 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAE-NeRF: Auto-Encoding Neural Radiance Fields for 3D-Aware Object Manipulation
Paper and Code
Apr 28, 2022
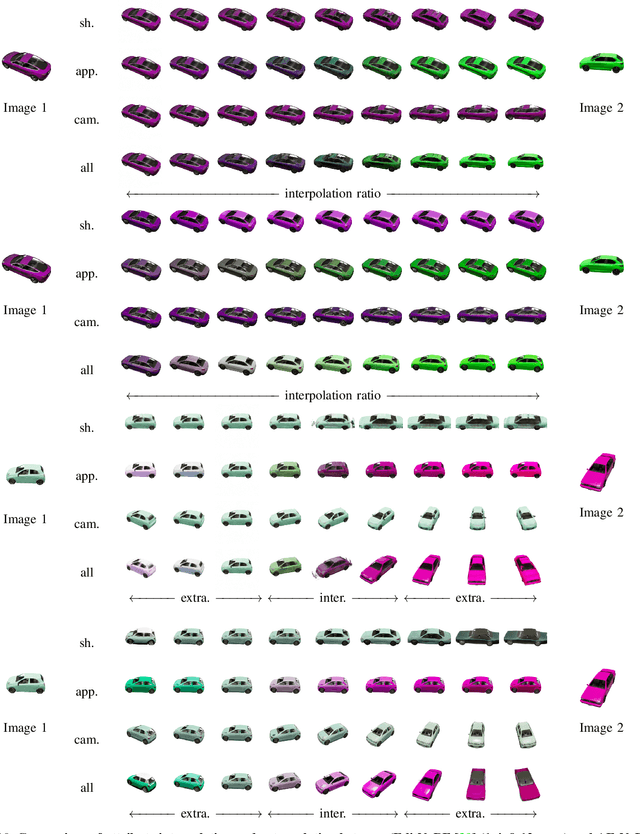


We propose a novel framework for 3D-aware object manipulation, called Auto-Encoding Neural Radiance Fields (AE-NeRF). Our model, which is formulated in an auto-encoder architecture, extracts disentangled 3D attributes such as 3D shape, appearance, and camera pose from an image, and a high-quality image is rendered from the attributes through disentangled generative Neural Radiance Fields (NeRF). To improve the disentanglement ability, we present two losses, global-local attribute consistency loss defined between input and output, and swapped-attribute classification loss. Since training such auto-encoding networks from scratch without ground-truth shape and appearance information is non-trivial, we present a stage-wise training scheme, which dramatically helps to boost the performance. We conduct experiments to demonstrate the effectiveness of the proposed model over the latest methods and provide extensive ablation studies.