 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multimodal Gesture Recognition for Drone and Mobile Robot Teleoperation via Log-Likelihood Ratio Fusion
Mar 05, 2026Human operators are still frequently exposed to hazardous environments such as disaster zones and industrial facilities, where intuitive and reliable teleoperation of mobile robots and Unmanned Aerial Vehicles (UAVs) is essential. In this context, hands-free teleoperation enhances operator mobility and situational awareness, thereby improving safety in hazardous environments. While vision-based gesture recognition has been explored as one method for hands-free teleoperation, its performance often deteriorates under occlusions, lighting variations, and cluttered backgrounds, limiting its applicability in real-world operations. To overcome these limitations, we propose a multimodal gesture recognition framework that integrates inertial data (accelerometer, gyroscope, and orientation) from Apple Watches on both wrists with capacitive sensing signals from custom gloves. We design a late fusion strategy based on the log-likelihood ratio (LLR), which not only enhances recognition performance but also provides interpretability by quantifying modality-specific contributions. To support this research, we introduce a new dataset of 20 distinct gestures inspired by aircraft marshalling signals, comprising synchronized RGB video, IMU, and capacitive sensor data. Experimental results demonstrate that our framework achieves performance comparable to a state-of-the-art vision-based baseline while significantly reducing computational cost, model size, and training time, making it well suited for real-time robot control. We therefore underscore the potential of sensor-based multimodal fusion as a robust and interpretable solution for gesture-driven mobile robot and drone teleoperation.
OpenMarcie: Dataset for Multimodal Action Recognition in Industrial Environments
Mar 02, 2026Smart factories use advanced technologies to optimize production and increase efficiency. To this end, the recognition of worker activity allows for accurate quantification of performance metrics, improving efficiency holistically while contributing to worker safety. OpenMarcie is, to the best of our knowledge, the biggest multimodal dataset designed for human action monitoring in manufacturing environments. It includes data from wearables sensing modalities and cameras distributed in the surroundings. The dataset is structured around two experimental settings, involving a total of 36 participants. In the first setting, twelve participants perform a bicycle assembly and disassembly task under semi-realistic conditions without a fixed protocol, promoting divergent and goal-oriented problem-solving. The second experiment involves twenty-five volunteers (24 valid data) engaged in a 3D printer assembly task, with the 3D printer manufacturer's instructions provided to guide the volunteers in acquiring procedural knowledge. This setting also includes sequential collaborative assembly, where participants assess and correct each other's progress, reflecting real-world manufacturing dynamics. OpenMarcie includes over 37 hours of egocentric and exocentric, multimodal, and multipositional data, featuring eight distinct data types and more than 200 independent information channels. The dataset is benchmarked across three human activity recognition tasks: activity classification, open vocabulary captioning, and cross-modal alignment.
