WOMD, Argoverse2) with popular backbones (QCNet, MTR) confirm that our method significantly boosts performance on tail samples and also enhances accuracy on head samples.
Non-differentiable Reward Optimization for Diffusion-based Autonomous Motion Planning
Jul 17, 2025
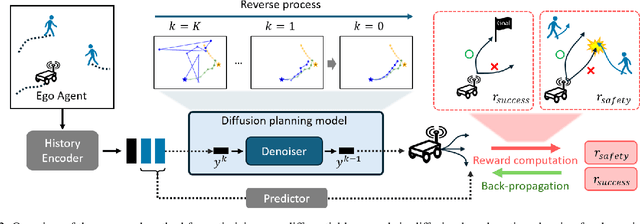
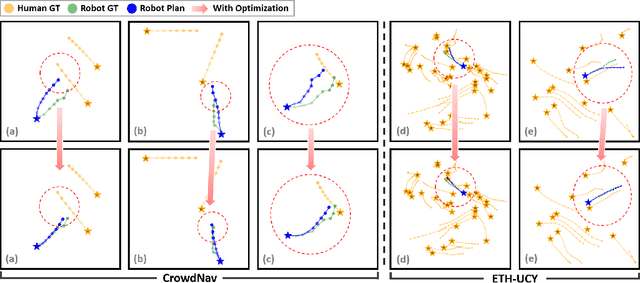

Safe and effective motion planning is crucial for autonomous robots. Diffusion models excel at capturing complex agent interactions, a fundamental aspect of decision-making in dynamic environments. Recent studies have successfully applied diffusion models to motion planning, demonstrating their competence in handling complex scenarios and accurately predicting multi-modal future trajectories. Despite their effectiveness, diffusion models have limitations in training objectives, as they approximate data distributions rather than explicitly capturing the underlying decision-making dynamics. However, the crux of motion planning lies in non-differentiable downstream objectives, such as safety (collision avoidance) and effectiveness (goal-reaching), which conventional learning algorithms cannot directly optimize. In this paper, we propose a reinforcement learning-based training scheme for diffusion motion planning models, enabling them to effectively learn non-differentiable objectives that explicitly measure safety and effectiveness. Specifically, we introduce a reward-weighted dynamic thresholding algorithm to shape a dense reward signal, facilitating more effective training and outperforming models trained with differentiable objectives. State-of-the-art performance on pedestrian datasets (CrowdNav, ETH-UCY) compared to various baselines demonstrates the versatility of our approach for safe and effective motion planning.
Multi-modal Knowledge Distillation-based Human Trajectory Forecasting
Mar 28, 2025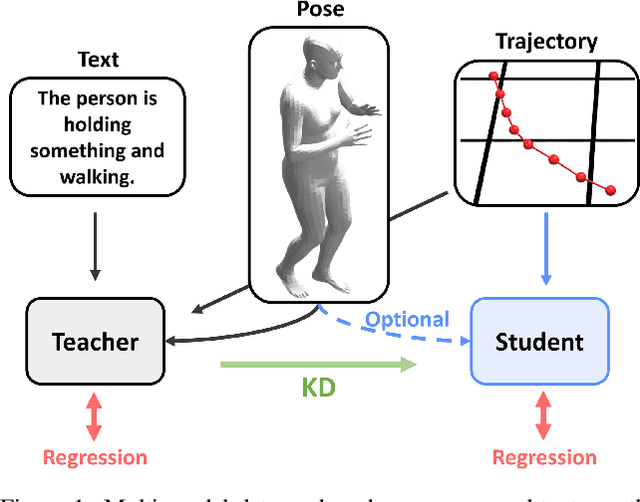

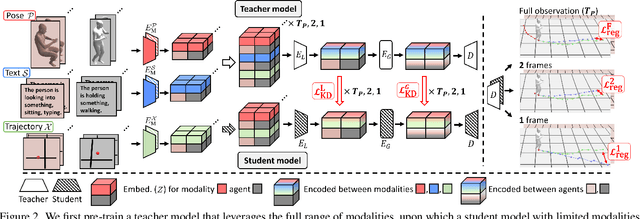

