 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
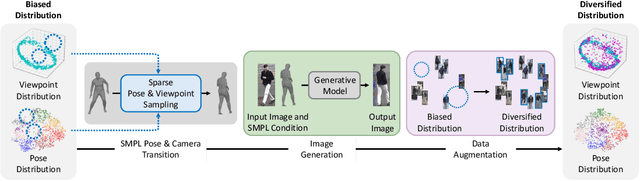
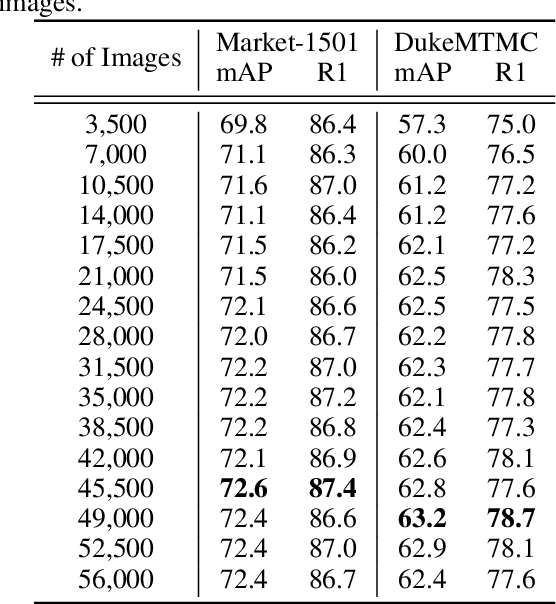
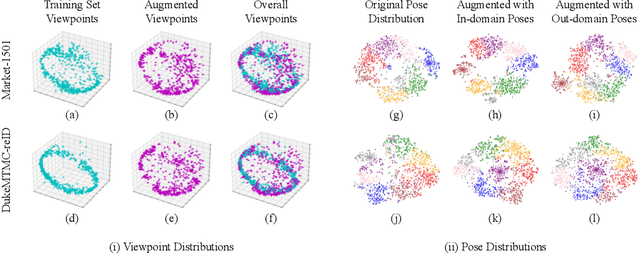
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
Context Enhanced Transformer for Single Image Object Detection
Dec 26, 2023



With the increasing importance of video data in real-world applications, there is a rising need for efficient object detection methods that utilize temporal information. While existing video object detection (VOD) techniques employ various strategies to address this challenge, they typically depend on locally adjacent frames or randomly sampled images within a clip. Although recent Transformer-based VOD methods have shown promising results, their reliance on multiple inputs and additional network complexity to incorporate temporal information limits their practical applicability. In this paper, we propose a novel approach to single image object detection, called Context Enhanced TRansformer (CETR), by incorporating temporal context into DETR using a newly designed memory module. To efficiently store temporal information, we construct a class-wise memory that collects contextual information across data. Additionally, we present a classification-based sampling technique to selectively utilize the relevant memory for the current image. In the testing, We introduce a test-time memory adaptation method that updates individual memory functions by considering the test distribution. Experiments with CityCam and ImageNet VID datasets exhibit the efficiency of the framework on various video systems. The project page and code will be made available at: https://ku-cvlab.github.io/CETR.
Joint Representation of Temporal Image Sequences and Object Motion for Video Object Detection
Nov 20, 2020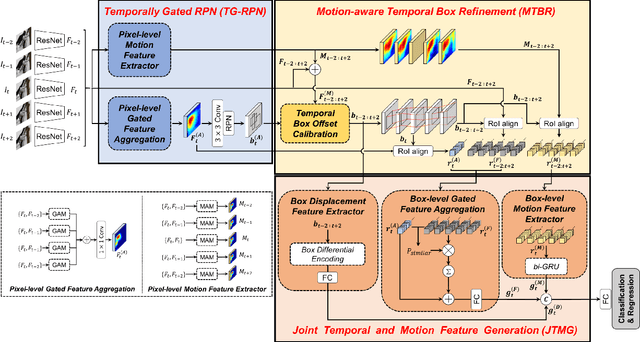
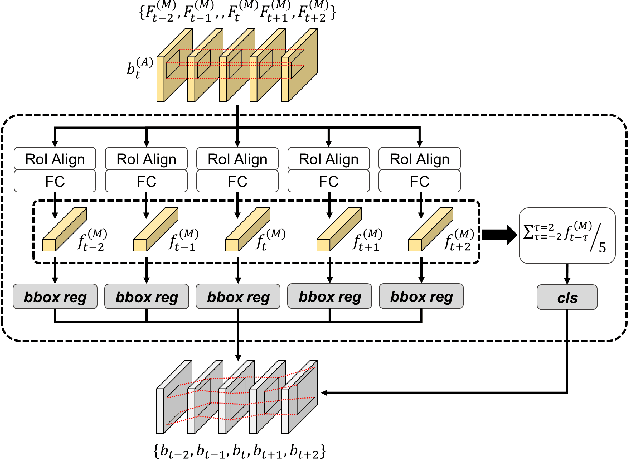
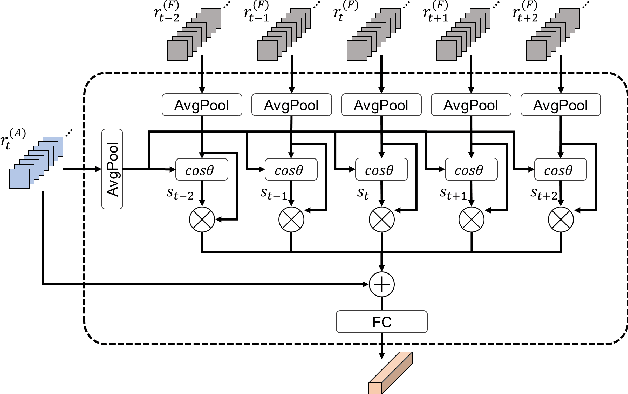

