 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is a Good Question? Utility Estimation with LLM-based Simulations
Feb 24, 2025Asking questions is a fundamental aspect of learning that facilitates deeper understanding. However, characterizing and crafting questions that effectively improve learning remains elusive. To address this gap, we propose QUEST (Question Utility Estimation with Simulated Tests). QUEST simulates a learning environment that enables the quantification of a question's utility based on its direct impact on improving learning outcomes. Furthermore, we can identify high-utility questions and use them to fine-tune question generation models with rejection sampling. We find that questions generated by models trained with rejection sampling based on question utility result in exam scores that are higher by at least 20% than those from specialized prompting grounded on educational objectives literature and models fine-tuned with indirect measures of question quality, such as saliency and expected information gain.
Tuning-Free Personalized Alignment via Trial-Error-Explain In-Context Learning
Feb 13, 2025Language models are aligned to the collective voice of many, resulting in generic outputs that do not align with specific users' styles. In this work, we present Trial-Error-Explain In-Context Learning (TICL), a tuning-free method that personalizes language models for text generation tasks with fewer than 10 examples per user. TICL iteratively expands an in-context learning prompt via a trial-error-explain process, adding model-generated negative samples and explanations that provide fine-grained guidance towards a specific user's style. TICL achieves favorable win rates on pairwise comparisons with LLM-as-a-judge up to 91.5% against the previous state-of-the-art and outperforms competitive tuning-free baselines for personalized alignment tasks of writing emails, essays and news articles. Both lexical and qualitative analyses show that the negative samples and explanations enable language models to learn stylistic context more effectively and overcome the bias towards structural and formal phrases observed in their zero-shot outputs. By front-loading inference compute to create a user-specific in-context learning prompt that does not require extra generation steps at test time, TICL presents a novel yet simple approach for personalized alignment.
NewsEdits 2.0: Learning the Intentions Behind Updating News
Nov 27, 2024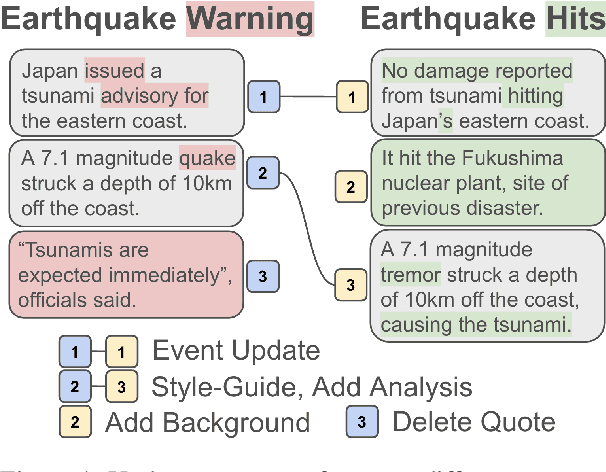



As events progress, news articles often update with new information: if we are not cautious, we risk propagating outdated facts. In this work, we hypothesize that linguistic features indicate factual fluidity, and that we can predict which facts in a news article will update using solely the text of a news article (i.e. not external resources like search engines). We test this hypothesis, first, by isolating fact-updates in large news revisions corpora. News articles may update for many reasons (e.g. factual, stylistic, narrative). We introduce the NewsEdits 2.0 taxonomy, an edit-intentions schema that separates fact updates from stylistic and narrative updates in news writing. We annotate over 9,200 pairs of sentence revisions and train high-scoring ensemble models to apply this schema. Then, taking a large dataset of silver-labeled pairs, we show that we can predict when facts will update in older article drafts with high precision. Finally, to demonstrate the usefulness of these findings, we construct a language model question asking (LLM-QA) abstention task. We wish the LLM to abstain from answering questions when information is likely to become outdated. Using our predictions, we show, LLM absention reaches near oracle levels of accuracy.
