 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowBlending: Stage-Aware Multi-Model Sampling for Fast and High-Fidelity Video Generation
Dec 31, 2025In this work, we show that the impact of model capacity varies across timesteps: it is crucial for the early and late stages but largely negligible during the intermediate stage. Accordingly, we propose FlowBlending, a stage-aware multi-model sampling strategy that employs a large model and a small model at capacity-sensitive stages and intermediate stages, respectively. We further introduce simple criteria to choose stage boundaries and provide a velocity-divergence analysis as an effective proxy for identifying capacity-sensitive regions. Across LTX-Video (2B/13B) and WAN 2.1 (1.3B/14B), FlowBlending achieves up to 1.65x faster inference with 57.35% fewer FLOPs, while maintaining the visual fidelity, temporal coherence, and semantic alignment of the large models. FlowBlending is also compatible with existing sampling-acceleration techniques, enabling up to 2x additional speedup. Project page is available at: https://jibin86.github.io/flowblending_project_page.
Towards Real-world Event-guided Low-light Video Enhancement and Deblurring
Aug 27, 2024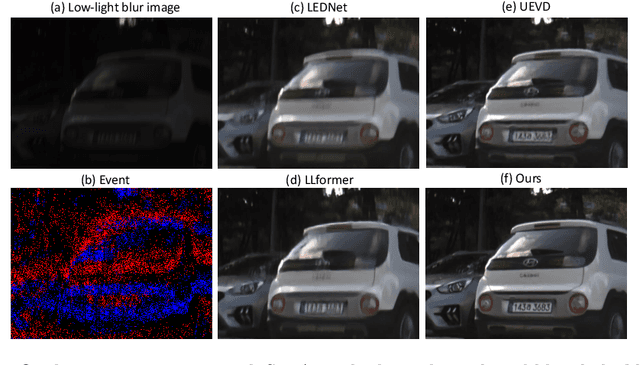

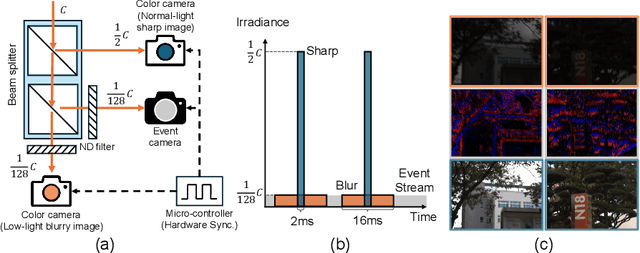
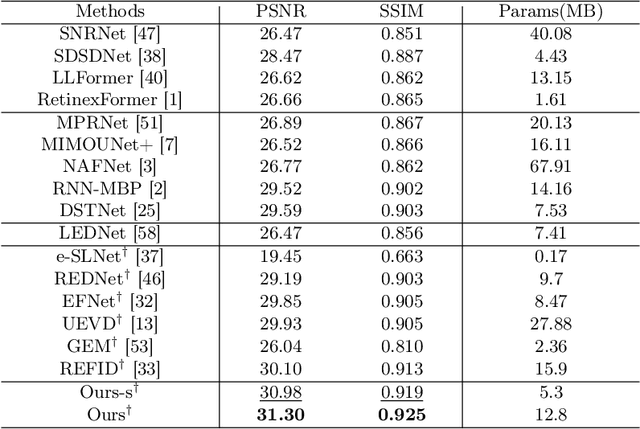
In low-light conditions, capturing videos with frame-based cameras often requires long exposure times, resulting in motion blur and reduced visibility. While frame-based motion deblurring and low-light enhancement have been studied, they still pose significant challenges. Event cameras have emerged as a promising solution for improving image quality in low-light environments and addressing motion blur. They provide two key advantages: capturing scene details well even in low light due to their high dynamic range, and effectively capturing motion information during long exposures due to their high temporal resolution. Despite efforts to tackle low-light enhancement and motion deblurring using event cameras separately, previous work has not addressed both simultaneously. To explore the joint task, we first establish real-world datasets for event-guided low-light enhancement and deblurring using a hybrid camera system based on beam splitters. Subsequently, we introduce an end-to-end framework to effectively handle these tasks. Our framework incorporates a module to efficiently leverage temporal information from events and frames. Furthermore, we propose a module to utilize cross-modal feature information to employ a low-pass filter for noise suppression while enhancing the main structural information. Our proposed method significantly outperforms existing approaches in addressing the joint task. Our project pages are available at https://github.com/intelpro/ELEDNet.
