 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar-Based NLoS Pedestrian Localization for Darting-Out Scenarios Near Parked Vehicles with Camera-Assisted Point Cloud Interpretation
Aug 06, 2025



The presence of Non-Line-of-Sight (NLoS) blind spots resulting from roadside parking in urban environments poses a significant challenge to road safety, particularly due to the sudden emergence of pedestrians. mmWave technology leverages diffraction and reflection to observe NLoS regions, and recent studies have demonstrated its potential for detecting obscured objects. However, existing approaches predominantly rely on predefined spatial information or assume simple wall reflections, thereby limiting their generalizability and practical applicability. A particular challenge arises in scenarios where pedestrians suddenly appear from between parked vehicles, as these parked vehicles act as temporary spatial obstructions. Furthermore, since parked vehicles are dynamic and may relocate over time, spatial information obtained from satellite maps or other predefined sources may not accurately reflect real-time road conditions, leading to erroneous sensor interpretations. To address this limitation, we propose an NLoS pedestrian localization framework that integrates monocular camera image with 2D radar point cloud (PCD) data. The proposed method initially detects parked vehicles through image segmentation, estimates depth to infer approximate spatial characteristics, and subsequently refines this information using 2D radar PCD to achieve precise spatial inference. Experimental evaluations conducted in real-world urban road environments demonstrate that the proposed approach enhances early pedestrian detection and contributes to improved road safety. Supplementary materials are available at https://hiyeun.github.io/NLoS/.
S^4M: Boosting Semi-Supervised Instance Segmentation with SAM
Apr 07, 2025Semi-supervised instance segmentation poses challenges due to limited labeled data, causing difficulties in accurately localizing distinct object instances. Current teacher-student frameworks still suffer from performance constraints due to unreliable pseudo-label quality stemming from limited labeled data. While the Segment Anything Model (SAM) offers robust segmentation capabilities at various granularities, directly applying SAM to this task introduces challenges such as class-agnostic predictions and potential over-segmentation. To address these complexities, we carefully integrate SAM into the semi-supervised instance segmentation framework, developing a novel distillation method that effectively captures the precise localization capabilities of SAM without compromising semantic recognition. Furthermore, we incorporate pseudo-label refinement as well as a specialized data augmentation with the refined pseudo-labels, resulting in superior performance. We establish state-of-the-art performance, and provide comprehensive experiments and ablation studies to validate the effectiveness of our proposed approach.
ContextMix: A context-aware data augmentation method for industrial visual inspection systems
Jan 18, 2024



While deep neural networks have achieved remarkable performance, data augmentation has emerged as a crucial strategy to mitigate overfitting and enhance network performance. These techniques hold particular significance in industrial manufacturing contexts. Recently, image mixing-based methods have been introduced, exhibiting improved performance on public benchmark datasets. However, their application to industrial tasks remains challenging. The manufacturing environment generates massive amounts of unlabeled data on a daily basis, with only a few instances of abnormal data occurrences. This leads to severe data imbalance. Thus, creating well-balanced datasets is not straightforward due to the high costs associated with labeling. Nonetheless, this is a crucial step for enhancing productivity. For this reason, we introduce ContextMix, a method tailored for industrial applications and benchmark datasets. ContextMix generates novel data by resizing entire images and integrating them into other images within the batch. This approach enables our method to learn discriminative features based on varying sizes from resized images and train informative secondary features for object recognition using occluded images. With the minimal additional computation cost of image resizing, ContextMix enhances performance compared to existing augmentation techniques. We evaluate its effectiveness across classification, detection, and segmentation tasks using various network architectures on public benchmark datasets. Our proposed method demonstrates improved results across a range of robustness tasks. Its efficacy in real industrial environments is particularly noteworthy, as demonstrated using the passive component dataset.