Pedestrian trajectory forecasting is crucial in various applications such as autonomous driving and mobile robot navigation. In such applications, camera-based perception enables the extraction of additional modalities (human pose, text) to enhance prediction accuracy. Indeed, we find that textual descriptions play a crucial role in integrating additional modalities into a unified understanding. However, online extraction of text requires the use of VLM, which may not be feasible for resource-constrained systems. To address this challenge, we propose a multi-modal knowledge distillation framework: a student model with limited modality is distilled from a teacher model trained with full range of modalities. The comprehensive knowledge of a teacher model trained with trajectory, human pose, and text is distilled into a student model using only trajectory or human pose as a sole supplement. In doing so, we separately distill the core locomotion insights from intra-agent multi-modality and inter-agent interaction. Our generalizable framework is validated with two state-of-the-art models across three datasets on both ego-view (JRDB, SIT) and BEV-view (ETH/UCY) setups, utilizing both annotated and VLM-generated text captions. Distilled student models show consistent improvement in all prediction metrics for both full and instantaneous observations, improving up to ~13%. The code is available at https://github.com/Jaewoo97/KDTF.
Multi-agent Long-term 3D Human Pose Forecasting via Interaction-aware Trajectory Conditioning
Apr 08, 2024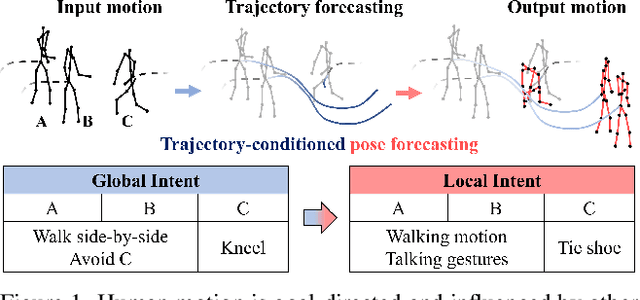
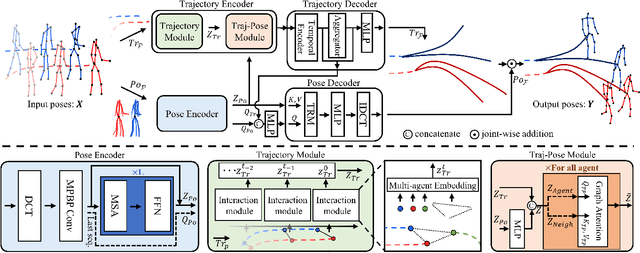
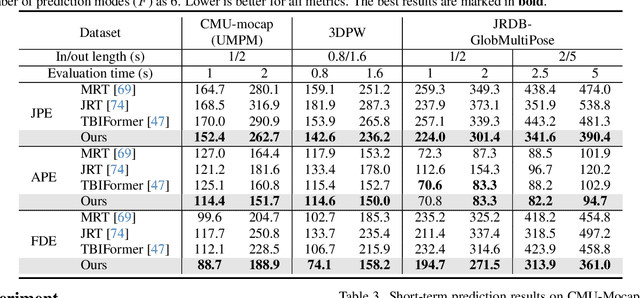
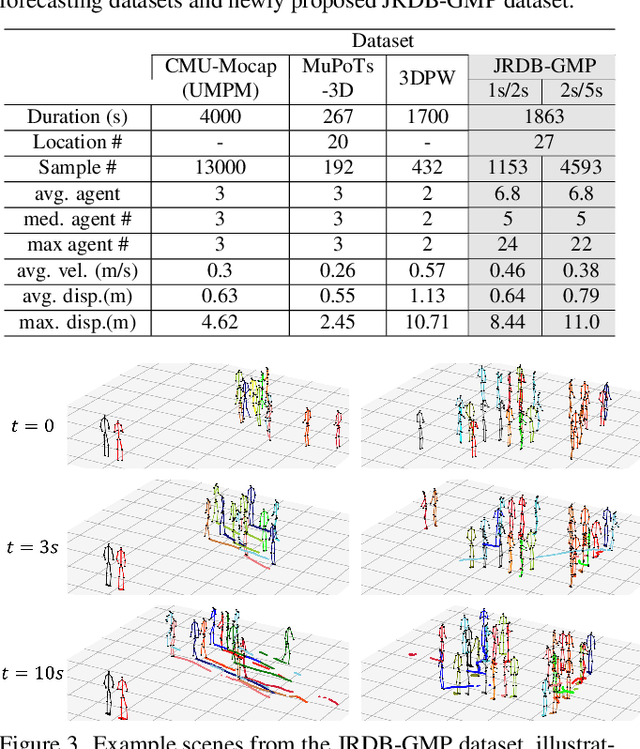
Human pose forecasting garners attention for its diverse applications. However, challenges in modeling the multi-modal nature of human motion and intricate interactions among agents persist, particularly with longer timescales and more agents. In this paper, we propose an interaction-aware trajectory-conditioned long-term multi-agent human pose forecasting model, utilizing a coarse-to-fine prediction approach: multi-modal global trajectories are initially forecasted, followed by respective local pose forecasts conditioned on each mode. In doing so, our Trajectory2Pose model introduces a graph-based agent-wise interaction module for a reciprocal forecast