T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
Mar 15, 2024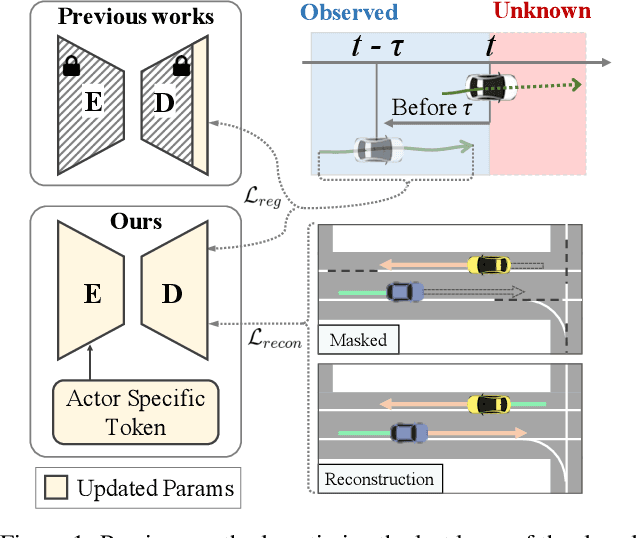
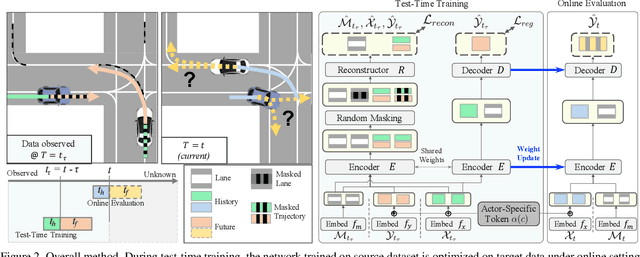
Trajectory prediction is a challenging problem that requires considering interactions among multiple actors and the surrounding environment. While data-driven approaches have been used to address this complex problem, they suffer from unreliable predictions under distribution shifts during test time. Accordingly, several online learning methods have been proposed using regression loss from the ground truth of observed data leveraging the auto-labeling nature of trajectory prediction task. We mainly tackle the following two issues. First, previous works underfit and overfit as they only optimize the last layer of the motion decoder. To this end, we employ the masked autoencoder (MAE) for representation learning to encourage complex interaction modeling in shifted test distribution for updating deeper layers. Second, utilizing the sequential nature of driving data, we propose an actor-specific token memory that enables the test-time learning of actor-wise motion characteristics. Our proposed method has been validated across various challenging cross-dataset distribution shift scenarios including nuScenes, Lyft, Waymo, and Interaction. Our method surpasses the performance of existing state-of-the-art online learning methods in terms of both prediction accuracy and computational efficiency. The code is available at https://github.com/daeheepark/T4P.
Visual Style Prompting with Swapping Self-Attention
Feb 21, 2024In the evolving domain of text-to-image generation, diffusion models have emerged as powerful tools in content creation. Despite their remarkable capability, existing models still face challenges in achieving controlled generation with a consistent style, requiring costly fine-tuning or often inadequately transferring the visual elements due to content leakage. To address these challenges, we propose a novel approach, \ours, to produce a diverse range of images while maintaining specific style elements and nuances. During the denoising process, we keep the query from original features while swapping the key and value with those from reference features in the late self-attention layers. This approach allows for the visual style prompting without any fine-tuning, ensuring that generated images maintain a faithful style. Through extensive evaluation across various styles and text prompts, our method demonstrates superiority over existing approaches, best reflecting the style of the references and ensuring that resulting images match the text prompts most accurately. Our project page is available https://curryjung.github.io/VisualStylePrompt/.
