 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRVOS: Reasoning over Object Tracks for Zero-Shot Referring Video Object Segmentation
Mar 24, 2026Referring Video Object Segmentation (RVOS) aims to segment a target object throughout a video given a natural language query. Training-free methods for this task follow a common pipeline: a MLLM selects keyframes, grounds the referred object within those frames, and a video segmentation model propagates the results. While intuitive, this design asks the MLLM to make temporal decisions before any object-level evidence is available, limiting both reasoning quality and spatio-temporal coverage. To overcome this, we propose AgentRVOS, a training-free agentic pipeline built on the complementary strengths of SAM3 and a MLLM. Given a concept derived from the query, SAM3 provides reliable perception over the full spatio-temporal extent through generated mask tracks. The MLLM then identifies the target through query-grounded reasoning over this object-level evidence, iteratively pruning guided by SAM3's temporal existence information. Extensive experiments show that AgentRVOS achieves state-of-the-art performance among training-free methods across multiple benchmarks, with consistent results across diverse MLLM backbones. Our project page is available at: https://cvlab-kaist.github.io/AgentRVOS/.
Hybrid Forecasting of Geopolitical Events
Dec 14, 2024



Sound decision-making relies on accurate prediction for tangible outcomes ranging from military conflict to disease outbreaks. To improve crowdsourced forecasting accuracy, we developed SAGE, a hybrid forecasting system that combines human and machine generated forecasts. The system provides a platform where users can interact with machine models and thus anchor their judgments on an objective benchmark. The system also aggregates human and machine forecasts weighting both for propinquity and based on assessed skill while adjusting for overconfidence. We present results from the Hybrid Forecasting Competition (HFC) - larger than comparable forecasting tournaments - including 1085 users forecasting 398 real-world forecasting problems over eight months. Our main result is that the hybrid system generated more accurate forecasts compared to a human-only baseline which had no machine generated predictions. We found that skilled forecasters who had access to machine-generated forecasts outperformed those who only viewed historical data. We also demonstrated the inclusion of machine-generated forecasts in our aggregation algorithms improved performance, both in terms of accuracy and scalability. This suggests that hybrid forecasting systems, which potentially require fewer human resources, can be a viable approach for maintaining a competitive level of accuracy over a larger number of forecasting questions.
* 20 pages, 6 figures, 4 tables
Referring Video Object Segmentation via Language-aligned Track Selection