of local motion-conditioned global trajectory and trajectory-conditioned local pose. Our model effectively handles the multi-modality of human motion and the complexity of long-term multi-agent interactions, improving performance in complex environments. Furthermore, we address the lack of long-term (6s+) multi-agent (5+) datasets by constructing a new dataset from real-world images and 2D annotations, enabling a comprehensive evaluation of our proposed model. State-of-the-art prediction performance on both complex and simpler datasets confirms the generalized effectiveness of our method. The code is available at https://github.com/Jaewoo97/T2P.
T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
Mar 15, 2024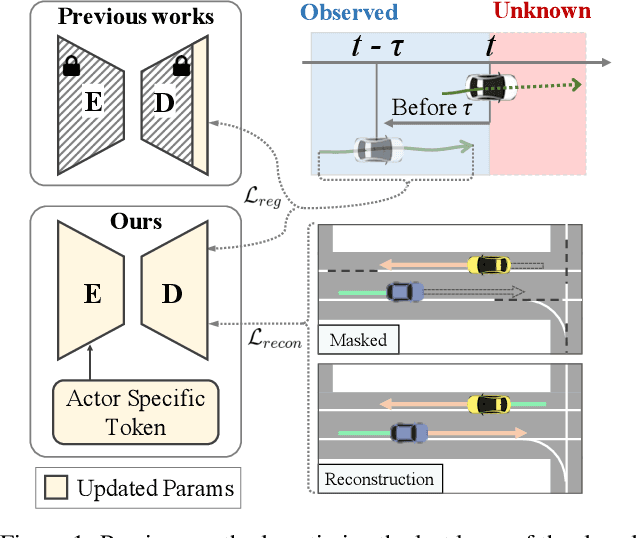
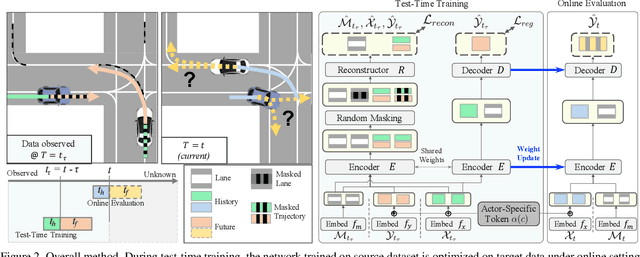
Trajectory prediction is a challenging problem that requires considering interactions among multiple actors and the surrounding environment. While data-driven approaches have been used to address this complex problem, they suffer from unreliable predictions under distribution shifts during test time. Accordingly, several online learning methods have been proposed using regression loss from the ground truth of observed data leveraging the auto-labeling nature of trajectory prediction task. We mainly tackle the following two issues. First, previous works underfit and overfit as they only optimize the last layer of the motion decoder. To this end, we employ the masked autoencoder (MAE) for representation learning to encourage complex interaction modeling in shifted test distribution for updating deeper layers. Second, utilizing the sequential nature of driving data, we propose an actor-specific token memory that enables the test-time learning of actor-wise motion characteristics. Our proposed method has been validated across various challenging cross-dataset distribution shift scenarios including nuScenes, Lyft, Waymo, and Interaction. Our method surpasses the performance of existing state-of-the-art online learning methods in terms of both prediction accuracy and computational efficiency. The code is available at https://github.com/daeheepark/T4P.
