 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolMole: Molecule Mining from Scientific Literature
May 08, 2025The extraction of molecular structures and reaction data from scientific documents is challenging due to their varied, unstructured chemical formats and complex document layouts. To address this, we introduce MolMole, a vision-based deep learning framework that unifies molecule detection, reaction diagram parsing, and optical chemical structure recognition (OCSR) into a single pipeline for automating the extraction of chemical data directly from page-level documents. Recognizing the lack of a standard page-level benchmark and evaluation metric, we also present a testset of 550 pages annotated with molecule bounding boxes, reaction labels, and MOLfiles, along with a novel evaluation metric. Experimental results demonstrate that MolMole outperforms existing toolkits on both our benchmark and public datasets. The benchmark testset will be publicly available, and the MolMole toolkit will be accessible soon through an interactive demo on the LG AI Research website. For commercial inquiries, please contact us at \href{mailto:contact_ddu@lgresearch.ai}{contact\_ddu@lgresearch.ai}.
Universal Noise Annotation: Unveiling the Impact of Noisy annotation on Object Detection
Dec 21, 2023For object detection task with noisy labels, it is important to consider not only categorization noise, as in image classification, but also localization noise, missing annotations, and bogus bounding boxes. However, previous studies have only addressed certain types of noise (e.g., localization or categorization). In this paper, we propose Universal-Noise Annotation (UNA), a more practical setting that encompasses all types of noise that can occur in object detection, and analyze how UNA affects the performance of the detector. We analyzed the development direction of previous works of detection algorithms and examined the factors that impact the robustness of detection model learning method. We open-source the code for injecting UNA into the dataset and all the training log and weight are also shared.
SplitNet: Learnable Clean-Noisy Label Splitting for Learning with Noisy Labels
Nov 20, 2022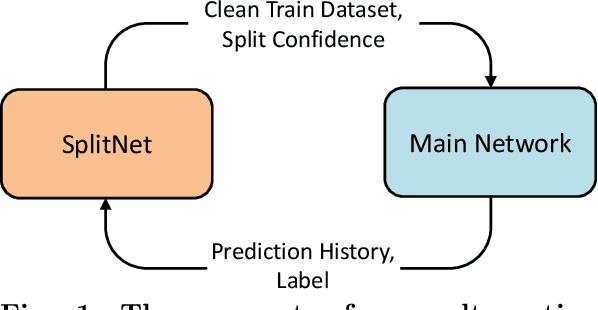
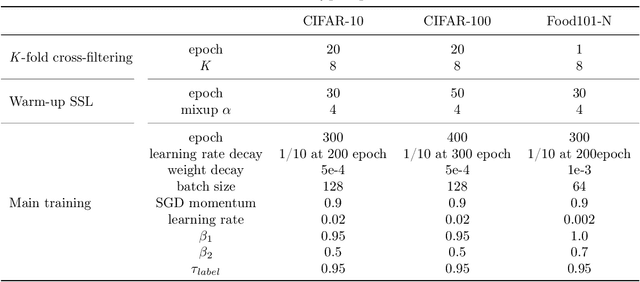
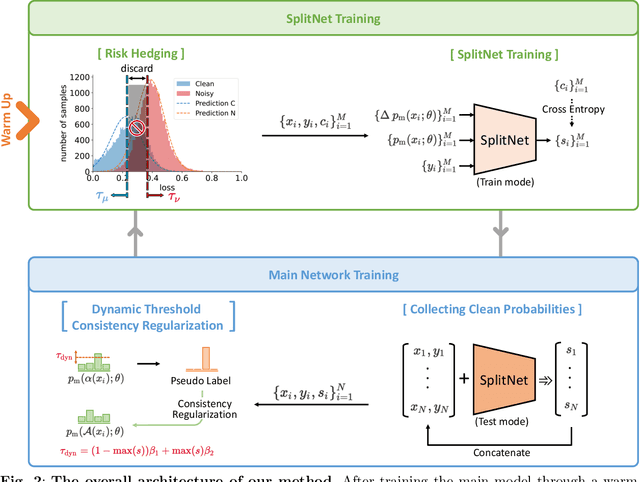
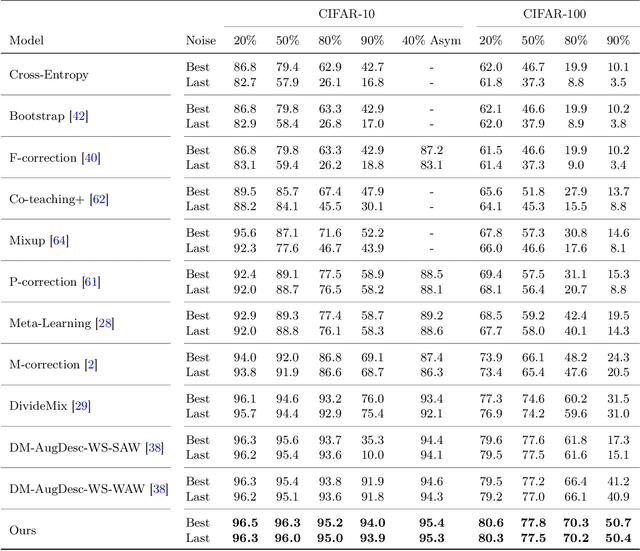