SImpHAR: Advancing impedance-based human activity recognition using 3D simulation and text-to-motion models
Jul 08, 2025
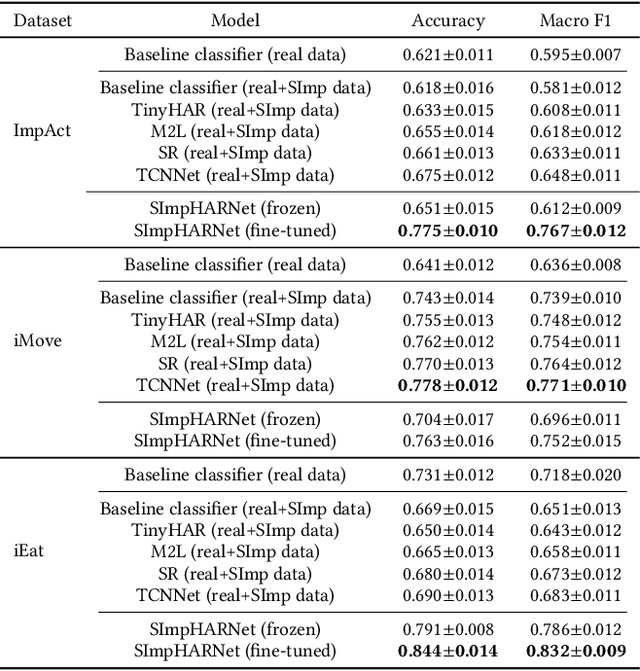


Human Activity Recognition (HAR) with wearable sensors is essential for applications in healthcare, fitness, and human-computer interaction. Bio-impedance sensing offers unique advantages for fine-grained motion capture but remains underutilized due to the scarcity of labeled data. We introduce SImpHAR, a novel framework addressing this limitation through two core contributions. First, we propose a simulation pipeline that generates realistic bio-impedance signals from 3D human meshes using shortest-path estimation, soft-body physics, and text-to-motion generation serving as a digital twin for data augmentation. Second, we design a two-stage training strategy with decoupled approach that enables broader activity coverage without requiring label-aligned synthetic data. We evaluate SImpHAR on our collected ImpAct dataset and two public benchmarks, showing consistent improvements over state-of-the-art methods, with gains of up to 22.3% and 21.8%, in terms of accuracy and macro F1 score, respectively. Our results highlight the promise of simulation-driven augmentation and modular training for impedance-based HAR.
TxP: Reciprocal Generation of Ground Pressure Dynamics and Activity Descriptions for Improving Human Activity Recognition
May 04, 2025
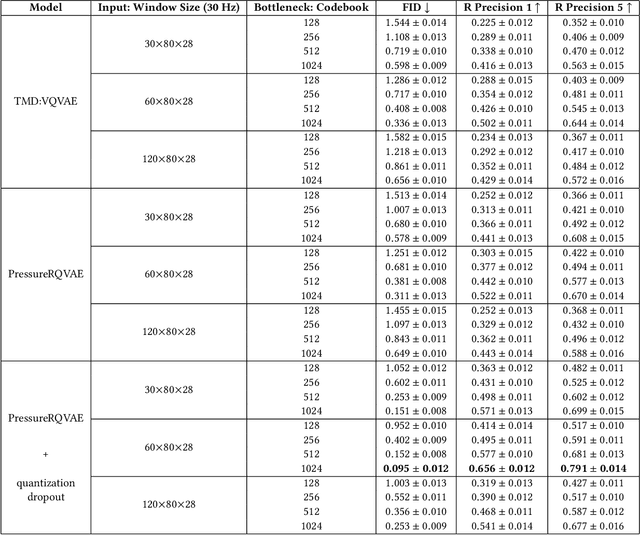


Sensor-based human activity recognition (HAR) has predominantly focused on Inertial Measurement Units and vision data, often overlooking the capabilities unique to pressure sensors, which capture subtle body dynamics and shifts in the center of mass. Despite their potential for postural and balance-based activities, pressure sensors remain underutilized in the HAR domain due to limited datasets. To bridge this gap, we propose to exploit generative foundation models with pressure-specific HAR techniques. Specifically, we present a bidirectional Text$\times$Pressure model that uses generative foundation models to interpret pressure data as natural language. TxP accomplishes two tasks: (1) Text2Pressure, converting activity text descriptions into pressure sequences, and (2) Pressure2Text, generating activity descriptions and classifications from dynamic pressure maps. Leveraging pre-trained models like CLIP and LLaMA 2 13B Chat, TxP is trained on our synthetic PressLang dataset, containing over 81,100 text-pressure pairs. Validated on real-world data for activities such as yoga and daily tasks, TxP provides novel approaches to data augmentation and classification grounded in atomic actions. This consequently improved HAR performance by up to 12.4\% in macro F1 score compared to the state-of-the-art, advancing pressure-based HAR with broader applications and deeper insights into human movement.