Proxy Anchor-based Unsupervised Learning for Continuous Generalized Category Discovery
Jul 20, 2023
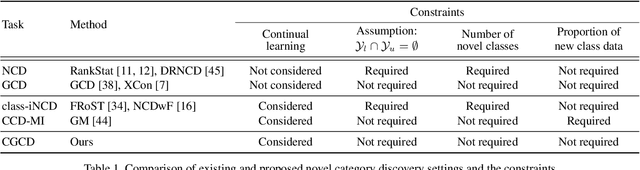
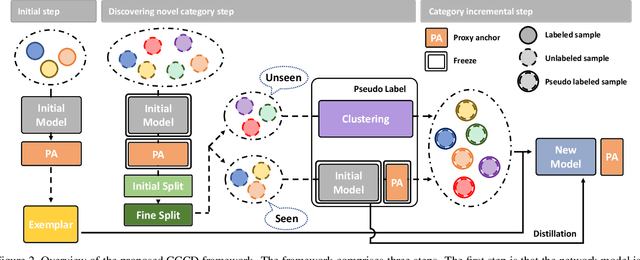
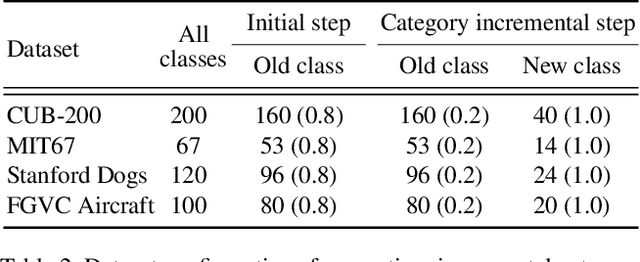
Recent advances in deep learning have significantly improved the performance of various computer vision applications. However, discovering novel categories in an incremental learning scenario remains a challenging problem due to the lack of prior knowledge about the number and nature of new categories. Existing methods for novel category discovery are limited by their reliance on labeled datasets and prior knowledge about the number of novel categories and the proportion of novel samples in the batch. To address the limitations and more accurately reflect real-world scenarios, in this paper, we propose a novel unsupervised class incremental learning approach for discovering novel categories on unlabeled sets without prior knowledge. The proposed method fine-tunes the feature extractor and proxy anchors on labeled sets, then splits samples into old and novel categories and clusters on the unlabeled dataset. Furthermore, the proxy anchors-based exemplar generates representative category vectors to mitigate catastrophic forgetting. Experimental results demonstrate that our proposed approach outperforms the state-of-the-art methods on fine-grained datasets under real-world scenarios.
SplitNet: Learnable Clean-Noisy Label Splitting for Learning with Noisy Labels
Nov 20, 2022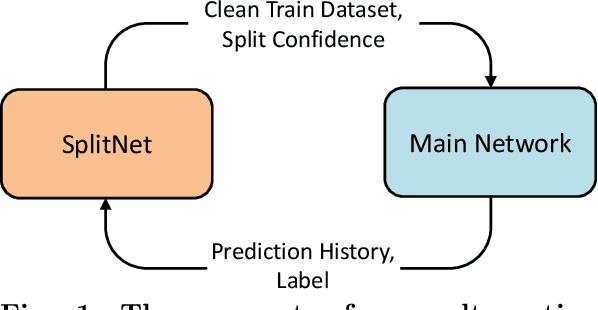
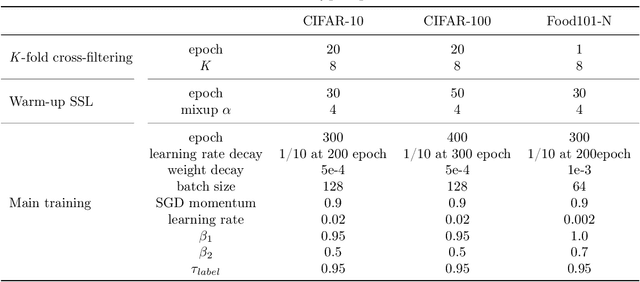
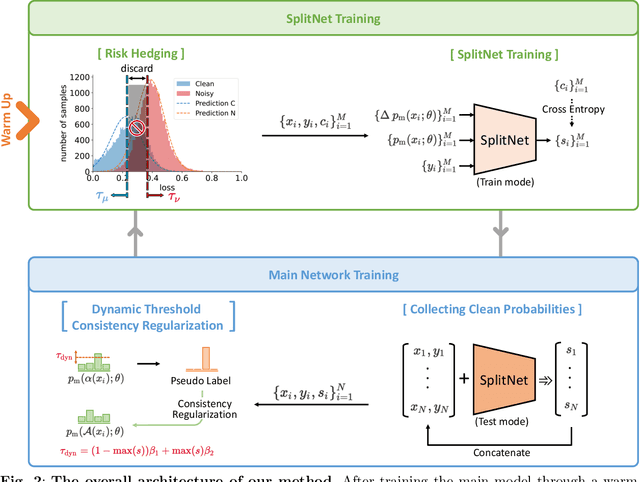
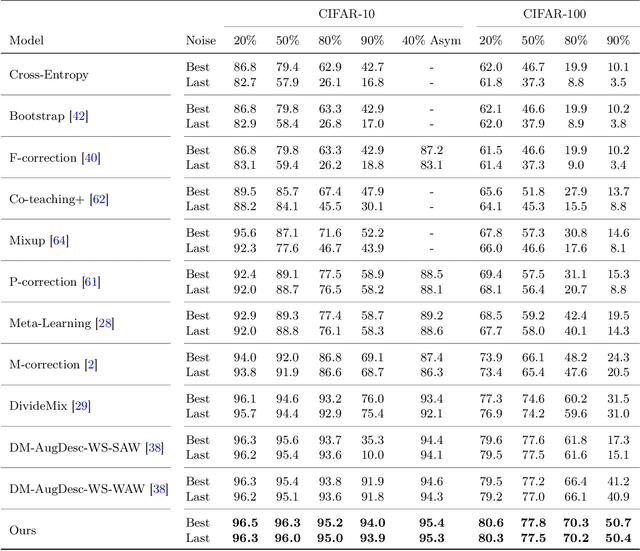
Annotating the dataset with high-quality labels is crucial for performance of deep network, but in real world scenarios, the labels are often contaminated by noise. To address this, some methods were proposed to automatically split clean and noisy labels, and learn a semi-supervised learner in a Learning with Noisy Labels (LNL) framework. However, they leverage a handcrafted module for clean-noisy label splitting, which induces a confirmation