 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
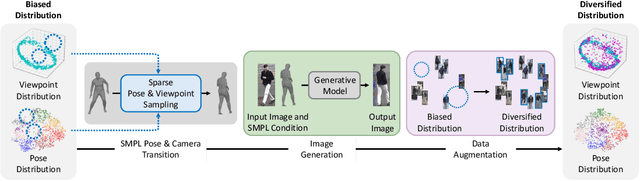
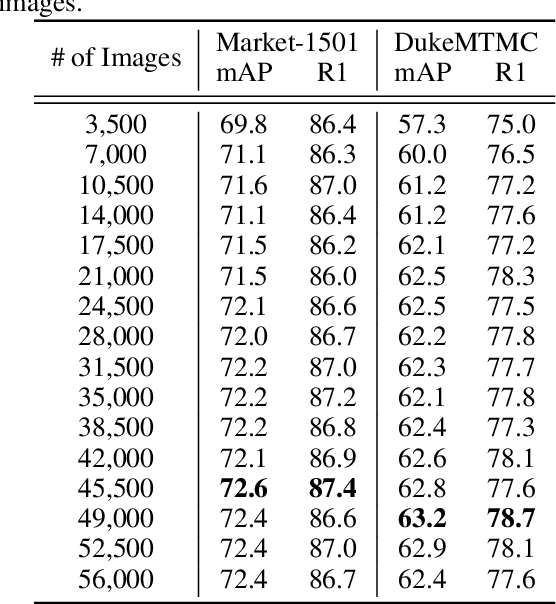
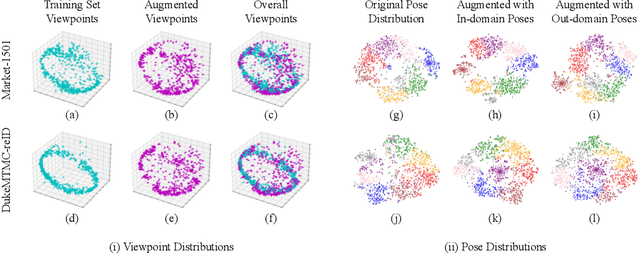
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
Scene Understanding Networks for Autonomous Driving based on Around View Monitoring System
May 18, 2018

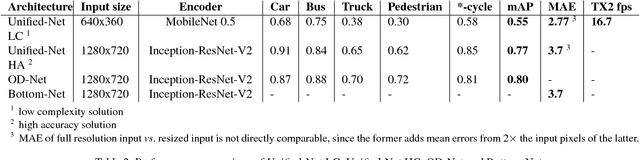
Modern driver assistance systems rely on a wide range of sensors (RADAR, LIDAR, ultrasound and cameras) for scene understanding and prediction. These sensors are typically used for detecting traffic participants and scene elements required for navigation. In this paper we argue that relying on camera based systems, specifically Around View Monitoring (AVM) system has great potential to achieve these goals in both parking and driving modes with decreased costs. The contributions of this paper are as follows: we present a new end-to-end solution for delimiting the safe drivable area for each frame by means of identifying the closest obstacle in each direction from the driving vehicle, we use this approach to calculate the distance to the nearest obstacles and we incorporate it into a unified end-to-end architecture capable of joint object detection, curb detection and safe drivable area detection. Furthermore, we describe the family of networks for both a high accuracy solution and a low complexity solution. We also introduce further augmentation of the base architecture with 3D object detection.