 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
MolMole: Molecule Mining from Scientific Literature
May 08, 2025The extraction of molecular structures and reaction data from scientific documents is challenging due to their varied, unstructured chemical formats and complex document layouts. To address this, we introduce MolMole, a vision-based deep learning framework that unifies molecule detection, reaction diagram parsing, and optical chemical structure recognition (OCSR) into a single pipeline for automating the extraction of chemical data directly from page-level documents. Recognizing the lack of a standard page-level benchmark and evaluation metric, we also present a testset of 550 pages annotated with molecule bounding boxes, reaction labels, and MOLfiles, along with a novel evaluation metric. Experimental results demonstrate that MolMole outperforms existing toolkits on both our benchmark and public datasets. The benchmark testset will be publicly available, and the MolMole toolkit will be accessible soon through an interactive demo on the LG AI Research website. For commercial inquiries, please contact us at \href{mailto:contact_ddu@lgresearch.ai}{contact\_ddu@lgresearch.ai}.
See It All: Contextualized Late Aggregation for 3D Dense Captioning
Aug 14, 2024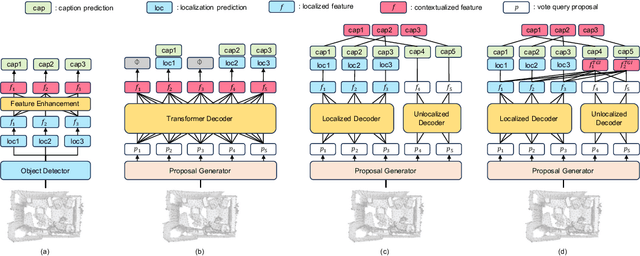
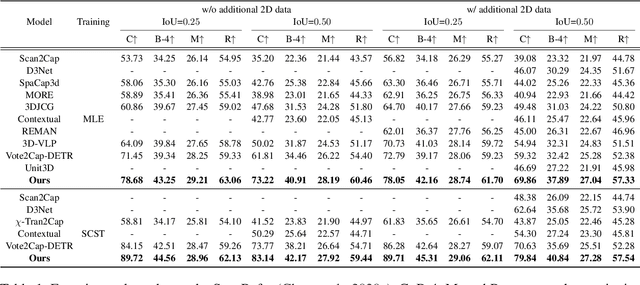
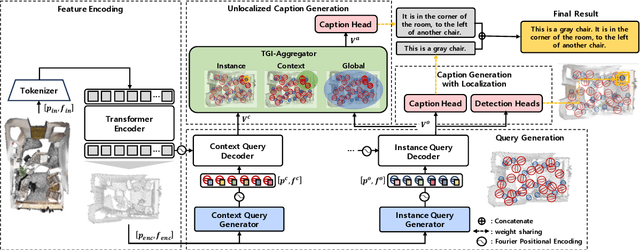
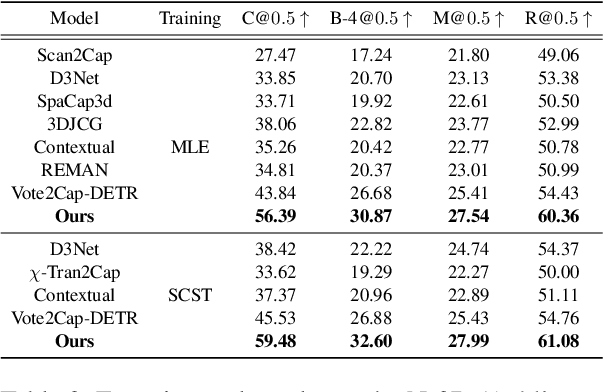
3D dense captioning is a task to localize objects in a 3D scene and generate descriptive sentences for each object. Recent approaches in 3D dense captioning have adopted transformer encoder-decoder frameworks from object detection to build an end-to-end pipeline without hand-crafted components. However, these approaches struggle with contradicting objectives where a single query attention has to simultaneously view both the tightly localized object regions and contextual environment. To overcome this challenge, we introduce SIA (See-It-All), a transformer pipeline that engages in 3D dense captioning with a novel paradigm called late aggregation. SIA simultaneously decodes two sets of queries-context query and instance query. The instance query focuses on localization and object attribute descriptions, while the context query versatilely captures the region-of-interest of relationships between multiple objects or with the global scene, then aggregated afterwards (i.e., late aggregation) via simple distance-based measures. To further enhance the quality of contextualized caption generation, we design a novel aggregator to generate a fully informed caption based on the surrounding context, the global environment, and object instances. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.