Annotating the dataset with high-quality labels is crucial for performance of deep network, but in real world scenarios, the labels are often contaminated by noise. To address this, some methods were proposed to automatically split clean and noisy labels, and learn a semi-supervised learner in a Learning with Noisy Labels (LNL) framework. However, they leverage a handcrafted module for clean-noisy label splitting, which induces a confirmation bias in the semi-supervised learning phase and limits the performance. In this paper, we for the first time present a learnable module for clean-noisy label splitting, dubbed SplitNet, and a novel LNL framework which complementarily trains the SplitNet and main network for the LNL task. We propose to use a dynamic threshold based on a split confidence by SplitNet to better optimize semi-supervised learner. To enhance SplitNet training, we also present a risk hedging method. Our proposed method performs at a state-of-the-art level especially in high noise ratio settings on various LNL benchmarks.
3D GAN Inversion with Pose Optimization
Oct 17, 2022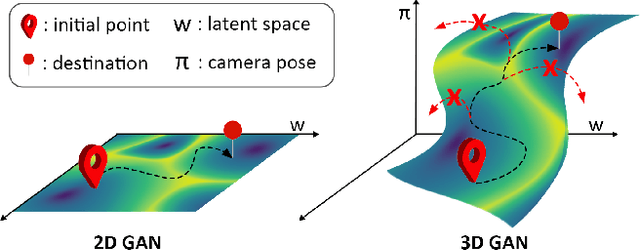


With the recent advances in NeRF-based 3D aware GANs quality, projecting an image into the latent space of these 3D-aware GANs has a natural advantage over 2D GAN inversion: not only does it allow multi-view consistent editing of the projected image, but it also enables 3D reconstruction and novel view synthesis when given only a single image. However, the explicit viewpoint control acts as a main hindrance in the 3D GAN inversion process, as both camera pose and latent code have to be optimized simultaneously to reconstruct the given image. Most works that explore the latent space of the 3D-aware GANs rely on ground-truth camera viewpoint or deformable 3D model, thus limiting their applicability. In this work, we introduce a generalizable 3D GAN inversion method that infers camera viewpoint and latent code simultaneously to enable multi-view consistent semantic image editing. The key to our approach is to leverage pre-trained estimators for better initialization and utilize the pixel-wise depth calculated from NeRF parameters to better reconstruct the given image. We conduct extensive experiments on image reconstruction and editing both quantitatively and qualitatively, and further compare our results with 2D GAN-based editing to demonstrate the advantages of utilizing the latent space of 3D GANs. Additional results and visualizations are available at https://3dgan-inversion.github.io .