Improving Transferability for Cross-domain Trajectory Prediction via Neural Stochastic Differential Equation
Dec 26, 2023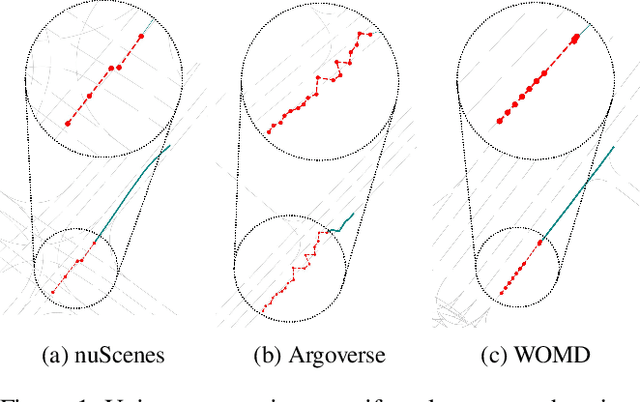
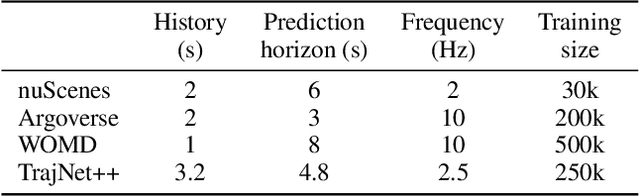
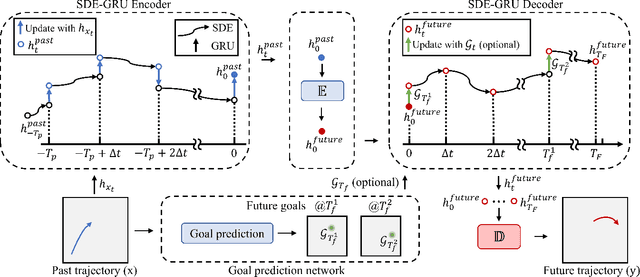
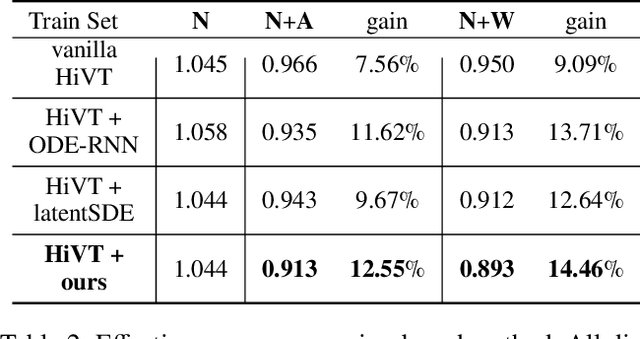
Multi-agent trajectory prediction is crucial for various practical applications, spurring the construction of many large-scale trajectory datasets, including vehicles and pedestrians. However, discrepancies exist among datasets due to external factors and data acquisition strategies. External factors include geographical differences and driving styles, while data acquisition strategies include data acquisition rate, history/prediction length, and detector/tracker error. Consequently, the proficient performance of models trained on large-scale datasets has limited transferability on other small-size datasets, bounding the utilization of existing large-scale datasets. To address this limitation, we propose a method based on continuous and stochastic representations of Neural Stochastic Differential Equations (NSDE) for alleviating discrepancies due to data acquisition strategy. We utilize the benefits of continuous representation for handling arbitrary time steps and the use of stochastic representation for handling detector/tracker errors. Additionally, we propose a dataset-specific diffusion network and its training framework to handle dataset-specific detection/tracking errors. The effectiveness of our method is validated against state-of-the-art trajectory prediction models on the popular benchmark datasets: nuScenes, Argoverse, Lyft, INTERACTION, and Waymo Open Motion Dataset (WOMD). Improvement in performance gain on various source and target dataset configurations shows the generalized competence of our approach in addressing cross-dataset discrepancies.