Universal Noise Annotation: Unveiling the Impact of Noisy annotation on Object Detection
Dec 21, 2023For object detection task with noisy labels, it is important to consider not only categorization noise, as in image classification, but also localization noise, missing annotations, and bogus bounding boxes. However, previous studies have only addressed certain types of noise (e.g., localization or categorization). In this paper, we propose Universal-Noise Annotation (UNA), a more practical setting that encompasses all types of noise that can occur in object detection, and analyze how UNA affects the performance of the detector. We analyzed the development direction of previous works of detection algorithms and examined the factors that impact the robustness of detection model learning method. We open-source the code for injecting UNA into the dataset and all the training log and weight are also shared.
Misalign, Contrast then Distill: Rethinking Misalignments in Language-Image Pretraining
Dec 19, 2023Contrastive Language-Image Pretraining has emerged as a prominent approach for training vision and text encoders with uncurated image-text pairs from the web. To enhance data-efficiency, recent efforts have introduced additional supervision terms that involve random-augmented views of the image. However, since the image augmentation process is unaware of its text counterpart, this procedure could cause various degrees of image-text misalignments during training. Prior methods either disregarded this discrepancy or introduced external models to mitigate the impact of misalignments during training. In contrast, we propose a novel metric learning approach that capitalizes on these misalignments as an additional training source, which we term "Misalign, Contrast then Distill (MCD)". Unlike previous methods that treat augmented images and their text counterparts as simple positive pairs, MCD predicts the continuous scales of misalignment caused by the augmentation. Our extensive experimental results show that our proposed MCD achieves state-of-the-art transferability in multiple classification and retrieval downstream datasets.
Expediting Contrastive Language-Image Pretraining via Self-distilled Encoders
Dec 19, 2023Recent advances in vision language pretraining (VLP) have been largely attributed to the large-scale data collected from the web. However, uncurated dataset contains weakly correlated image-text pairs, causing data inefficiency. To address the issue, knowledge distillation have been explored at the expense of extra image and text momentum encoders to generate teaching signals for misaligned image-text pairs. In this paper, our goal is to resolve the misalignment problem with an efficient distillation framework. To this end, we propose ECLIPSE: Expediting Contrastive Language-Image Pretraining with Self-distilled Encoders. ECLIPSE features a distinctive distillation architecture wherein a shared text encoder is utilized between an online image encoder and a momentum image encoder. This strategic design choice enables the distillation to operate within a unified projected space of text embedding, resulting in better performance. Based on the unified text embedding space, ECLIPSE compensates for the additional computational cost of the momentum image encoder by expediting the online image encoder. Through our extensive experiments, we validate that there is a sweet spot between expedition and distillation where the partial view from the expedited online image encoder interacts complementarily with the momentum teacher. As a result, ECLIPSE outperforms its counterparts while achieving substantial acceleration in inference speed.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Story Visualization by Online Text Augmentation with Context Memory