Dec 02, 2024Referring Video Object Segmentation (RVOS) seeks to segment objects throughout a video based on natural language expressions. While existing methods have made strides in vision-language alignment, they often overlook the importance of robust video object tracking, where inconsistent mask tracks can disrupt vision-language alignment, leading to suboptimal performance. In this work, we present Selection by Object Language Alignment (SOLA), a novel framework that reformulates RVOS into two sub-problems, track generation and track selection. In track generation, we leverage a vision foundation model, Segment Anything Model 2 (SAM2), which generates consistent mask tracks across frames, producing reliable candidates for both foreground and background objects. For track selection, we propose a light yet effective selection module that aligns visual and textual features while modeling object appearance and motion within video sequences. This design enables precise motion modeling and alignment of the vision language. Our approach achieves state-of-the-art performance on the challenging MeViS dataset and demonstrates superior results in zero-shot settings on the Ref-Youtube-VOS and Ref-DAVIS datasets. Furthermore, SOLA exhibits strong generalization and robustness in corrupted settings, such as those with added Gaussian noise or motion blur. Our project page is available at https://cvlab-kaist.github.io/SOLA
Pose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
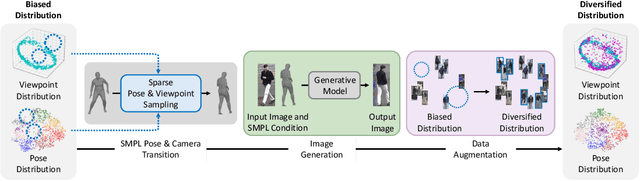
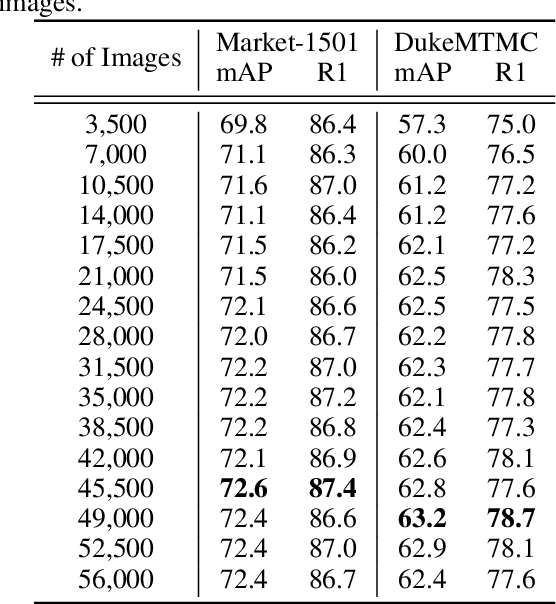
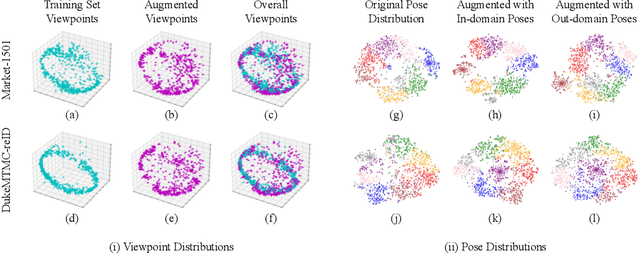
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
WinoViz: Probing Visual Properties of Objects Under Different States
Feb 21, 2024

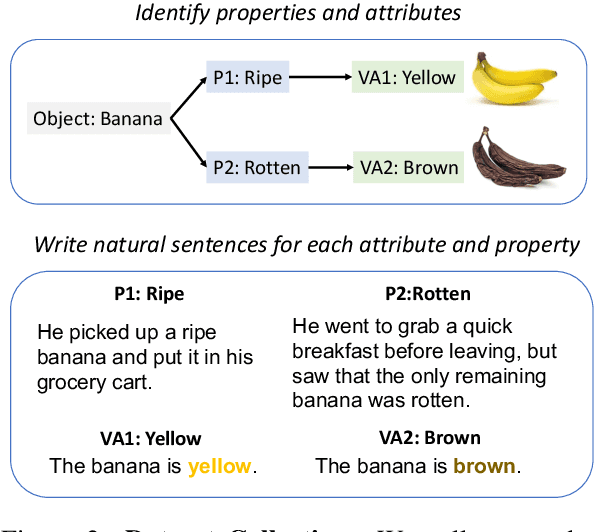

Humans perceive and comprehend different visual properties of an object based on specific contexts. For instance, we know that a banana turns brown ``when it becomes rotten,'' whereas it appears green ``when it is unripe.'' Previous studies on probing visual commonsense knowledge have primarily focused on examining language models' understanding of typical properties (e.g., colors and shapes) of objects. We present WinoViz, a text-only evaluation dataset, consisting of 1,380 examples that probe the reasoning abilities of language models regarding variant visual properties of objects under different contexts or states. Our task is challenging since it requires pragmatic reasoning (finding intended meanings) and visual knowledge reasoning. We also present multi-hop data, a more challenging version of our data, which requires multi-step reasoning chains to solve our task. In our experimental analysis, our findings are: a) Large language models such as GPT-4 demonstrate effective performance, but when it comes to multi-hop data, their performance is significantly degraded. b) Large models perform well on pragmatic reasoning, but visual knowledge reasoning is a bottleneck in our task. c) Vision-language models outperform their language-model counterparts. d) A model with machine-generated images performs poorly in our task. This is due to the poor quality of the generated images.