In this paper, we propose a new video object detector (VoD) method referred to as temporal feature aggregation and motion-aware VoD (TM-VoD), which produces a joint representation of temporal image sequences and object motion. The proposed TM-VoD aggregates visual feature maps extracted by convolutional neural networks applying the temporal attention gating and spatial feature alignment. This temporal feature aggregation is performed in two stages in a hierarchical fashion. In the first stage, the visual feature maps are fused at a pixel level via gated attention model. In the second stage, the proposed method aggregates the features after aligning the object features using temporal box offset calibration and weights them according to the cosine similarity measure. The proposed TM-VoD also finds the representation of the motion of objects in two successive steps. The pixel-level motion features are first computed based on the incremental changes between the adjacent visual feature maps. Then, box-level motion features are obtained from both the region of interest (RoI)-aligned pixel-level motion features and the sequential changes of the box coordinates. Finally, all these features are concatenated to produce a joint representation of the objects for VoD. The experiments conducted on the ImageNet VID dataset demonstrate that the proposed method outperforms existing VoD methods and achieves a performance comparable to that of state-of-the-art VoDs.
Submission to ActivityNet Challenge 2019: Task B Spatio-temporal Action Localization
Jul 25, 2019
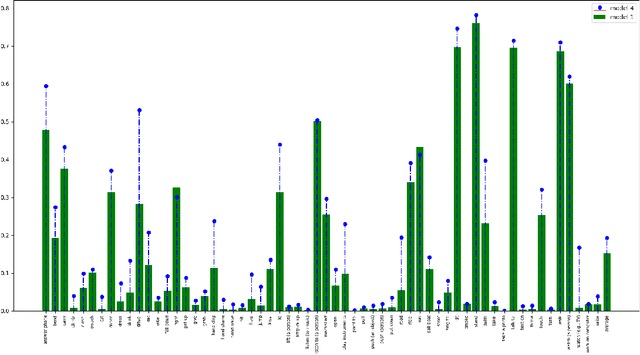
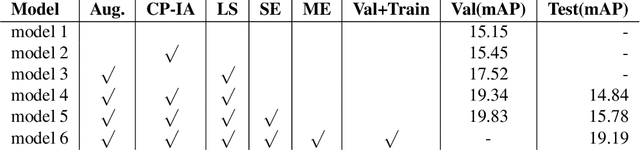
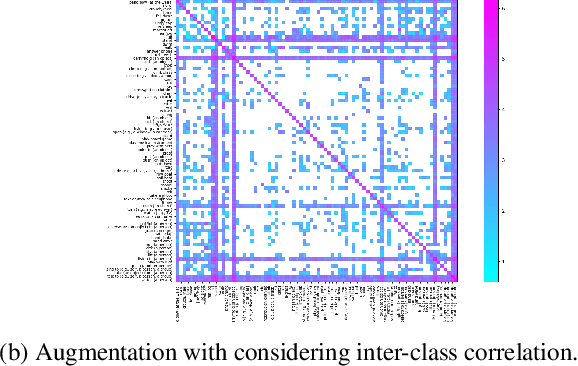
This technical report present an overview of our system proposed for the spatio-temporal action localization(SAL) task in ActivityNet Challenge 2019. Unlike previous two-streams-based works, we focus on exploring the end-to-end trainable architecture using only RGB sequential images. To this end, we employ a previously proposed simple yet effective two-branches network called SlowFast Networks which is capable of capturing both short- and long-term spatiotemporal features. Moreover, to handle the severe class imbalance and overfitting problems, we propose a correlation-preserving data augmentation method and a random label subsampling method which have been proven to be able to reduce overfitting and improve the performance.