 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report for ICRA 2026 GOOSE 2D Fine-Grained Semantic Segmentation Challenge: Leveraging DINOv3 for Robust Outdoor Scene Understanding in Field Robotics
Jun 17, 2026The GOOSE 2D Fine-Grained Semantic Segmentation Challenge at the ICRA 2026 Workshop on Field Robotics evaluates dense semantic segmentation of off-road imagery over a fine-grained taxonomy of 64 classes and 11 evaluated non-void coarse categories. We present the first-place solution to this challenge. Our solution comprises two complementary improvements: (a) a network-level design that combines a self-supervised DINOv3 ViT-L/16 backbone, a ViT-Adapter, and a Mask2Former mask-classification decoder, together with a coarse-category auxiliary loss on the global [CLS] token; and (b) an inference-time aggregation strategy based on multi-scale and horizontal-flip test-time augmentation and an ensemble of the top three checkpoints selected using Codabench scores. Our method achieves an official composite score of 76.57%, consisting of 69.32% fine-class mIoU and 83.81% category-level mIoU, and ranks first on the final phase leaderboard: www.codabench.org/competitions/14257/#/results-tab.
TrailBlazer: History-Guided Reinforcement Learning for Black-Box LLM Jailbreaking
Feb 06, 2026Large Language Models (LLMs) have become integral to many domains, making their safety a critical priority. Prior jailbreaking research has explored diverse approaches, including prompt optimization, automated red teaming, obfuscation, and reinforcement learning (RL) based methods. However, most existing techniques fail to effectively leverage vulnerabilities revealed in earlier interaction turns, resulting in inefficient and unstable attacks. Since jailbreaking involves sequential interactions in which each response influences future actions, reinforcement learning provides a natural framework for this problem. Motivated by this, we propose a history-aware RL-based jailbreak framework that analyzes and reweights vulnerability signals from prior steps to guide future decisions. We show that incorporating historical information alone improves jailbreak success rates. Building on this insight, we introduce an attention-based reweighting mechanism that highlights critical vulnerabilities within the interaction history, enabling more efficient exploration with fewer queries. Extensive experiments on AdvBench and HarmBench demonstrate that our method achieves state-of-the-art jailbreak performance while significantly improving query efficiency. These results underscore the importance of historical vulnerability signals in reinforcement learning-driven jailbreak strategies and offer a principled pathway for advancing adversarial research on LLM safeguards.
SplitFlow: Flow Decomposition for Inversion-Free Text-to-Image Editing
Oct 29, 2025



Rectified flow models have become a de facto standard in image generation due to their stable sampling trajectories and high-fidelity outputs. Despite their strong generative capabilities, they face critical limitations in image editing tasks: inaccurate inversion processes for mapping real images back into the latent space, and gradient entanglement issues during editing often result in outputs that do not faithfully reflect the target prompt. Recent efforts have attempted to directly map source and target distributions via ODE-based approaches without inversion; however,these methods still yield suboptimal editing quality. In this work, we propose a flow decomposition-and-aggregation framework built upon an inversion-free formulation to address these limitations. Specifically, we semantically decompose the target prompt into multiple sub-prompts, compute an independent flow for each, and aggregate them to form a unified editing trajectory. While we empirically observe that decomposing the original flow enhances diversity in the target space, generating semantically aligned outputs still requires consistent guidance toward the full target prompt. To this end, we design a projection and soft-aggregation mechanism for flow, inspired by gradient conflict resolution in multi-task learning. This approach adaptively weights the sub-target velocity fields, suppressing semantic redundancy while emphasizing distinct directions, thereby preserving both diversity and consistency in the final edited output. Experimental results demonstrate that our method outperforms existing zero-shot editing approaches in terms of semantic fidelity and attribute disentanglement. The code is available at https://github.com/Harvard-AI-and-Robotics-Lab/SplitFlow.
Language-Agnostic Suicidal Risk Detection Using Large Language Models
May 26, 2025Suicidal risk detection in adolescents is a critical challenge, yet existing methods rely on language-specific models, limiting scalability and generalization. This study introduces a novel language-agnostic framework for suicidal risk assessment with large language models (LLMs). We generate Chinese transcripts from speech using an ASR model and then employ LLMs with prompt-based queries to extract suicidal risk-related features from these transcripts. The extracted features are retained in both Chinese and English to enable cross-linguistic analysis and then used to fine-tune corresponding pretrained language models independently. Experimental results show that our method achieves performance comparable to direct fine-tuning with ASR results or to models trained solely on Chinese suicidal risk-related features, demonstrating its potential to overcome language constraints and improve the robustness of suicidal risk assessment.