Training-free Style Transfer Emerges from h-space in Diffusion models
Mar 27, 2023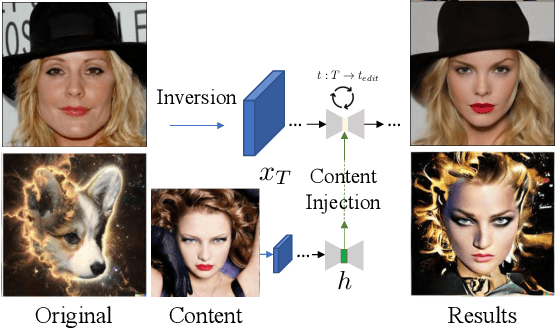
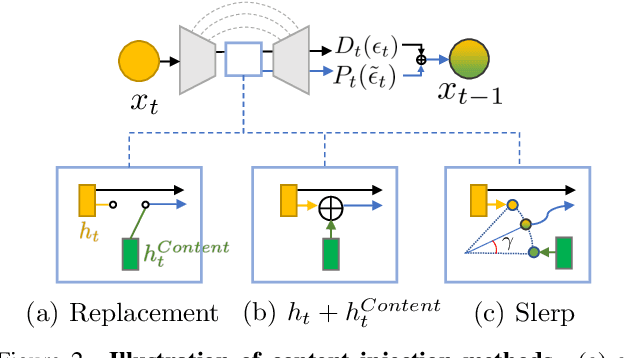


Diffusion models (DMs) synthesize high-quality images in various domains. However, controlling their generative process is still hazy because the intermediate variables in the process are not rigorously studied. Recently, StyleCLIP-like editing of DMs is found in the bottleneck of the U-Net, named $h$-space. In this paper, we discover that DMs inherently have disentangled representations for content and style of the resulting images: $h$-space contains the content and the skip connections convey the style. Furthermore, we introduce a principled way to inject content of one image to another considering progressive nature of the generative process. Briefly, given the original generative process, 1) the feature of the source content should be gradually blended, 2) the blended feature should be normalized to preserve the distribution, 3) the change of skip connections due to content injection should be calibrated. Then, the resulting image has the source content with the style of the original image just like image-to-image translation. Interestingly, injecting contents to styles of unseen domains produces harmonization-like style transfer. To the best of our knowledge, our method introduces the first training-free feed-forward style transfer only with an unconditional pretrained frozen generative network. The code is available at https://curryjung.github.io/DiffStyle/.
Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation
Dec 10, 2021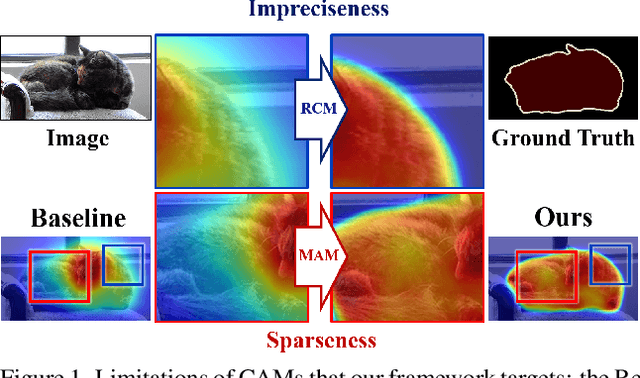
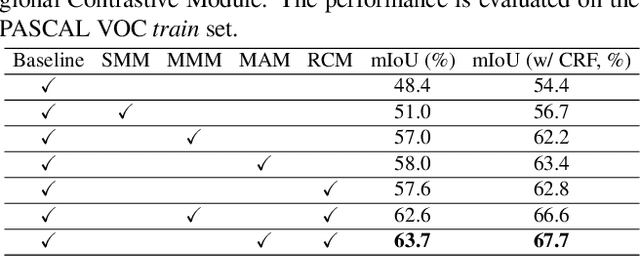
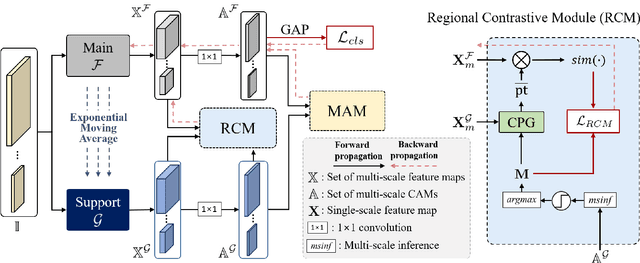
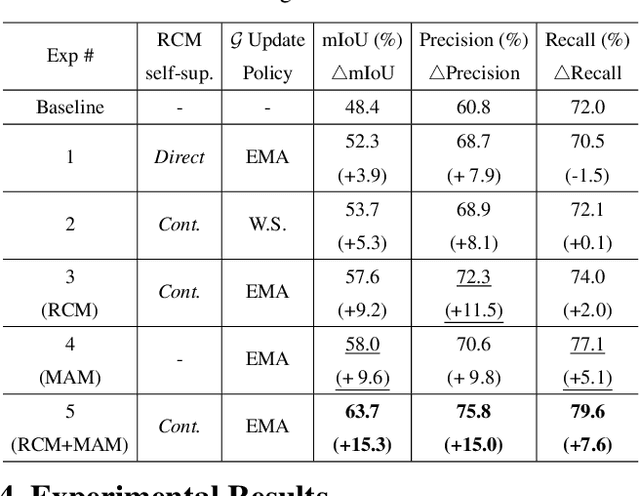