GRILL: Grounded Vision-language Pre-training via Aligning Text and Image Regions
May 24, 2023



Generalization to unseen tasks is an important ability for few-shot learners to achieve better zero-/few-shot performance on diverse tasks. However, such generalization to vision-language tasks including grounding and generation tasks has been under-explored; existing few-shot VL models struggle to handle tasks that involve object grounding and multiple images such as visual commonsense reasoning or NLVR2. In this paper, we introduce GRILL, GRounded vIsion Language aLigning, a novel VL model that can be generalized to diverse tasks including visual question answering, captioning, and grounding tasks with no or very few training instances. Specifically, GRILL learns object grounding and localization by exploiting object-text alignments, which enables it to transfer to grounding tasks in a zero-/few-shot fashion. We evaluate our model on various zero-/few-shot VL tasks and show that it consistently surpasses the state-of-the-art few-shot methods.
Analyzing Norm Violations in Live-Stream Chat
May 18, 2023



Toxic language, such as hate speech, can deter users from participating in online communities and enjoying popular platforms. Previous approaches to detecting toxic language and norm violations have been primarily concerned with conversations from online forums and social media, such as Reddit and Twitter. These approaches are less effective when applied to conversations on live-streaming platforms, such as Twitch and YouTube Live, as each comment is only visible for a limited time and lacks a thread structure that establishes its relationship with other comments. In this work, we share the first NLP study dedicated to detecting norm violations in conversations on live-streaming platforms. We define norm violation categories in live-stream chats and annotate 4,583 moderated comments from Twitch. We articulate several facets of live-stream data that differ from other forums, and demonstrate that existing models perform poorly in this setting. By conducting a user study, we identify the informational context humans use in live-stream moderation, and train models leveraging context to identify norm violations. Our results show that appropriate contextual information can boost moderation performance by 35\%.
Temporal Knowledge Graph Forecasting Without Knowledge Using In-Context Learning
May 17, 2023Temporal knowledge graph (TKG) forecasting benchmarks challenge models to predict future facts using knowledge of past facts. In this paper, we apply large language models (LLMs) to these benchmarks using in-context learning (ICL). We investigate whether and to what extent LLMs can be used for TKG forecasting, especially without any fine-tuning or explicit modules for capturing structural and temporal information. For our experiments, we present a framework that converts relevant historical facts into prompts and generates ranked predictions using token probabilities. Surprisingly, we observe that LLMs, out-of-the-box, perform on par with state-of-the-art TKG models carefully designed and trained for TKG forecasting. Our extensive evaluation presents performances across several models and datasets with different characteristics, compares alternative heuristics for preparing contextual information, and contrasts to prominent TKG methods and simple frequency and recency baselines. We also discover that using numerical indices instead of entity/relation names, i.e., hiding semantic information, does not significantly affect the performance ($\pm$0.4\% Hit@1). This shows that prior semantic knowledge is unnecessary; instead, LLMs can leverage the existing patterns in the context to achieve such performance. Our analysis also reveals that ICL enables LLMs to learn irregular patterns from the historical context, going beyond simple predictions based on common or recent information.