Domain Adversarial Training for Mitigating Gender Bias in Speech-based Mental Health Detection
May 06, 2025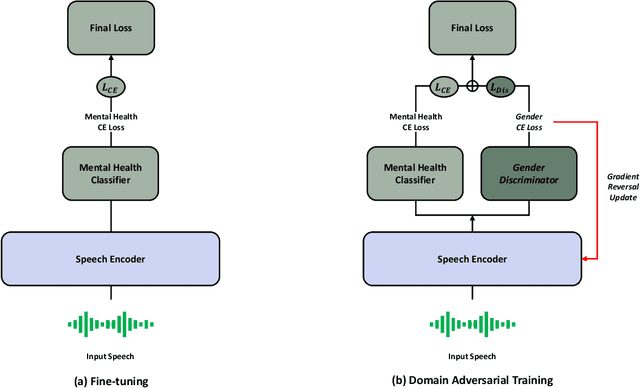



Speech-based AI models are emerging as powerful tools for detecting depression and the presence of Post-traumatic stress disorder (PTSD), offering a non-invasive and cost-effective way to assess mental health. However, these models often struggle with gender bias, which can lead to unfair and inaccurate predictions. In this study, our study addresses this issue by introducing a domain adversarial training approach that explicitly considers gender differences in speech-based depression and PTSD detection. Specifically, we treat different genders as distinct domains and integrate this information into a pretrained speech foundation model. We then validate its effectiveness on the E-DAIC dataset to assess its impact on performance. Experimental results show that our method notably improves detection performance, increasing the F1-score by up to 13.29 percentage points compared to the baseline. This highlights the importance of addressing demographic disparities in AI-driven mental health assessment.
Finding Meaning in Points: Weakly Supervised Semantic Segmentation for Event Cameras
Jul 15, 2024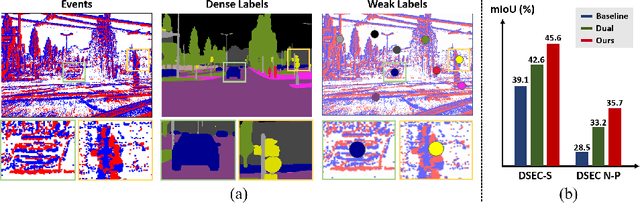
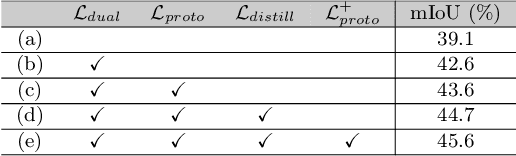
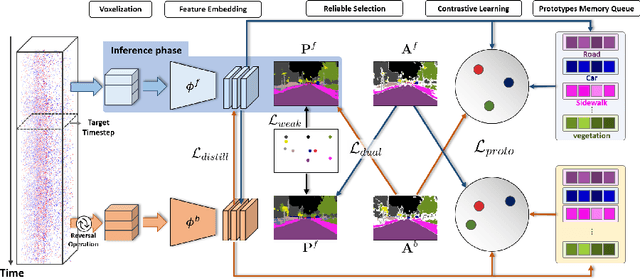
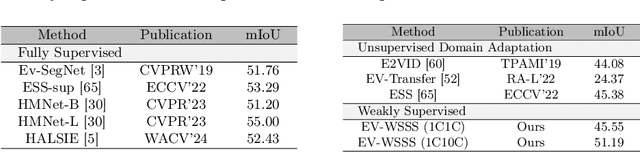
Event cameras excel in capturing high-contrast scenes and dynamic objects, offering a significant advantage over traditional frame-based cameras. Despite active research into leveraging event cameras for semantic segmentation, generating pixel-wise dense semantic maps for such challenging scenarios remains labor-intensive. As a remedy, we present EV-WSSS: a novel weakly supervised approach for event-based semantic segmentation that utilizes sparse point annotations. To fully leverage the temporal characteristics of event data, the proposed framework performs asymmetric dual-student learning between 1) the original forward event data and 2) the longer reversed event data, which contain complementary information from the past and the future, respectively. Besides, to mitigate the challenges posed by sparse supervision, we propose feature-level contrastive learning based on class-wise prototypes, carefully aggregated at both spatial region and sample levels. Additionally, we further excavate the potential of our dual-student learning model by exchanging prototypes between the two learning paths, thereby harnessing their complementary strengths. With extensive experiments on various datasets, including DSEC Night-Point with sparse point annotations newly provided by this paper, the proposed method achieves substantial segmentation results even without relying on pixel-level dense ground truths. The code and dataset are available at https://github.com/Chohoonhee/EV-WSSS.
