 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCafeMed: Causal Attention Fusion Enhanced Medication Recommendation
Nov 18, 2025Medication recommendation systems play a crucial role in assisting clinicians with personalized treatment decisions. While existing approaches have made significant progress in learning medication representations, they suffer from two fundamental limitations: (i) treating medical entities as independent features without modeling their synergistic effects on medication selection; (ii) employing static causal relationships that fail to adapt to patient-specific contexts and health states. To address these challenges, we propose CafeMed, a framework that integrates dynamic causal reasoning with cross-modal attention for safe and accurate medication recommendation. CafeMed introduces two key components: the Causal Weight Generator (CWG) that transforms static causal effects into dynamic modulation weights based on individual patient states, and the Channel Harmonized Attention Refinement Module (CHARM) that captures complex interdependencies between diagnoses and procedures. This design enables CafeMed to model how different medical conditions jointly influence treatment decisions while maintaining medication safety constraints. Extensive experiments on MIMIC-III and MIMIC-IV datasets demonstrate that CafeMed significantly outperforms state-of-the-art baselines, achieving superior accuracy in medication prediction while maintaining the lower drug--drug interaction rates. Our results indicate that incorporating dynamic causal relationships and cross-modal synergies leads to more clinically-aligned and personalized medication recommendations. Our code is released publicly at https://github.com/rkl71/CafeMed.
Modality Alignment with Multi-scale Bilateral Attention for Multimodal Recommendation
Sep 11, 2025Multimodal recommendation systems are increasingly becoming foundational technologies for e-commerce and content platforms, enabling personalized services by jointly modeling users' historical behaviors and the multimodal features of items (e.g., visual and textual). However, most existing methods rely on either static fusion strategies or graph-based local interaction modeling, facing two critical limitations: (1) insufficient ability to model fine-grained cross-modal associations, leading to suboptimal fusion quality; and (2) a lack of global distribution-level consistency, causing representational bias. To address these, we propose MambaRec, a novel framework that integrates local feature alignment and global distribution regularization via attention-guided learning. At its core, we introduce the Dilated Refinement Attention Module (DREAM), which uses multi-scale dilated convolutions with channel-wise and spatial attention to align fine-grained semantic patterns between visual and textual modalities. This module captures hierarchical relationships and context-aware associations, improving cross-modal semantic modeling. Additionally, we apply Maximum Mean Discrepancy (MMD) and contrastive loss functions to constrain global modality alignment, enhancing semantic consistency. This dual regularization reduces mode-specific deviations and boosts robustness. To improve scalability, MambaRec employs a dimensionality reduction strategy to lower the computational cost of high-dimensional multimodal features. Extensive experiments on real-world e-commerce datasets show that MambaRec outperforms existing methods in fusion quality, generalization, and efficiency. Our code has been made publicly available at https://github.com/rkl71/MambaRec.
Language-Agnostic Suicidal Risk Detection Using Large Language Models
May 26, 2025Suicidal risk detection in adolescents is a critical challenge, yet existing methods rely on language-specific models, limiting scalability and generalization. This study introduces a novel language-agnostic framework for suicidal risk assessment with large language models (LLMs). We generate Chinese transcripts from speech using an ASR model and then employ LLMs with prompt-based queries to extract suicidal risk-related features from these transcripts. The extracted features are retained in both Chinese and English to enable cross-linguistic analysis and then used to fine-tune corresponding pretrained language models independently. Experimental results show that our method achieves performance comparable to direct fine-tuning with ASR results or to models trained solely on Chinese suicidal risk-related features, demonstrating its potential to overcome language constraints and improve the robustness of suicidal risk assessment.
EndoForce: Development of an Intuitive Axial Force Measurement Device for Endoscopic Robotic Systems
May 19, 2025Robotic endoscopic systems provide intuitive control and eliminate radiation exposure, making them a promising alternative to conventional methods. However, the lack of axial force measurement from the robot remains a major challenge, as it can lead to excessive colonic elongation, perforation, or ureteral complications. Although various methods have been proposed in previous studies, limitations such as model dependency, bulkiness, and environmental sensitivity remain challenges that should be addressed before clinical application. In this study, we propose EndoForce, a device designed for intuitive and accurate axial force measurement in endoscopic robotic systems. Inspired by the insertion motion performed by medical doctors during ureteroscopy and gastrointestinal (GI) endoscopy, EndoForce ensures precise force measuring while maintaining compatibility with clinical environments. The device features a streamlined design, allowing for the easy attachment and detachment of a sterile cover, and incorporates a commercial load cell to enhance cost-effectiveness and facilitate practical implementation in real medical applications. To validate the effectiveness of the proposed EndoForce, physical experiments were performed using a testbed that simulates the ureter. We show that the axial force generated during insertion was measured with high accuracy, regardless of whether the pathway was straight or curved, in a testbed simulating the human ureter.