Leveraging Future Relationship Reasoning for Vehicle Trajectory Prediction
May 24, 2023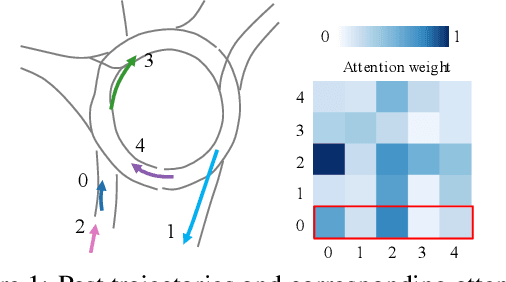
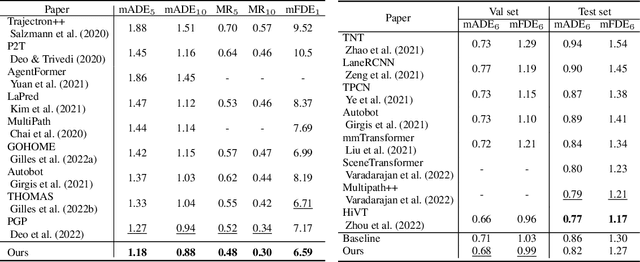
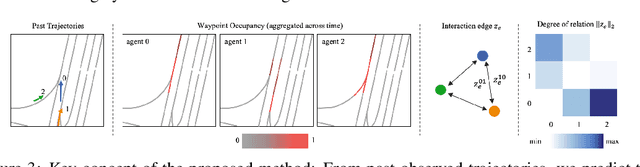
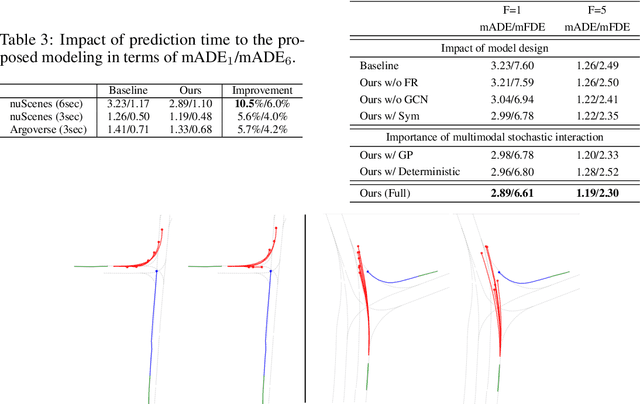
Understanding the interaction between multiple agents is crucial for realistic vehicle trajectory prediction. Existing methods have attempted to infer the interaction from the observed past trajectories of agents using pooling, attention, or graph-based methods, which rely on a deterministic approach. However, these methods can fail under complex road structures, as they cannot predict various interactions that may occur in the future. In this paper, we propose a novel approach that uses lane information to predict a stochastic future relationship among agents. To obtain a coarse future motion of agents, our method first predicts the probability of lane-level waypoint occupancy of vehicles. We then utilize the temporal probability of passing adjacent lanes for each agent pair, assuming that agents passing adjacent lanes will highly interact. We also model the interaction using a probabilistic distribution, which allows for multiple possible future interactions. The distribution is learned from the posterior distribution of interaction obtained from ground truth future trajectories. We validate our method on popular trajectory prediction datasets: nuScenes and Argoverse. The results show that the proposed method brings remarkable performance gain in prediction accuracy, and achieves state-of-the-art performance in long-term prediction benchmark dataset.