Towards Flexible Inductive Bias via Progressive Reparameterization Scheduling
Oct 04, 2022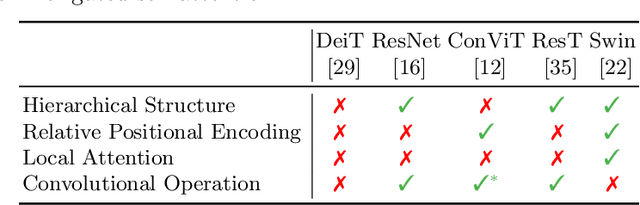
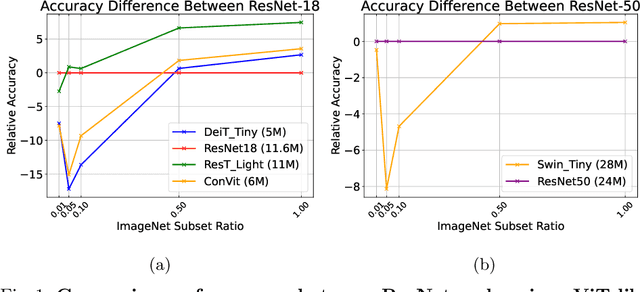
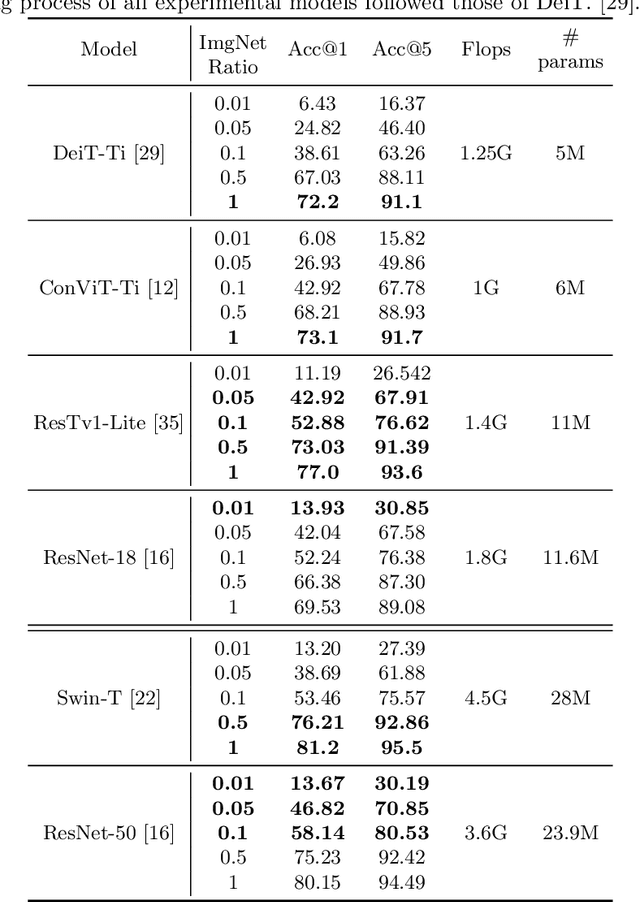
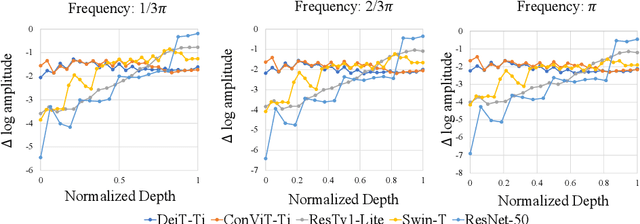
There are two de facto standard architectures in recent computer vision: Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Strong inductive biases of convolutions help the model learn sample effectively, but such strong biases also limit the upper bound of CNNs when sufficient data are available. On the contrary, ViT is inferior to CNNs for small data but superior for sufficient data. Recent approaches attempt to combine the strengths of these two architectures. However, we show these approaches overlook that the optimal inductive bias also changes according to the target data scale changes by comparing various models' accuracy on subsets of sampled ImageNet at different ratios. In addition, through Fourier analysis of feature maps, the model's response patterns according to signal frequency changes, we observe which inductive bias is advantageous for each data scale. The more convolution-like inductive bias is included in the model, the smaller the data scale is required where the ViT-like model outperforms the ResNet performance. To obtain a model with flexible inductive bias on the data scale, we show reparameterization can interpolate inductive bias between convolution and self-attention. By adjusting the number of epochs the model stays in the convolution, we show that reparameterization from convolution to self-attention interpolates the Fourier analysis pattern between CNNs and ViTs. Adapting these findings, we propose Progressive Reparameterization Scheduling (PRS), in which reparameterization adjusts the required amount of convolution-like or self-attention-like inductive bias per layer. For small-scale datasets, our PRS performs reparameterization from convolution to self-attention linearly faster at the late stage layer. PRS outperformed previous studies on the small-scale dataset, e.g., CIFAR-100.