BotEval: Facilitating Interactive Human Evaluation
Jul 25, 2024Following the rapid progress in natural language processing (NLP) models, language models are applied to increasingly more complex interactive tasks such as negotiations and conversation moderations. Having human evaluators directly interact with these NLP models is essential for adequately evaluating the performance on such interactive tasks. We develop BotEval, an easily customizable, open-source, evaluation toolkit that focuses on enabling human-bot interactions as part of the evaluation process, as opposed to human evaluators making judgements for a static input. BotEval balances flexibility for customization and user-friendliness by providing templates for common use cases that span various degrees of complexity and built-in compatibility with popular crowdsourcing platforms. We showcase the numerous useful features of BotEval through a study that evaluates the performance of various chatbots on their effectiveness for conversational moderation and discuss how BotEval differs from other annotation tools.
Can Language Model Moderators Improve the Health of Online Discourse?
Nov 16, 2023



Human moderation of online conversation is essential to maintaining civility and focus in a dialogue, but is challenging to scale and harmful to moderators. The inclusion of sophisticated natural language generation modules as a force multiplier aid moderators is a tantalizing prospect, but adequate evaluation approaches have so far been elusive. In this paper, we establish a systematic definition of conversational moderation effectiveness through a multidisciplinary lens that incorporates insights from social science. We then propose a comprehensive evaluation framework that uses this definition to asses models' moderation capabilities independently of human intervention. With our framework, we conduct the first known study of conversational dialogue models as moderators, finding that appropriately prompted models can provide specific and fair feedback on toxic behavior but struggle to influence users to increase their levels of respect and cooperation.
Continual Dialogue State Tracking via Example-Guided Question Answering
May 23, 2023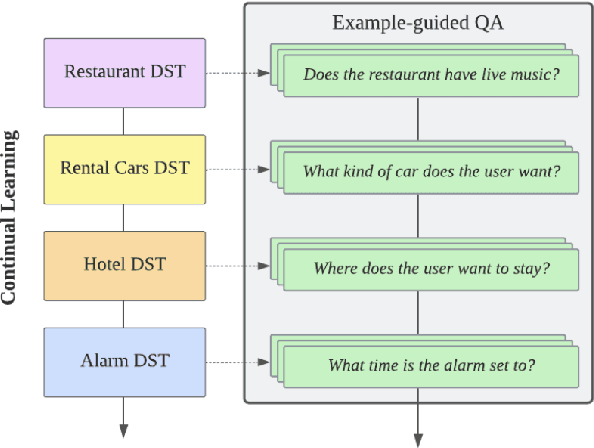
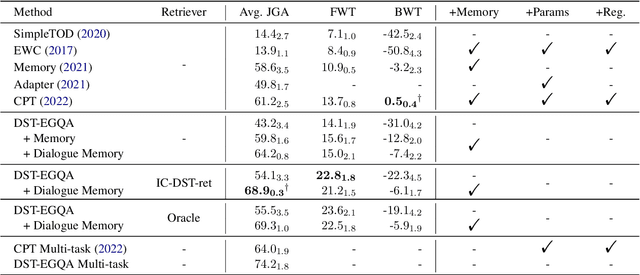
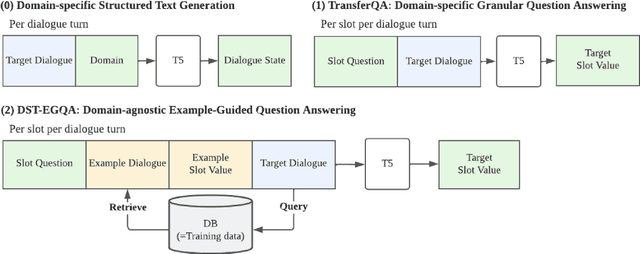

Dialogue systems are frequently updated to accommodate new services, but naively updating them by continually training with data for new services in diminishing performance on previously learnt services. Motivated by the insight that dialogue state tracking (DST), a crucial component of dialogue systems that estimates the user's goal as a conversation proceeds, is a simple natural language understanding task, we propose reformulating it as a bundle of granular example-guided question answering tasks to minimize the task shift between services and thus benefit continual learning. Our approach alleviates service-specific memorization and teaches a model to contextualize the given question and example to extract the necessary information from the conversation. We find that a model with just 60M parameters can achieve a significant boost by learning to learn from in-context examples retrieved by a retriever trained to identify turns with similar dialogue state changes. Combining our method with dialogue-level memory replay, our approach attains state of the art performance on DST continual learning metrics without relying on any complex regularization or parameter expansion methods.