Initial Findings on Sensor based Open Vocabulary Activity Recognition via Text Embedding Inversion
Jan 13, 2025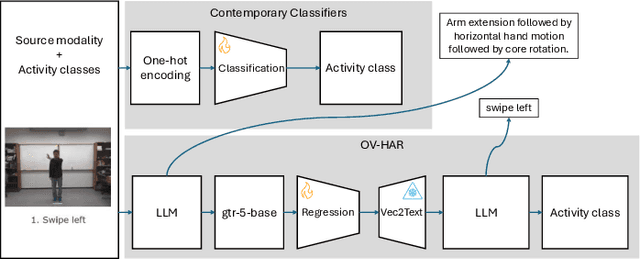
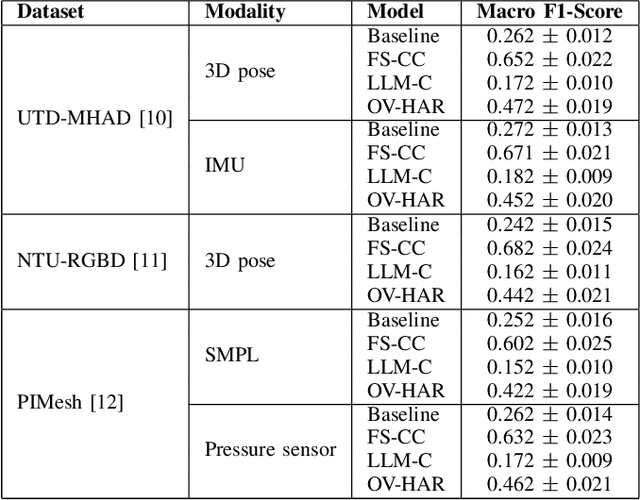
Conventional human activity recognition (HAR) relies on classifiers trained to predict discrete activity classes, inherently limiting recognition to activities explicitly present in the training set. Such classifiers would invariably fail, putting zero likelihood, when encountering unseen activities. We propose Open Vocabulary HAR (OV-HAR), a framework that overcomes this limitation by first converting each activity into natural language and breaking it into a sequence of elementary motions. This descriptive text is then encoded into a fixed-size embedding. The model is trained to regress this embedding, which is subsequently decoded back into natural language using a pre-trained embedding inversion model. Unlike other works that rely on auto-regressive large language models (LLMs) at their core, OV-HAR achieves open vocabulary recognition without the computational overhead of such models. The generated text can be transformed into a single activity class using LLM prompt engineering. We have evaluated our approach on different modalities, including vision (pose), IMU, and pressure sensors, demonstrating robust generalization across unseen activities and modalities, offering a fundamentally different paradigm from contemporary classifiers.
OV-HHIR: Open Vocabulary Human Interaction Recognition Using Cross-modal Integration of Large Language Models
Dec 31, 2024



Understanding human-to-human interactions, especially in contexts like public security surveillance, is critical for monitoring and maintaining safety. Traditional activity recognition systems are limited by fixed vocabularies, predefined labels, and rigid interaction categories that often rely on choreographed videos and overlook concurrent interactive groups. These limitations make such systems less adaptable to real-world scenarios, where interactions are diverse and unpredictable. In this paper, we propose an open vocabulary human-to-human interaction recognition (OV-HHIR) framework that leverages large language models to generate open-ended textual descriptions of both seen and unseen human interactions in open-world settings without being confined to a fixed vocabulary. Additionally, we create a comprehensive, large-scale human-to-human interaction dataset by standardizing and combining existing public human interaction datasets into a unified benchmark. Extensive experiments demonstrate that our method outperforms traditional fixed-vocabulary classification systems and existing cross-modal language models for video understanding, setting the stage for more intelligent and adaptable visual understanding systems in surveillance and beyond.