Domain Adversarial Training for Mitigating Gender Bias in Speech-based Mental Health Detection
May 06, 2025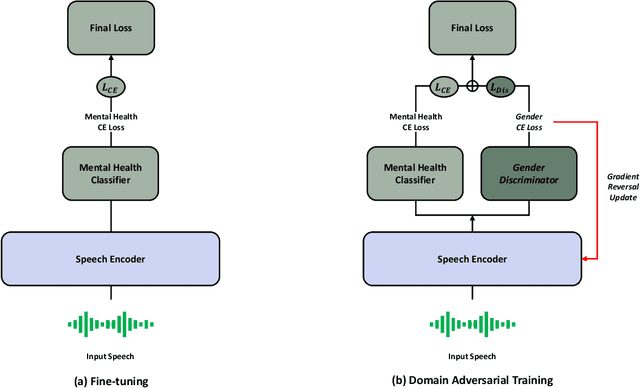



Speech-based AI models are emerging as powerful tools for detecting depression and the presence of Post-traumatic stress disorder (PTSD), offering a non-invasive and cost-effective way to assess mental health. However, these models often struggle with gender bias, which can lead to unfair and inaccurate predictions. In this study, our study addresses this issue by introducing a domain adversarial training approach that explicitly considers gender differences in speech-based depression and PTSD detection. Specifically, we treat different genders as distinct domains and integrate this information into a pretrained speech foundation model. We then validate its effectiveness on the E-DAIC dataset to assess its impact on performance. Experimental results show that our method notably improves detection performance, increasing the F1-score by up to 13.29 percentage points compared to the baseline. This highlights the importance of addressing demographic disparities in AI-driven mental health assessment.
What is a Good Question? Utility Estimation with LLM-based Simulations
Feb 24, 2025Asking questions is a fundamental aspect of learning that facilitates deeper understanding. However, characterizing and crafting questions that effectively improve learning remains elusive. To address this gap, we propose QUEST (Question Utility Estimation with Simulated Tests). QUEST simulates a learning environment that enables the quantification of a question's utility based on its direct impact on improving learning outcomes. Furthermore, we can identify high-utility questions and use them to fine-tune question generation models with rejection sampling. We find that questions generated by models trained with rejection sampling based on question utility result in exam scores that are higher by at least 20% than those from specialized prompting grounded on educational objectives literature and models fine-tuned with indirect measures of question quality, such as saliency and expected information gain.
REALTALK: A 21-Day Real-World Dataset for Long-Term Conversation
Feb 18, 2025Long-term, open-domain dialogue capabilities are essential for chatbots aiming to recall past interactions and demonstrate emotional intelligence (EI). Yet, most existing research relies on synthetic, LLM-generated data, leaving open questions about real-world conversational patterns. To address this gap, we introduce REALTALK, a 21-day corpus of authentic messaging app dialogues, providing a direct benchmark against genuine human interactions. We first conduct a dataset analysis, focusing on EI attributes and persona consistency to understand the unique challenges posed by real-world dialogues. By comparing with LLM-generated conversations, we highlight key differences, including diverse emotional expressions and variations in persona stability that synthetic dialogues often fail to capture. Building on these insights, we introduce two benchmark tasks: (1) persona simulation where a model continues a conversation on behalf of a specific user given prior dialogue context; and (2) memory probing where a model answers targeted questions requiring long-term memory of past interactions. Our findings reveal that models struggle to simulate a user solely from dialogue history, while fine-tuning on specific user chats improves persona emulation. Additionally, existing models face significant challenges in recalling and leveraging long-term context within real-world conversations.
STAR: A Simple Training-free Approach for Recommendations using Large Language Models
Oct 21, 2024Recent progress in large language models (LLMs) offers promising new approaches for recommendation system (RecSys) tasks. While the current state-of-the-art methods rely on fine-tuning LLMs to achieve optimal results, this process is costly and introduces significant engineering complexities. Conversely, methods that bypass fine-tuning and use LLMs directly are less resource-intensive but often fail to fully capture both semantic and collaborative information, resulting in sub-optimal performance compared to their fine-tuned counterparts. In this paper, we propose a Simple Training-free Approach for Recommendation (STAR), a framework that utilizes LLMs and can be applied to various recommendation tasks without the need for fine-tuning. Our approach involves a retrieval stage that uses semantic embeddings from LLMs combined with collaborative user information to retrieve candidate items. We then apply an LLM for pairwise ranking to enhance next-item prediction. Experimental results on the Amazon Review dataset show competitive performance for next item prediction, even with our retrieval stage alone. Our full method achieves Hits@10 performance of +23.8% on Beauty, +37.5% on Toys and Games, and -1.8% on Sports and Outdoors relative to the best supervised models. This framework offers an effective alternative to traditional supervised models, highlighting the potential of LLMs in recommendation systems without extensive training or custom architectures.
Evaluating Very Long-Term Conversational Memory of LLM Agents
Feb 27, 2024Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in long-context large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very long-term dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LoCoMo, a dataset of very long-term conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LoCoMo, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks. Our experimental results indicate that LLMs exhibit challenges in understanding lengthy conversations and comprehending long-range temporal and causal dynamics within dialogues. Employing strategies like long-context LLMs or RAG can offer improvements but these models still substantially lag behind human performance.
Integrating Pre-Trained Language Model with Physical Layer Communications
Feb 18, 2024



The burgeoning field of on-device AI communication, where devices exchange information directly through embedded foundation models, such as language models (LMs), requires robust, efficient, and generalizable communication frameworks. However, integrating these frameworks with existing wireless systems and effectively managing noise and bit errors pose significant challenges. In this work, we introduce a practical on-device AI communication framework, integrated with physical layer (PHY) communication functions, demonstrated through its performance on a link-level simulator. Our framework incorporates end-to-end training with channel noise to enhance resilience, incorporates vector quantized variational autoencoders (VQ-VAE) for efficient and robust communication, and utilizes pre-trained encoder-decoder transformers for improved generalization capabilities. Simulations, across various communication scenarios, reveal that our framework achieves a 50% reduction in transmission size while demonstrating substantial generalization ability and noise robustness under standardized 3GPP channel models.