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects. However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness). To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision. In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet. The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks. Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs. The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet. Based on the dissimilarity between the multi-scale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions. The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset. For reproducibility, code will be available publicly soon.
SpherePHD: Applying CNNs on a Spherical PolyHeDron Representation of 360 degree Images
Nov 20, 2018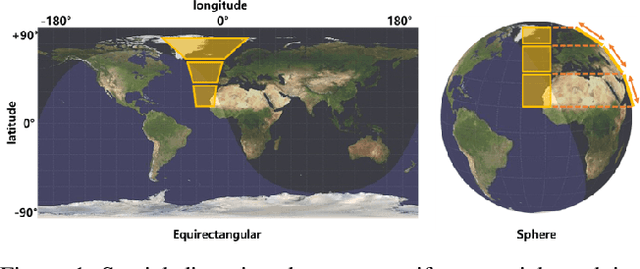
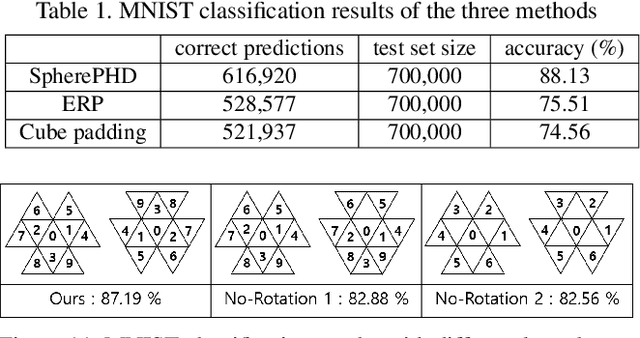

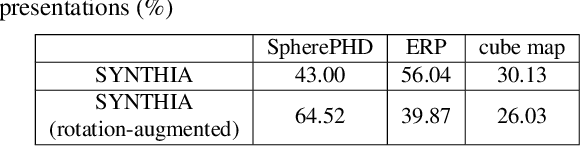
Omni-directional cameras have many advantages over conventional cameras in that they have a much wider field-of-view (FOV). Several approaches have been recently proposed to apply convolutional neural networks (CNNs) to omni-directional images to solve classification and detection problems. However, most of them use image representations in the Euclidean space defined by transforming the omni-directional views originally in the non-Euclidean space. This transformation leads to shape distortion due to nonuniform spatial resolving power and loss of continuity. These effects make existing convolution kernels have difficulties in extracting meaningful information. This paper proposes a novel method to resolve the aforementioned problems of applying CNNs to omni-directional images. The proposed method utilizes a spherical polyhedron to represent omni-directional views. This method minimizes the variance of spatial resolving power on the sphere surface, and includes new convolution and pooling methods for the proposed representation. The proposed approach can also be adopted by existing CNN-based methods. The feasibility and efficacy of the proposed method is demonstrated through both classification and detection tasks.