T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
Mar 15, 2024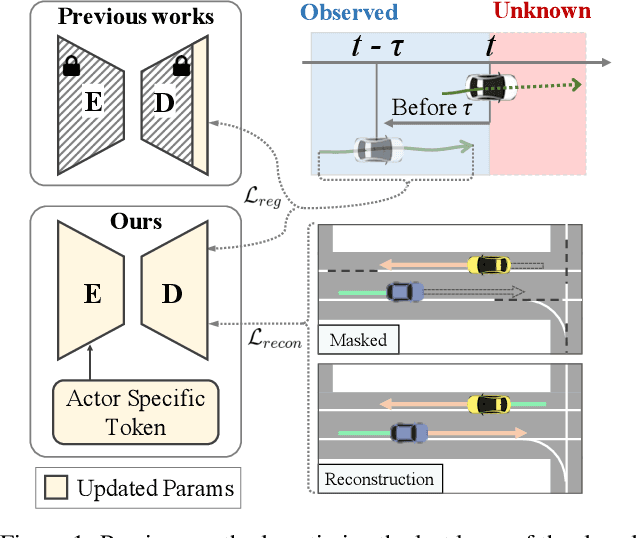
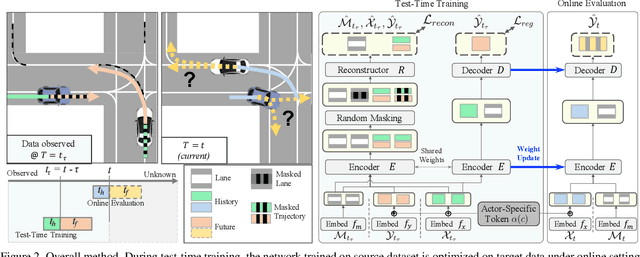
Trajectory prediction is a challenging problem that requires considering interactions among multiple actors and the surrounding environment. While data-driven approaches have been used to address this complex problem, they suffer from unreliable predictions under distribution shifts during test time. Accordingly, several online learning methods have been proposed using regression loss from the ground truth of observed data leveraging the auto-labeling nature of trajectory prediction task. We mainly tackle the following two issues. First, previous works underfit and overfit as they only optimize the last layer of the motion decoder. To this end, we employ the masked autoencoder (MAE) for representation learning to encourage complex interaction modeling in shifted test distribution for updating deeper layers. Second, utilizing the sequential nature of driving data, we propose an actor-specific token memory that enables the test-time learning of actor-wise motion characteristics. Our proposed method has been validated across various challenging cross-dataset distribution shift scenarios including nuScenes, Lyft, Waymo, and Interaction. Our method surpasses the performance of existing state-of-the-art online learning methods in terms of both prediction accuracy and computational efficiency. The code is available at https://github.com/daeheepark/T4P.
Exploring Pixel-level Self-supervision for Weakly Supervised Semantic Segmentation
Dec 10, 2021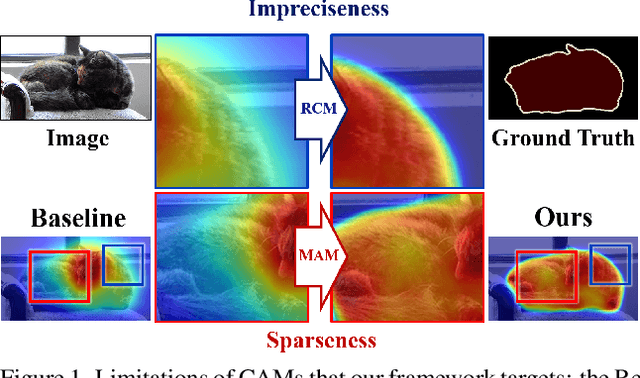
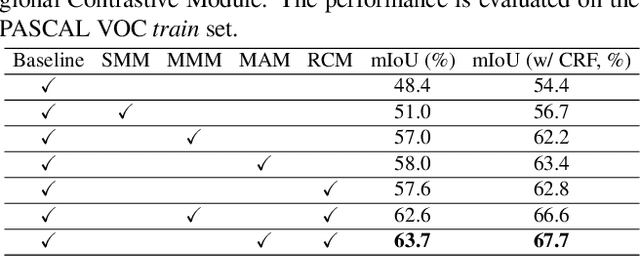
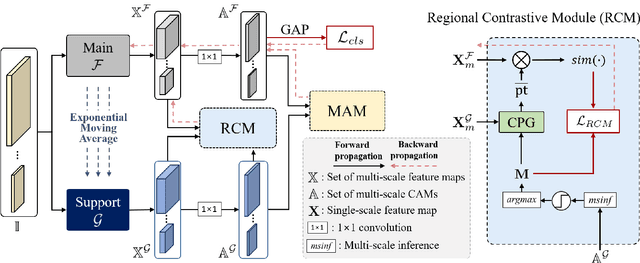
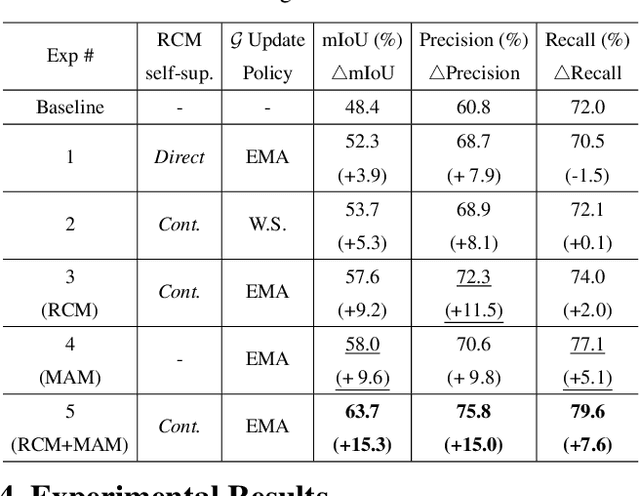
Existing studies in weakly supervised semantic segmentation (WSSS) have utilized class activation maps (CAMs) to localize the class objects. However, since a classification loss is insufficient for providing precise object regions, CAMs tend to be biased towards discriminative patterns (i.e., sparseness) and do not provide precise object boundary information (i.e., impreciseness). To resolve these limitations, we propose a novel framework (composed of MainNet and SupportNet.) that derives pixel-level self-supervision from given image-level supervision. In our framework, with the help of the proposed Regional Contrastive Module (RCM) and Multi-scale Attentive Module (MAM), MainNet is trained by self-supervision from the SupportNet. The RCM extracts two forms of self-supervision from