bias in the semi-supervised learning phase and limits the performance. In this paper, we for the first time present a learnable module for clean-noisy label splitting, dubbed SplitNet, and a novel LNL framework which complementarily trains the SplitNet and main network for the LNL task. We propose to use a dynamic threshold based on a split confidence by SplitNet to better optimize semi-supervised learner. To enhance SplitNet training, we also present a risk hedging method. Our proposed method performs at a state-of-the-art level especially in high noise ratio settings on various LNL benchmarks.
AI-KD: Adversarial learning and Implicit regularization for self-Knowledge Distillation
Nov 20, 2022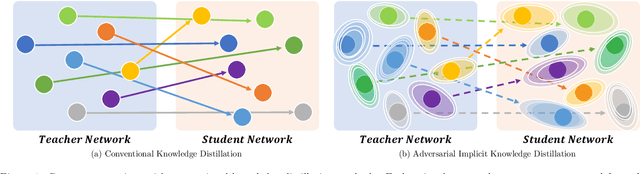
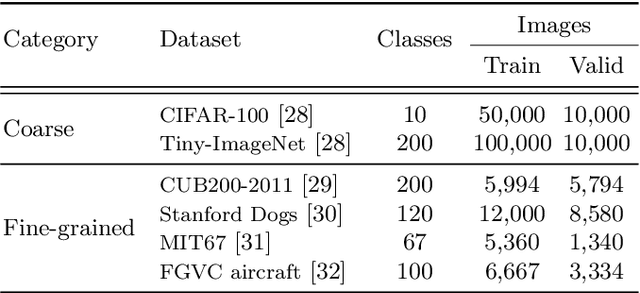
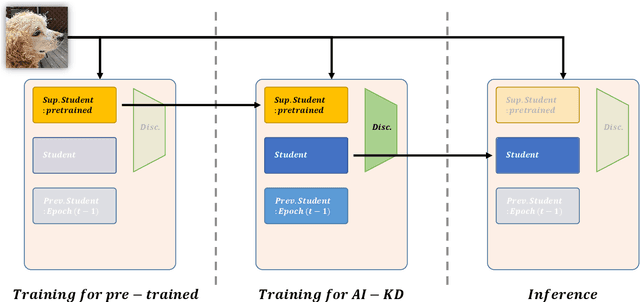
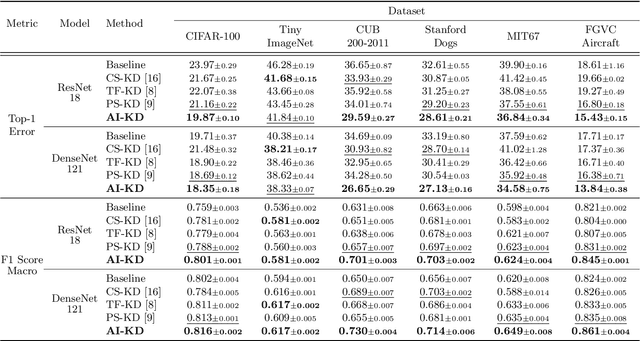
We present a novel adversarial penalized self-knowledge distillation method, named adversarial learning and implicit regularization for self-knowledge distillation (AI-KD), which regularizes the training procedure by adversarial learning and implicit distillations. Our model not only distills the deterministic and progressive knowledge which are from the pre-trained and previous epoch predictive probabilities but also transfers the knowledge of the deterministic predictive distributions using adversarial learning. The motivation is that the self-knowledge distillation methods regularize the predictive probabilities with soft targets, but the exact distributions may be hard to predict. Our method deploys a discriminator to distinguish the distributions between the pre-trained and student models while the student model is trained to fool the discriminator in the trained procedure. Thus, the student model not only can learn the pre-trained model's predictive probabilities but also align the distributions between the pre-trained and student models. We demonstrate the effectiveness of the proposed method with network architectures on multiple datasets and show the proposed method achieves better performance than state-of-the-art methods.
Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels
Apr 05, 2022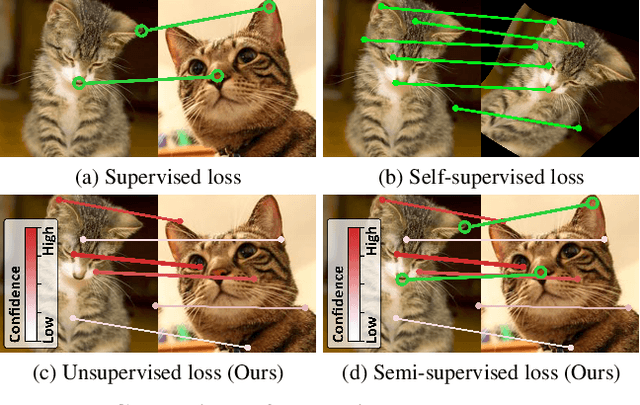
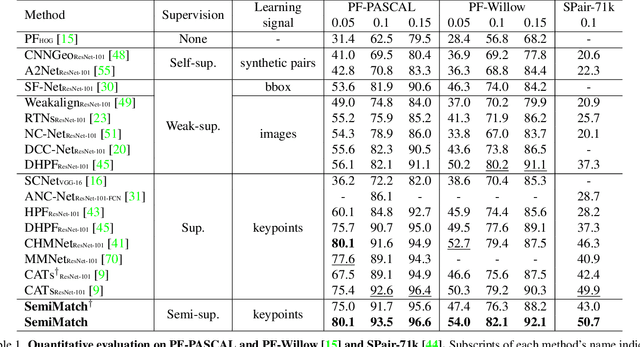
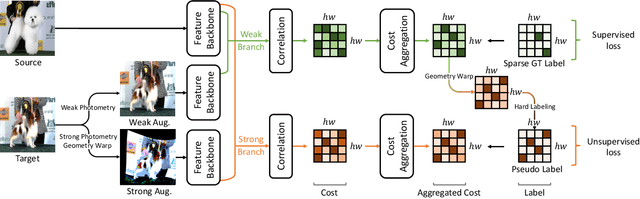
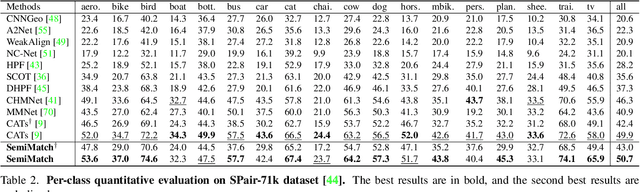
Establishing dense correspondences across semantically similar images remains a challenging task due to the significant intra-class variations and background clutters. Traditionally, a supervised learning was used for training the models, which required tremendous manually-labeled data, while some methods suggested a self-supervised or weakly-supervised learning to mitigate the reliance on the labeled data, but with limited performance. In this paper, we present a simple, but effective solution for semantic correspondence that learns the networks in a semi-supervised manner by supplementing few ground-truth correspondences via utilization of a large amount of confident correspondences as pseudo-labels, called SemiMatch. Specifically, our framework generates the pseudo-labels using the model's prediction itself between source and weakly-augmented target, and uses pseudo-labels to learn the model again between source and strongly-augmented target, which improves the robustness of the model. We also present a novel confidence measure for pseudo-labels and data augmentation tailored for semantic correspondence. In experiments, SemiMatch achieves state-of-the-art performance on various benchmarks, especially on PF-Willow by a large margin.