Sub-Chain Beam for mmWave Devices: A Trade-off between Power Saving and Beam Correspondence
Dec 23, 2021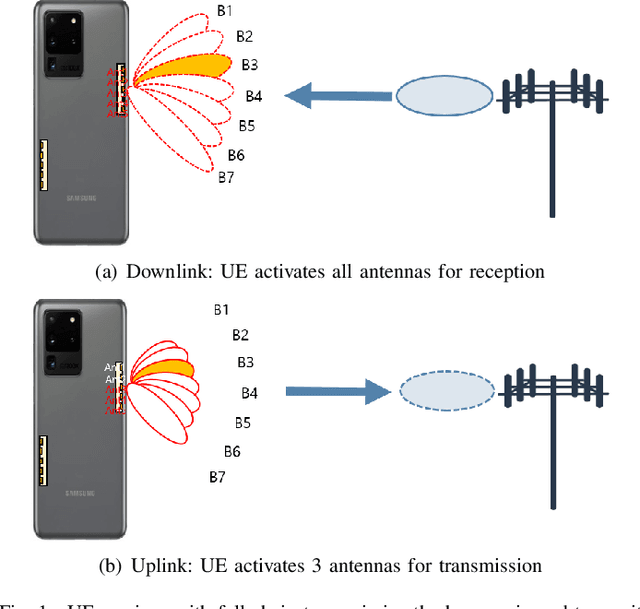
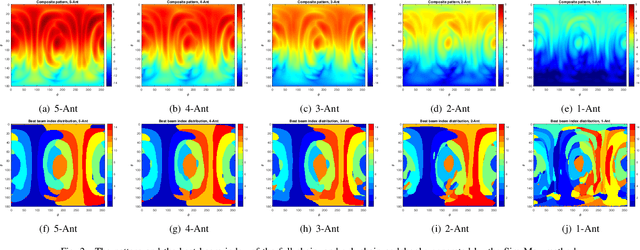
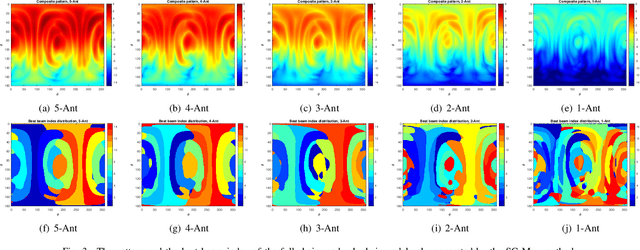
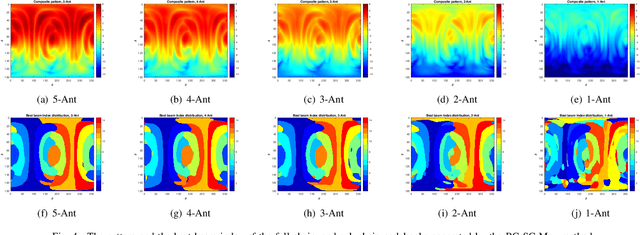
Beam correspondence, or downlink-uplink (DL-UL) beam reciprocity, refers to the assumption that the best beams in the DL are also the best beams in the UL. This is an important assumption that allows the existing beam management framework in 5G to rely heavily on DL beam sweeping and avoid UL beam sweeping: UL beams are inferred from the measurements of the DL reference signals. Beam correspondence holds when the radio configurations are symmetric in the DL and UL. However, as mmWave technology matures, the DL and the UL face different constraints often breaking the beam correspondence. For example, power constraints may require a UE to activate only a portion of its antenna array for UL transmission, while still activating the full array for DL reception. Meanwhile, if the UL beam with sub-array, named as sub-chain beam in this paper, has a similar radiation pattern as the DL beam, the beam correspondence can still hold. This paper proposes methods for sub-chain beam codebook design to achieve a trade-off between the power saving and beam correspondence.