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
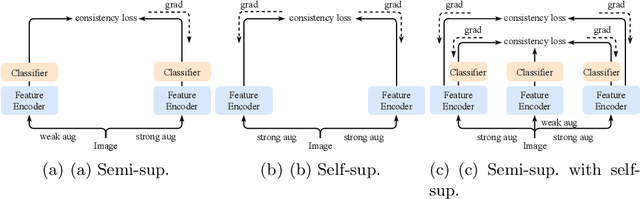
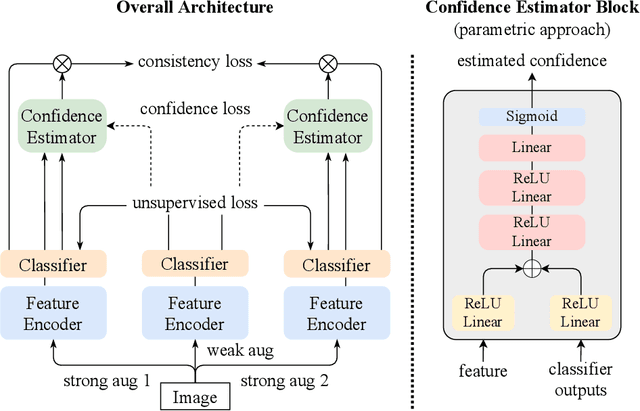
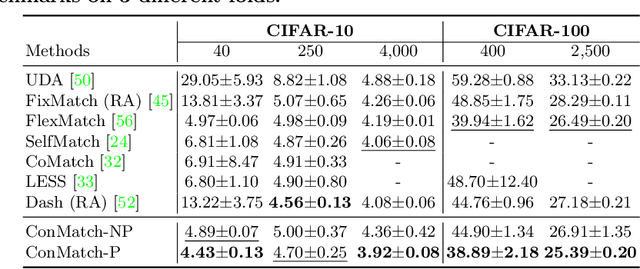
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels
Apr 05, 2022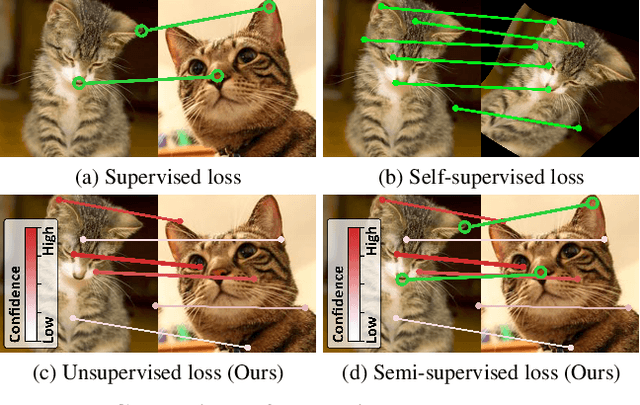
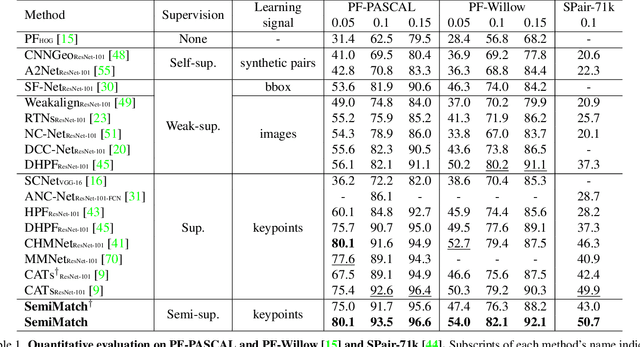
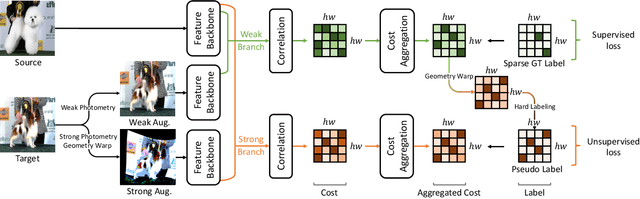
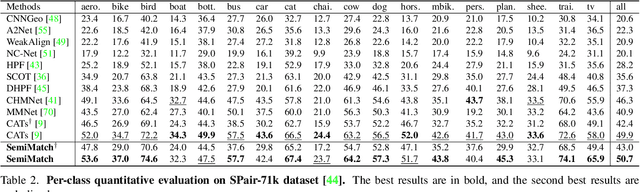
Establishing dense correspondences across semantically similar images remains a challenging task due to the significant intra-class variations and background clutters. Traditionally, a supervised learning was used for training the models, which required tremendous manually-labeled data, while some methods suggested a self-supervised or weakly-supervised learning to mitigate the reliance on the labeled data, but with limited performance. In this paper, we present a simple, but effective solution for semantic correspondence that learns the networks in a semi-supervised manner by supplementing few ground-truth correspondences via utilization of a large amount of confident correspondences as pseudo-labels, called SemiMatch. Specifically, our framework generates the pseudo-labels using the model's prediction itself between source and weakly-augmented target, and uses pseudo-labels to learn the model again between source and strongly-augmented target, which improves the robustness of the model. We also present a novel confidence measure for pseudo-labels and data augmentation tailored for semantic correspondence. In experiments, SemiMatch achieves state-of-the-art performance on various benchmarks, especially on PF-Willow by a large margin.