Analyzing Norm Violations in Live-Stream Chat
May 18, 2023



Toxic language, such as hate speech, can deter users from participating in online communities and enjoying popular platforms. Previous approaches to detecting toxic language and norm violations have been primarily concerned with conversations from online forums and social media, such as Reddit and Twitter. These approaches are less effective when applied to conversations on live-streaming platforms, such as Twitch and YouTube Live, as each comment is only visible for a limited time and lacks a thread structure that establishes its relationship with other comments. In this work, we share the first NLP study dedicated to detecting norm violations in conversations on live-streaming platforms. We define norm violation categories in live-stream chats and annotate 4,583 moderated comments from Twitch. We articulate several facets of live-stream data that differ from other forums, and demonstrate that existing models perform poorly in this setting. By conducting a user study, we identify the informational context humans use in live-stream moderation, and train models leveraging context to identify norm violations. Our results show that appropriate contextual information can boost moderation performance by 35\%.
Reflect, Not Reflex: Inference-Based Common Ground Improves Dialogue Response Quality
Nov 16, 2022Human communication relies on common ground (CG), the mutual knowledge and beliefs shared by participants, to produce coherent and interesting conversations. In this paper, we demonstrate that current response generation (RG) models produce generic and dull responses in dialogues because they act reflexively, failing to explicitly model CG, both due to the lack of CG in training data and the standard RG training procedure. We introduce Reflect, a dataset that annotates dialogues with explicit CG (materialized as inferences approximating shared knowledge and beliefs) and solicits 9k diverse human-generated responses each following one common ground. Using Reflect, we showcase the limitations of current dialogue data and RG models: less than half of the responses in current data are rated as high quality (sensible, specific, and interesting) and models trained using this data have even lower quality, while most Reflect responses are judged high quality. Next, we analyze whether CG can help models produce better-quality responses by using Reflect CG to guide RG models. Surprisingly, we find that simply prompting GPT3 to "think" about CG generates 30% more quality responses, showing promising benefits to integrating CG into the RG process.
CheckDST: Measuring Real-World Generalization of Dialogue State Tracking Performance
Dec 15, 2021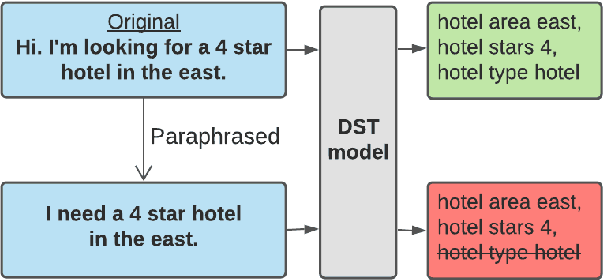
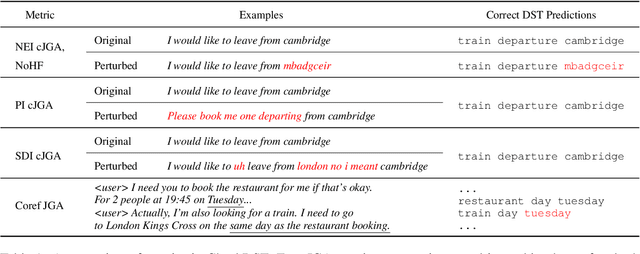
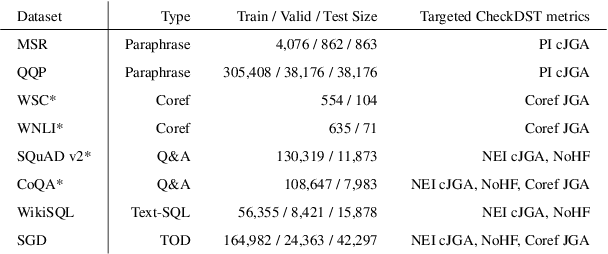
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.