BIPS: Bi-modal Indoor Panorama Synthesis via Residual Depth-aided Adversarial Learning
Dec 12, 2021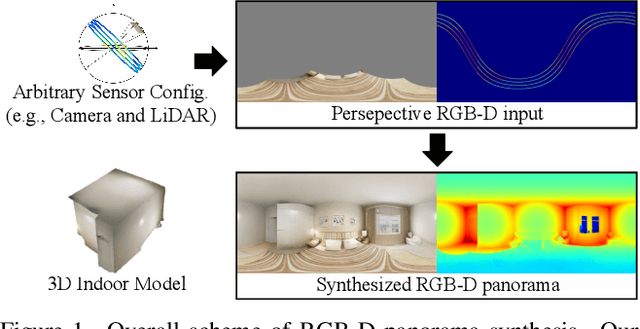
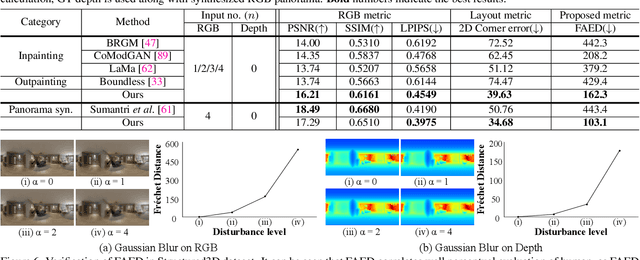
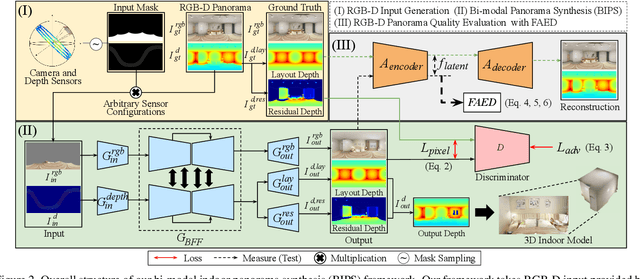
Providing omnidirectional depth along with RGB information is important for numerous applications, eg, VR/AR. However, as omnidirectional RGB-D data is not always available, synthesizing RGB-D panorama data from limited information of a scene can be useful. Therefore, some prior works tried to synthesize RGB panorama images from perspective RGB images; however, they suffer from limited image quality and can not be directly extended for RGB-D panorama synthesis. In this paper, we study a new problem: RGB-D panorama synthesis under the arbitrary configurations of cameras and depth sensors. Accordingly, we propose a novel bi-modal (RGB-D) panorama synthesis (BIPS) framework. Especially, we focus on indoor environments where the RGB-D panorama can provide a complete 3D model for many applications. We design a generator that fuses the bi-modal information and train it with residual-aided adversarial learning (RDAL). RDAL allows to synthesize realistic indoor layout structures and interiors by jointly inferring RGB panorama, layout depth, and residual depth. In addition, as there is no tailored evaluation metric for RGB-D panorama synthesis, we propose a novel metric to effectively evaluate its perceptual quality. Extensive experiments show that our method synthesizes high-quality indoor RGB-D panoramas and provides realistic 3D indoor models than prior methods. Code will be released upon acceptance.