Leveraging Visual Knowledge in Language Tasks: An Empirical Study on Intermediate Pre-training for Cross-modal Knowledge Transfer
Mar 17, 2022
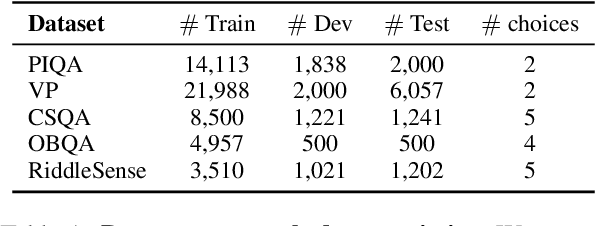
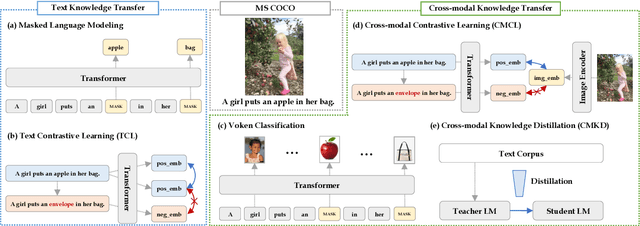
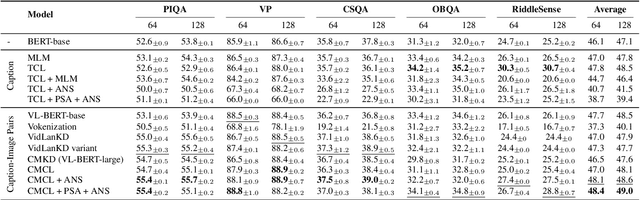
Pre-trained language models are still far from human performance in tasks that need understanding of properties (e.g. appearance, measurable quantity) and affordances of everyday objects in the real world since the text lacks such information due to reporting bias. In this work, we study whether integrating visual knowledge into a language model can fill the gap. We investigate two types of knowledge transfer: (1) text knowledge transfer using image captions that may contain enriched visual knowledge and (2) cross-modal knowledge transfer using both images and captions with vision-language training objectives. On 5 downstream tasks that may need visual knowledge to solve the problem, we perform extensive empirical comparisons over the presented objectives. Our experiments show that visual knowledge transfer can improve performance in both low-resource and fully supervised settings.
A Good Prompt Is Worth Millions of Parameters? Low-resource Prompt-based Learning for Vision-Language Models
Oct 16, 2021
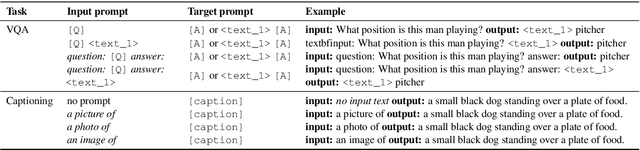
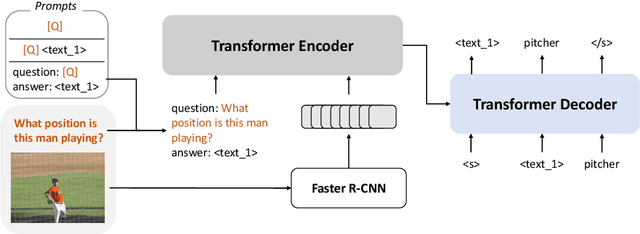
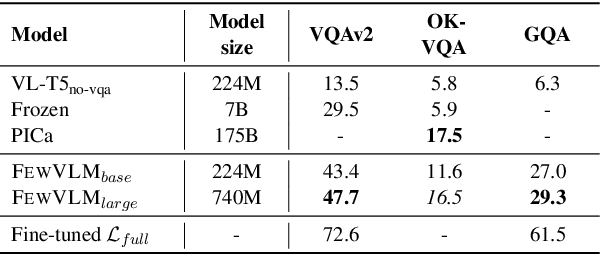
Large pretrained vision-language (VL) models can learn a new task with a handful of examples or generalize to a new task without fine-tuning. However, these gigantic VL models are hard to deploy for real-world applications due to their impractically huge model size and slow inference speed. In this work, we propose FewVLM, a few-shot prompt-based learner on vision-language tasks. We pretrain a sequence-to-sequence Transformer model with both prefix language modeling (PrefixLM) and masked language modeling (MaskedLM), and introduce simple prompts to improve zero-shot and few-shot performance on VQA and image captioning. Experimental results on five VQA and captioning datasets show that \method\xspace outperforms Frozen which is 31 times larger than ours by 18.2% point on zero-shot VQAv2 and achieves comparable results to a 246$\times$ larger model, PICa. We observe that (1) prompts significantly affect zero-shot performance but marginally affect few-shot performance, (2) MaskedLM helps few-shot VQA tasks while PrefixLM boosts captioning performance, and (3) performance significantly increases when training set size is small.