SupportNet: (1) class region masks generated from the CAMs and (2) class-wise prototypes obtained from the features according to the class region masks. Then, every pixel-wise feature of the MainNet is trained by the prototype in a contrastive manner, sharpening the resulting CAMs. The MAM utilizes CAMs inferred at multiple scales from the SupportNet as self-supervision to guide the MainNet. Based on the dissimilarity between the multi-scale CAMs from MainNet and SupportNet, CAMs from the MainNet are trained to expand to the less-discriminative regions. The proposed method shows state-of-the-art WSSS performance both on the train and validation sets on the PASCAL VOC 2012 dataset. For reproducibility, code will be available publicly soon.
EvDistill: Asynchronous Events to End-task Learning via Bidirectional Reconstruction-guided Cross-modal Knowledge Distillation
Nov 24, 2021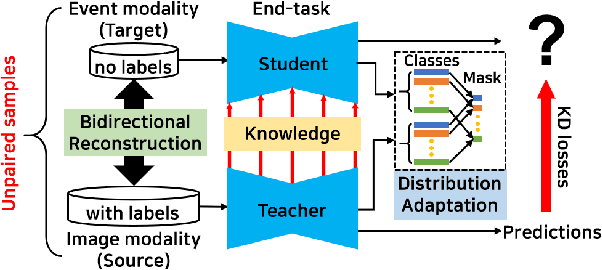

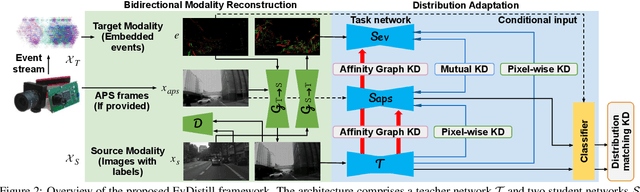

Event cameras sense per-pixel intensity changes and produce asynchronous event streams with high dynamic range and less motion blur, showing advantages over conventional cameras. A hurdle of training event-based models is the lack of large qualitative labeled data. Prior works learning end-tasks mostly rely on labeled or pseudo-labeled datasets obtained from the active pixel sensor (APS) frames; however, such datasets' quality is far from rivaling those based on the canonical images. In this paper, we propose a novel approach, called \textbf{EvDistill}, to learn a student network on the unlabeled and unpaired event data (target modality) via knowledge distillation (KD) from a teacher network trained with large-scale, labeled image data (source modality). To enable KD across the unpaired modalities, we first propose a bidirectional modality reconstruction (BMR) module to bridge both modalities and simultaneously exploit them to distill knowledge via the crafted pairs, causing no extra computation in the inference. The BMR is improved by the end-tasks and KD losses in an end-to-end manner. Second, we leverage the structural similarities of both modalities and adapt the knowledge by matching their distributions. Moreover, as most prior feature KD methods are uni-modality and less applicable to our problem, we propose to leverage an affinity graph KD loss to boost the distillation. Our extensive experiments on semantic segmentation and object recognition demonstrate that EvDistill achieves significantly better results than the prior works and KD with only events and APS frames.