Viola: A Topic Agnostic Generate-and-Rank Dialogue System
Aug 25, 2021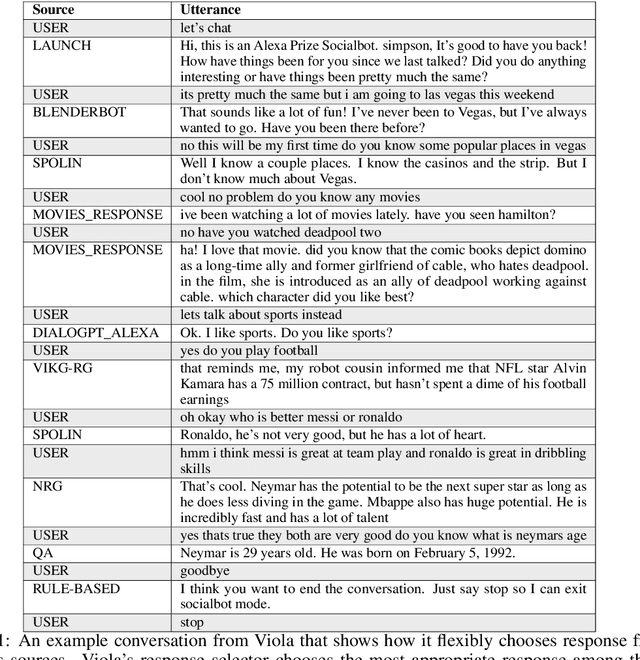
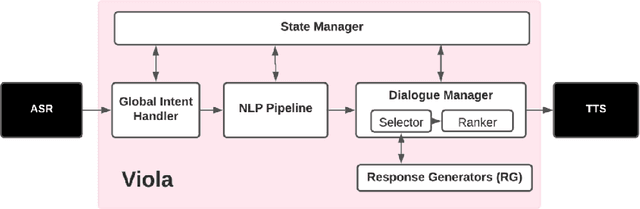
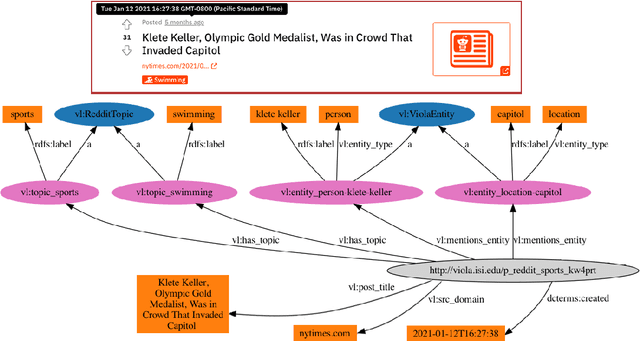
We present Viola, an open-domain dialogue system for spoken conversation that uses a topic-agnostic dialogue manager based on a simple generate-and-rank approach. Leveraging recent advances of generative dialogue systems powered by large language models, Viola fetches a batch of response candidates from various neural dialogue models trained with different datasets and knowledge-grounding inputs. Additional responses originating from template-based generators are also considered, depending on the user's input and detected entities. The hand-crafted generators build on a dynamic knowledge graph injected with rich content that is crawled from the web and automatically processed on a daily basis. Viola's response ranker is a fine-tuned polyencoder that chooses the best response given the dialogue history. While dedicated annotations for the polyencoder alone can indirectly steer it away from choosing problematic responses, we add rule-based safety nets to detect neural degeneration and a dedicated classifier to filter out offensive content. We analyze conversations that Viola took part in for the Alexa Prize Socialbot Grand Challenge 4 and discuss the strengths and weaknesses of our approach. Lastly, we suggest future work with a focus on curating conversation data specifcially for socialbots that will contribute towards a more robust data-driven socialbot.