 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangLingual: A Personalised, Exercise-oriented English Language Learning Tool Leveraging Large Language Models
Oct 27, 2025Language educators strive to create a rich experience for learners, while they may be restricted in the extend of feedback and practice they can provide. We present the design and development of LangLingual, a conversational agent built using the LangChain framework and powered by Large Language Models. The system is specifically designed to provide real-time, grammar-focused feedback, generate context-aware language exercises and track learner proficiency over time. The paper discusses the architecture, implementation and evaluation of LangLingual in detail. The results indicate strong usability, positive learning outcomes and encouraging learner engagement.
Universal Noise Annotation: Unveiling the Impact of Noisy annotation on Object Detection
Dec 21, 2023For object detection task with noisy labels, it is important to consider not only categorization noise, as in image classification, but also localization noise, missing annotations, and bogus bounding boxes. However, previous studies have only addressed certain types of noise (e.g., localization or categorization). In this paper, we propose Universal-Noise Annotation (UNA), a more practical setting that encompasses all types of noise that can occur in object detection, and analyze how UNA affects the performance of the detector. We analyzed the development direction of previous works of detection algorithms and examined the factors that impact the robustness of detection model learning method. We open-source the code for injecting UNA into the dataset and all the training log and weight are also shared.
AE-NeRF: Auto-Encoding Neural Radiance Fields for 3D-Aware Object Manipulation
Apr 28, 2022
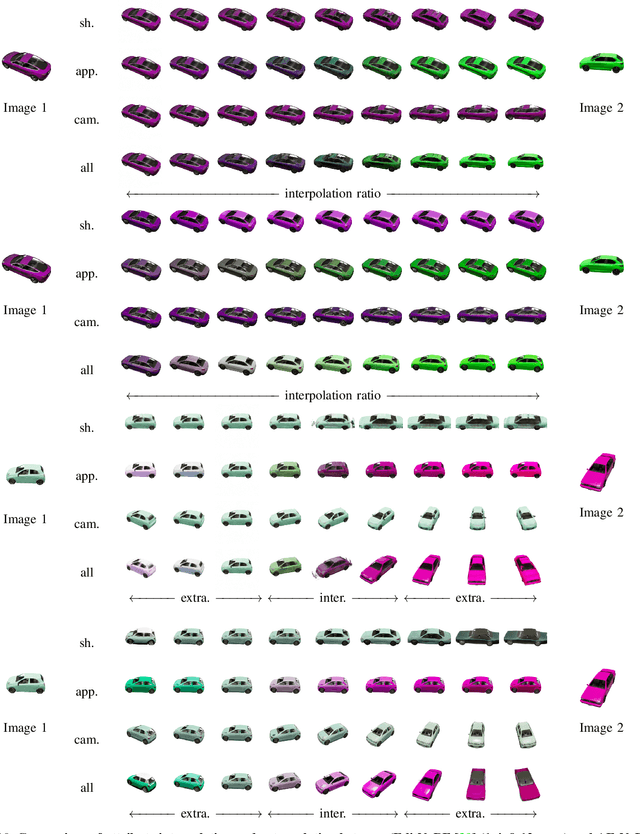


We propose a novel framework for 3D-aware object manipulation, called Auto-Encoding Neural Radiance Fields (AE-NeRF). Our model, which is formulated in an auto-encoder architecture, extracts disentangled 3D attributes such as 3D shape, appearance, and camera pose from an image, and a high-quality image is rendered from the attributes through disentangled generative Neural Radiance Fields (NeRF). To improve the disentanglement ability, we present two losses, global-local attribute consistency loss defined between input and output, and swapped-attribute classification loss. Since training such auto-encoding networks from scratch without ground-truth shape and appearance information is non-trivial, we present a stage-wise training scheme, which dramatically helps to boost the performance. We conduct experiments to demonstrate the effectiveness of the proposed model over the latest methods and provide extensive ablation studies.
Joint Learning of Feature Extraction and Cost Aggregation for Semantic Correspondence
Apr 19, 2022
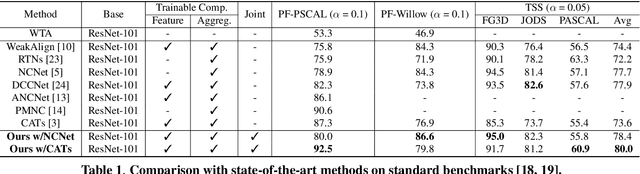


Establishing dense correspondences across semantically similar images is one of the challenging tasks due to the significant intra-class variations and background clutters. To solve these problems, numerous methods have been proposed, focused on learning feature extractor or cost aggregation independently, which yields sub-optimal performance. In this paper, we propose a novel framework for jointly learning feature extraction and cost aggregation for semantic correspondence. By exploiting the pseudo labels from each module, the networks consisting of feature extraction and cost aggregation modules are simultaneously learned in a boosting fashion. Moreover, to ignore unreliable pseudo labels, we present a confidence-aware contrastive loss function for learning the networks in a weakly-supervised manner. We demonstrate our competitive results on standard benchmarks for semantic correspondence.