 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
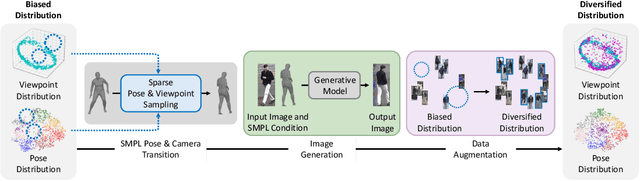
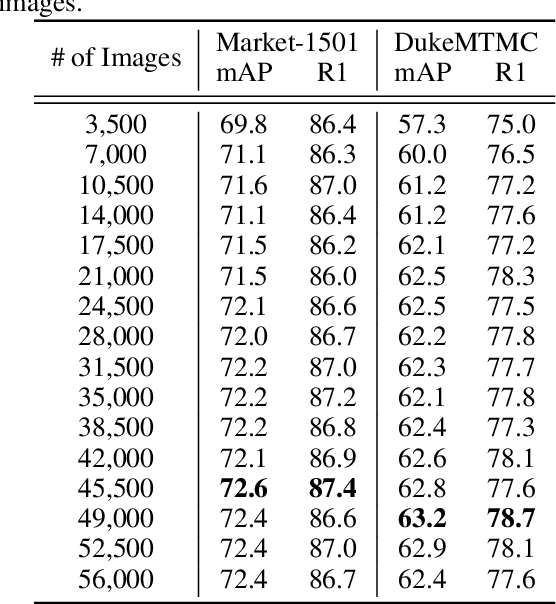
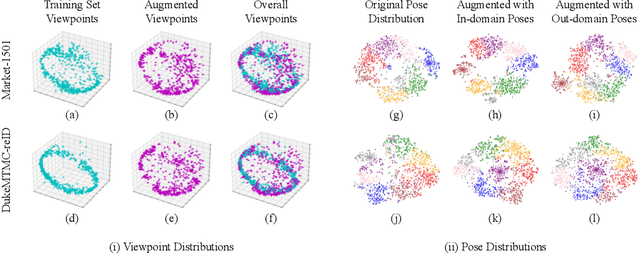
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting
Apr 25, 2024



We propose GaussianTalker, a novel framework for real-time generation of pose-controllable talking heads. It leverages the fast rendering capabilities of 3D Gaussian Splatting (3DGS) while addressing the challenges of directly controlling 3DGS with speech audio. GaussianTalker constructs a canonical 3DGS representation of the head and deforms it in sync with the audio. A key insight is to encode the 3D Gaussian attributes into a shared implicit feature representation, where it is merged with audio features to manipulate each Gaussian attribute. This design exploits the spatial-aware features and enforces interactions between neighboring points. The feature embeddings are then fed to a spatial-audio attention module, which predicts frame-wise offsets for the attributes of each Gaussian. It is more stable than previous concatenation or multiplication approaches for manipulating the numerous Gaussians and their intricate parameters. Experimental results showcase GaussianTalker's superiority in facial fidelity, lip synchronization accuracy, and rendering speed compared to previous methods. Specifically, GaussianTalker achieves a remarkable rendering speed up to 120 FPS, surpassing previous benchmarks. Our code is made available at https://github.com/KU-CVLAB/GaussianTalker/ .
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Mar 29, 2024Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
3D GAN Inversion with Pose Optimization
Oct 17, 2022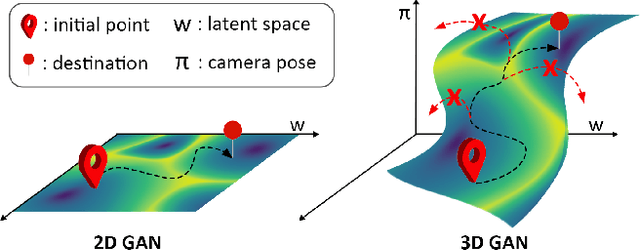