Aug 19, 2023
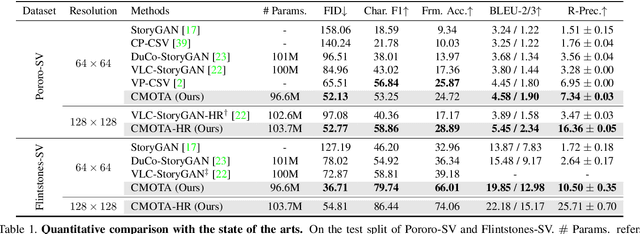
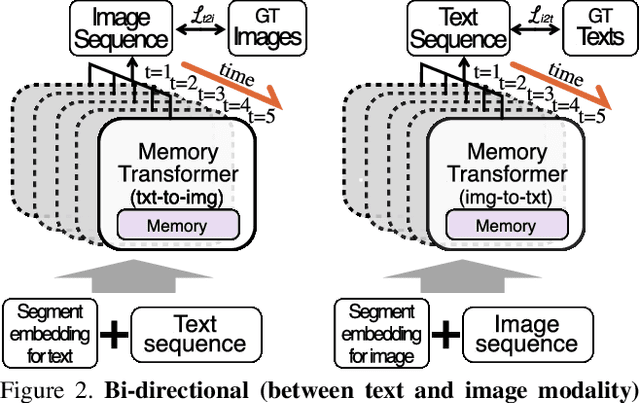
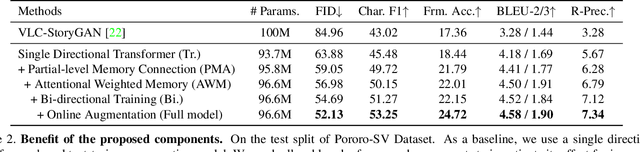
Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformer framework with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training for better generalization to the language variation at inference. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.
ReConPatch : Contrastive Patch Representation Learning for Industrial Anomaly Detection
May 26, 2023



Anomaly detection is crucial to the advanced identification of product defects such as incorrect parts, misaligned components, and damages in industrial manufacturing. Due to the rare observations and unknown types of defects, anomaly detection is considered to be challenging in machine learning. To overcome this difficulty, recent approaches utilize the common visual representations from natural image datasets and distill the relevant features. However, existing approaches still have the discrepancy between the pre-trained feature and the target data, or require the input augmentation which should be carefully designed particularly for the industrial dataset. In this paper, we introduce ReConPatch, which constructs discriminative features for anomaly detection by training a linear modulation attached to a pre-trained model. ReConPatch employs contrastive representation learning to collect and distribute features in a way that produces a target-oriented and easily separable representation. To address the absence of labeled pairs for the contrastive learning, we utilize two similarity measures, pairwise and contextual similarities, between data representations as a pseudo-label. Unlike previous work, ReConPatch achieves robust anomaly detection performance without extensive input augmentation. Our method achieves the state-of-the-art anomaly detection performance (99.72%) for the widely used and challenging MVTec AD dataset.
Significantly improving zero-shot X-ray pathology classification via fine-tuning pre-trained image-text encoders
Dec 14, 2022Deep neural networks have been successfully adopted to diverse domains including pathology classification based on medical images. However, large-scale and high-quality data to train powerful neural networks are rare in the medical domain as the labeling must be done by qualified experts. Researchers recently tackled this problem with some success by taking advantage of models pre-trained on large-scale general domain data. Specifically, researchers took contrastive image-text encoders (e.g., CLIP) and fine-tuned it with chest X-ray images and paired reports to perform zero-shot pathology classification, thus completely removing the need for pathology-annotated images to train a classification model. Existing studies, however, fine-tuned the pre-trained model with the same contrastive learning objective, and failed to exploit the multi-labeled nature of medical image-report pairs. In this paper, we propose a new fine-tuning strategy based on sentence sampling and positive-pair loss relaxation for improving the downstream zero-shot pathology classification performance, which can be applied to any pre-trained contrastive image-text encoders. Our method consistently showed dramatically improved zero-shot pathology classification performance on four different chest X-ray datasets and 3 different pre-trained models (5.77% average AUROC increase). In particular, fine-tuning CLIP with our method showed much comparable or marginally outperformed to board-certified radiologists (0.619 vs 0.625 in F1 score and 0.530 vs 0.544 in MCC) in zero-shot classification of five prominent diseases from the CheXpert dataset.