AggMatch: Aggregating Pseudo Labels for Semi-Supervised Learning
Jan 25, 2022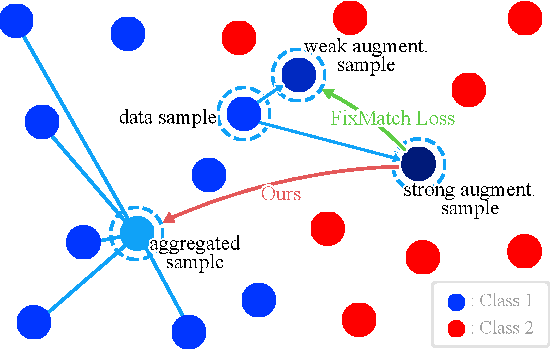
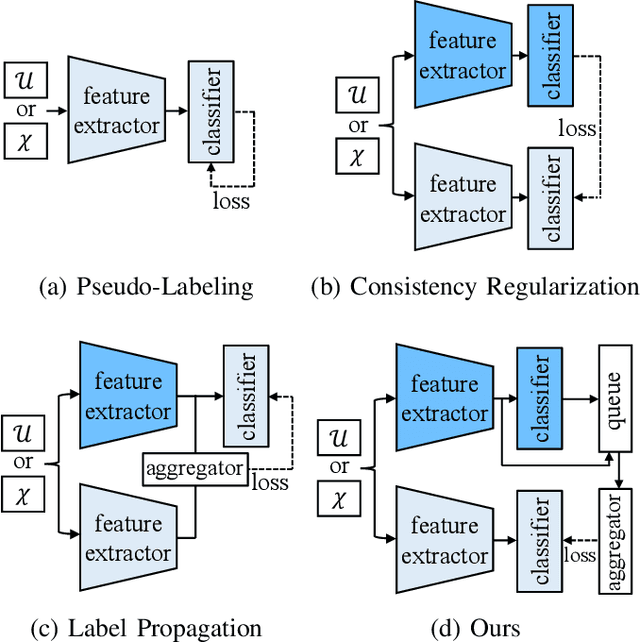
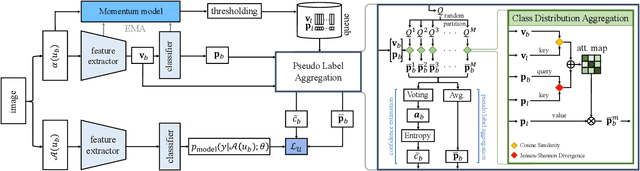
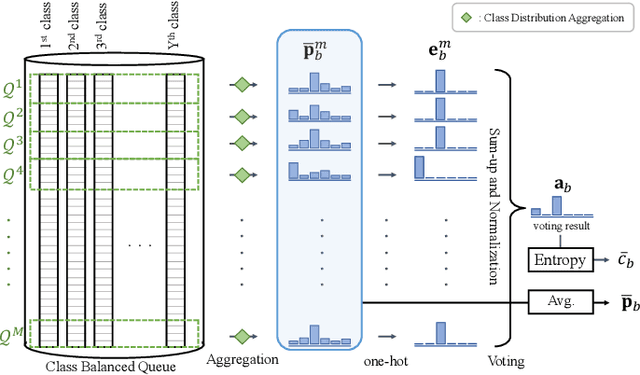
Semi-supervised learning (SSL) has recently proven to be an effective paradigm for leveraging a huge amount of unlabeled data while mitigating the reliance on large labeled data. Conventional methods focused on extracting a pseudo label from individual unlabeled data sample and thus they mostly struggled to handle inaccurate or noisy pseudo labels, which degenerate performance. In this paper, we address this limitation with a novel SSL framework for aggregating pseudo labels, called AggMatch, which refines initial pseudo labels by using different confident instances. Specifically, we introduce an aggregation module for consistency regularization framework that aggregates the initial pseudo labels based on the similarity between the instances. To enlarge the aggregation candidates beyond the mini-batch, we present a class-balanced confidence-aware queue built with the momentum model, encouraging to provide more stable and consistent aggregation. We also propose a novel uncertainty-based confidence measure for the pseudo label by considering the consensus among multiple hypotheses with different subsets of the queue. We conduct experiments to demonstrate the effectiveness of AggMatch over the latest methods on standard benchmarks and provide extensive analyses.