 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS^4M: Boosting Semi-Supervised Instance Segmentation with SAM
Apr 07, 2025Semi-supervised instance segmentation poses challenges due to limited labeled data, causing difficulties in accurately localizing distinct object instances. Current teacher-student frameworks still suffer from performance constraints due to unreliable pseudo-label quality stemming from limited labeled data. While the Segment Anything Model (SAM) offers robust segmentation capabilities at various granularities, directly applying SAM to this task introduces challenges such as class-agnostic predictions and potential over-segmentation. To address these complexities, we carefully integrate SAM into the semi-supervised instance segmentation framework, developing a novel distillation method that effectively captures the precise localization capabilities of SAM without compromising semantic recognition. Furthermore, we incorporate pseudo-label refinement as well as a specialized data augmentation with the refined pseudo-labels, resulting in superior performance. We establish state-of-the-art performance, and provide comprehensive experiments and ablation studies to validate the effectiveness of our proposed approach.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Proxy Anchor-based Unsupervised Learning for Continuous Generalized Category Discovery
Jul 20, 2023
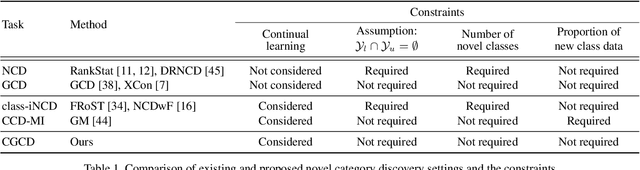
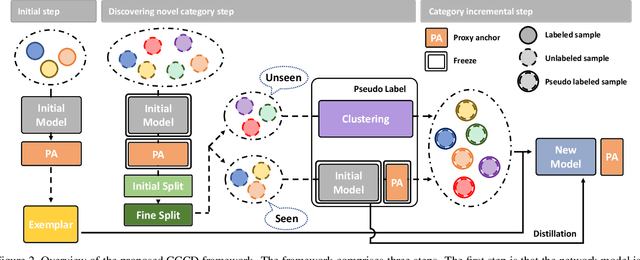
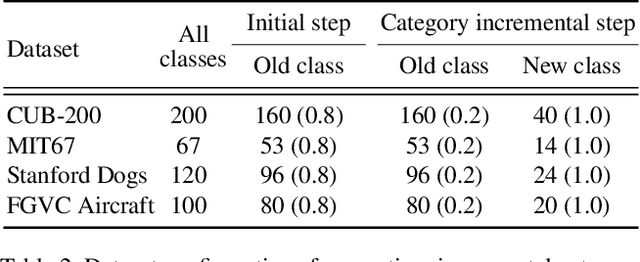
Recent advances in deep learning have significantly improved the performance of various computer vision applications. However, discovering novel categories in an incremental learning scenario remains a challenging problem due to the lack of prior knowledge about the number and nature of new categories. Existing methods for novel category discovery are limited by their reliance on labeled datasets and prior knowledge about the number of novel categories and the proportion of novel samples in the batch. To address the limitations and more accurately reflect real-world scenarios, in this paper, we propose a novel unsupervised class incremental learning approach for discovering novel categories on unlabeled sets without prior knowledge. The proposed method fine-tunes the feature extractor and proxy anchors on labeled sets, then splits samples into old and novel categories and clusters on the unlabeled dataset. Furthermore, the proxy anchors-based exemplar generates representative category vectors to mitigate catastrophic forgetting. Experimental results demonstrate that our proposed approach outperforms the state-of-the-art methods on fine-grained datasets under real-world scenarios.
AI-KD: Adversarial learning and Implicit regularization for self-Knowledge Distillation
Nov 20, 2022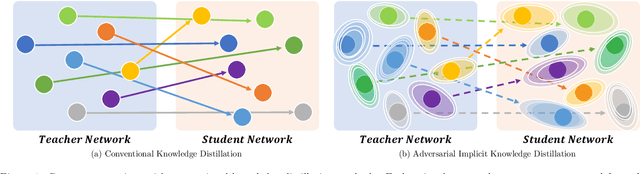
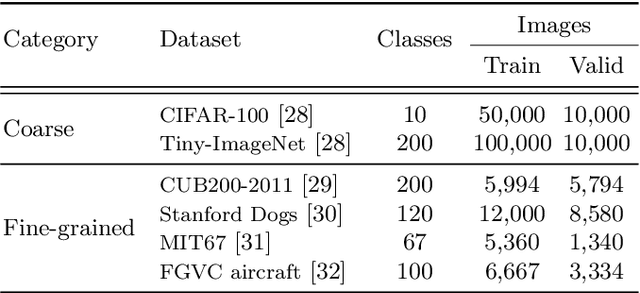
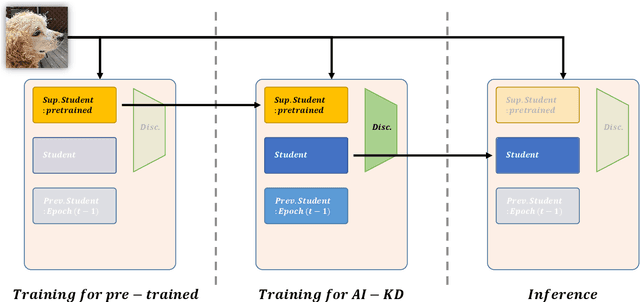
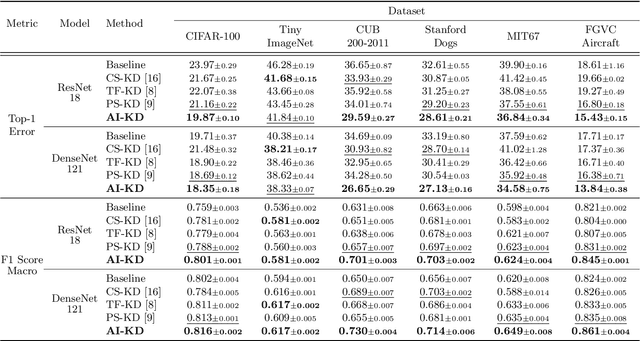
We present a novel adversarial penalized self-knowledge distillation method, named adversarial learning and implicit regularization for self-knowledge distillation (AI-KD), which regularizes the training procedure by adversarial learning and implicit distillations. Our model not only distills the deterministic and progressive knowledge which are from the pre-trained and previous epoch predictive probabilities but also transfers the knowledge of the deterministic predictive distributions using adversarial learning. The motivation is that the self-knowledge distillation methods regularize the predictive probabilities with soft targets, but the exact distributions may be hard to predict. Our method deploys a discriminator to distinguish the distributions between the pre-trained and student models while the student model is trained to fool the discriminator in the trained procedure. Thus, the student model not only can learn the pre-trained model's predictive probabilities but also align the distributions between the pre-trained and student models. We demonstrate the effectiveness of the proposed method with network architectures on multiple datasets and show the proposed method achieves better performance than state-of-the-art methods.