AggMatch: Aggregating Pseudo Labels for Semi-Supervised Learning
Jan 25, 2022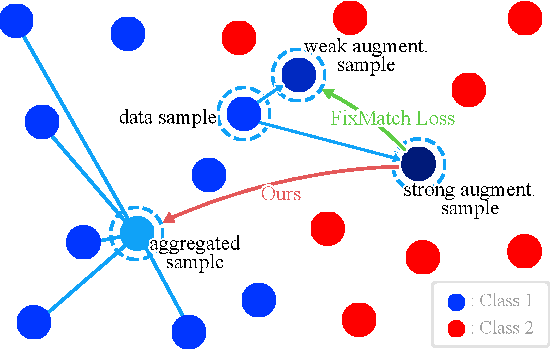
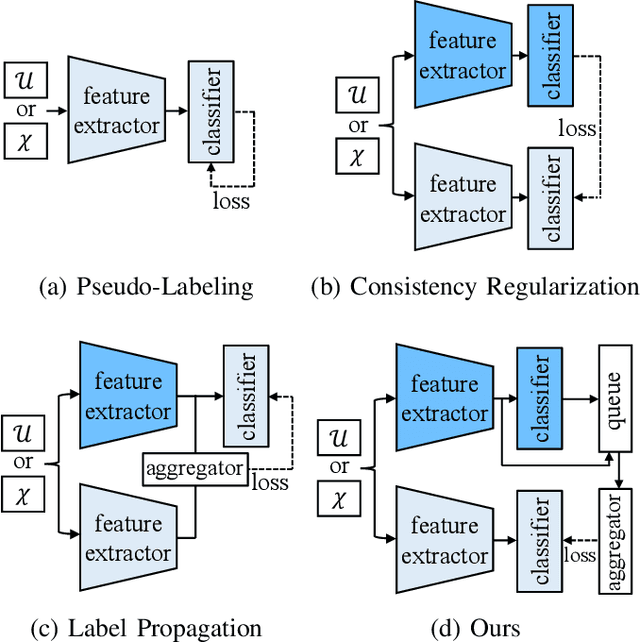
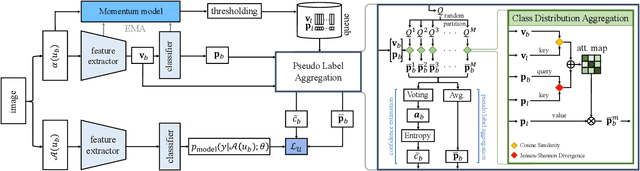
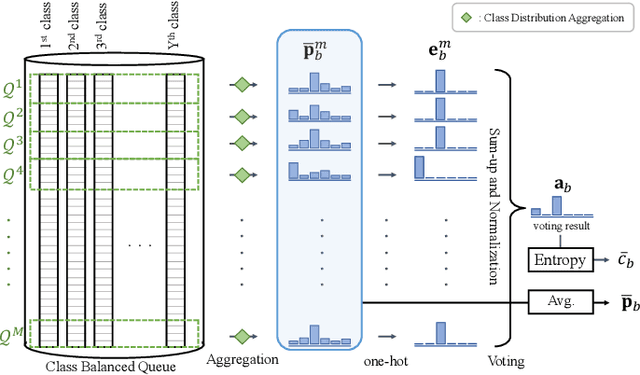
Semi-supervised learning (SSL) has recently proven to be an effective paradigm for leveraging a huge amount of unlabeled data while mitigating the reliance on large labeled data. Conventional methods focused on extracting a pseudo label from individual unlabeled data sample and thus they mostly struggled to handle inaccurate or noisy pseudo labels, which degenerate performance. In this paper, we address this limitation with a novel SSL framework for aggregating pseudo labels, called AggMatch, which refines initial pseudo labels by using different confident instances. Specifically, we introduce an aggregation module for consistency regularization framework that aggregates the initial pseudo labels based on the similarity between the instances. To enlarge the aggregation candidates beyond the mini-batch, we present a class-balanced confidence-aware queue built with the momentum model, encouraging to provide more stable and consistent aggregation. We also propose a novel uncertainty-based confidence measure for the pseudo label by considering the consensus among multiple hypotheses with different subsets of the queue. We conduct experiments to demonstrate the effectiveness of AggMatch over the latest methods on standard benchmarks and provide extensive analyses.