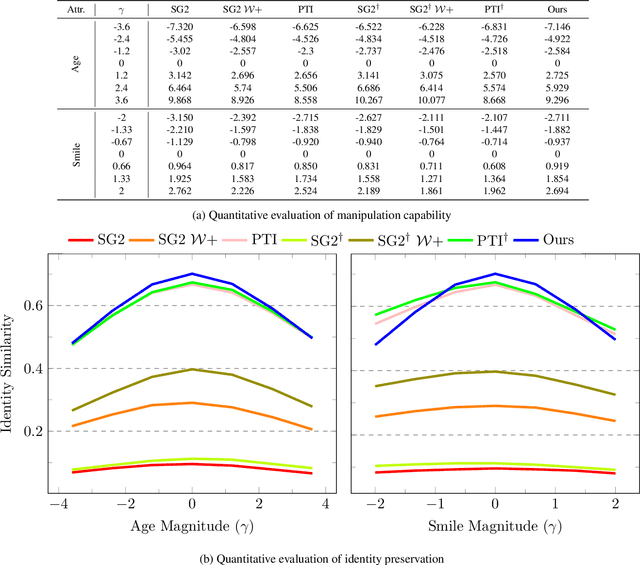
With the recent advances in NeRF-based 3D aware GANs quality, projecting an image into the latent space of these 3D-aware GANs has a natural advantage over 2D GAN inversion: not only does it allow multi-view consistent editing of the projected image, but it also enables 3D reconstruction and novel view synthesis when given only a single image. However, the explicit viewpoint control acts as a main hindrance in the 3D GAN inversion process, as both camera pose and latent code have to be optimized simultaneously to reconstruct the given image. Most works that explore the latent space of the 3D-aware GANs rely on ground-truth camera viewpoint or deformable 3D model, thus limiting their applicability. In this work, we introduce a generalizable 3D GAN inversion method that infers camera viewpoint and latent code simultaneously to enable multi-view consistent semantic image editing. The key to our approach is to leverage pre-trained estimators for better initialization and utilize the pixel-wise depth calculated from NeRF parameters to better reconstruct the given image. We conduct extensive experiments on image reconstruction and editing both quantitatively and qualitatively, and further compare our results with 2D GAN-based editing to demonstrate the advantages of utilizing the latent space of 3D GANs. Additional results and visualizations are available at https://3dgan-inversion.github.io .
AE-NeRF: Auto-Encoding Neural Radiance Fields for 3D-Aware Object Manipulation
Apr 28, 2022
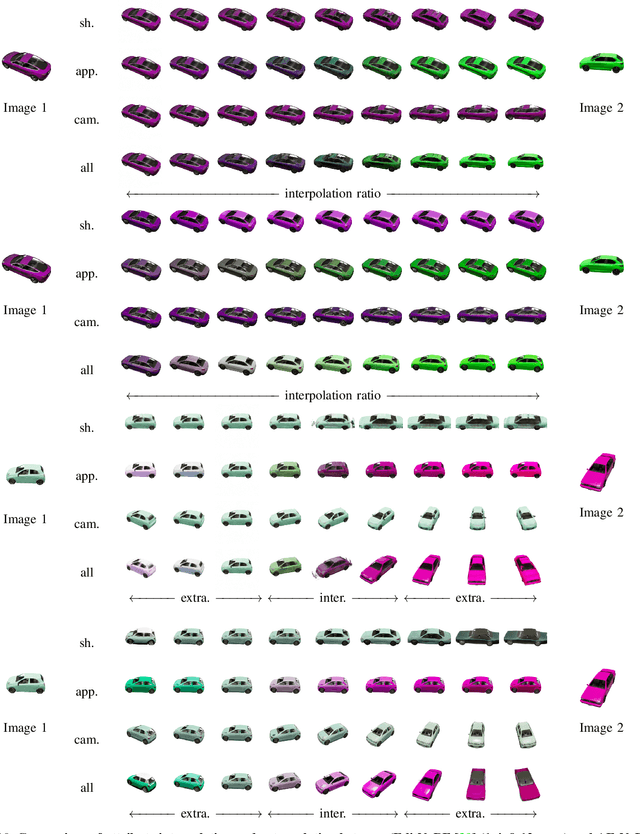


We propose a novel framework for 3D-aware object manipulation, called Auto-Encoding Neural Radiance Fields (AE-NeRF). Our model, which is formulated in an auto-encoder architecture, extracts disentangled 3D attributes such as 3D shape, appearance, and camera pose from an image, and a high-quality image is rendered from the attributes through disentangled generative Neural Radiance Fields (NeRF). To improve the disentanglement ability, we present two losses, global-local attribute consistency loss defined between input and output, and swapped-attribute classification loss. Since training such auto-encoding networks from scratch without ground-truth shape and appearance information is non-trivial, we present a stage-wise training scheme, which dramatically helps to boost the performance. We conduct experiments to demonstrate the effectiveness of the proposed model over the latest methods and provide extensive ablation studies.