RAD: Region-Aware Diffusion Models for Image Inpainting
Dec 12, 2024



Diffusion models have achieved remarkable success in image generation, with applications broadening across various domains. Inpainting is one such application that can benefit significantly from diffusion models. Existing methods either hijack the reverse process of a pretrained diffusion model or cast the problem into a larger framework, \ie, conditioned generation. However, these approaches often require nested loops in the generation process or additional components for conditioning. In this paper, we present region-aware diffusion models (RAD) for inpainting with a simple yet effective reformulation of the vanilla diffusion models. RAD utilizes a different noise schedule for each pixel, which allows local regions to be generated asynchronously while considering the global image context. A plain reverse process requires no additional components, enabling RAD to achieve inference time up to 100 times faster than the state-of-the-art approaches. Moreover, we employ low-rank adaptation (LoRA) to fine-tune RAD based on other pretrained diffusion models, reducing computational burdens in training as well. Experiments demonstrated that RAD provides state-of-the-art results both qualitatively and quantitatively, on the FFHQ, LSUN Bedroom, and ImageNet datasets.
Beyond Confusion: A Fine-grained Dialectical Examination of Human Activity Recognition Benchmark Datasets
Dec 12, 2024



The research of machine learning (ML) algorithms for human activity recognition (HAR) has made significant progress with publicly available datasets. However, most research prioritizes statistical metrics over examining negative sample details. While recent models like transformers have been applied to HAR datasets with limited success from the benchmark metrics, their counterparts have effectively solved problems on similar levels with near 100% accuracy. This raises questions about the limitations of current approaches. This paper aims to address these open questions by conducting a fine-grained inspection of six popular HAR benchmark datasets. We identified for some parts of the data, none of the six chosen state-of-the-art ML methods can correctly classify, denoted as the intersect of false classifications (IFC). Analysis of the IFC reveals several underlying problems, including ambiguous annotations, irregularities during recording execution, and misaligned transition periods. We contribute to the field by quantifying and characterizing annotated data ambiguities, providing a trinary categorization mask for dataset patching, and stressing potential improvements for future data collections.
Spend More to Save More (SM2): An Energy-Aware Implementation of Successive Halving for Sustainable Hyperparameter Optimization
Dec 11, 2024


A fundamental step in the development of machine learning models commonly involves the tuning of hyperparameters, often leading to multiple model training runs to work out the best-performing configuration. As machine learning tasks and models grow in complexity, there is an escalating need for solutions that not only improve performance but also address sustainability concerns. Existing strategies predominantly focus on maximizing the performance of the model without considering energy efficiency. To bridge this gap, in this paper, we introduce Spend More to Save More (SM2), an energy-aware hyperparameter optimization implementation based on the widely adopted successive halving algorithm. Unlike conventional approaches including energy-intensive testing of individual hyperparameter configurations, SM2 employs exploratory pretraining to identify inefficient configurations with minimal energy expenditure. Incorporating hardware characteristics and real-time energy consumption tracking, SM2 identifies an optimal configuration that not only maximizes the performance of the model but also enables energy-efficient training. Experimental validations across various datasets, models, and hardware setups confirm the efficacy of SM2 to prevent the waste of energy during the training of hyperparameter configurations.
Past, Present, and Future of Sensor-based Human Activity Recognition using Wearables: A Surveying Tutorial on a Still Challenging Task
Nov 11, 2024In the many years since the inception of wearable sensor-based Human Activity Recognition (HAR), a wide variety of methods have been introduced and evaluated for their ability to recognize activities. Substantial gains have been made since the days of hand-crafting heuristics as features, yet, progress has seemingly stalled on many popular benchmarks, with performance falling short of what may be considered 'sufficient'-- despite the increase in computational power and scale of sensor data, as well as rising complexity in techniques being employed. The HAR community approaches a new paradigm shift, this time incorporating world knowledge from foundational models. In this paper, we take stock of sensor-based HAR -- surveying it from its beginnings to the current state of the field, and charting its future. This is accompanied by a hands-on tutorial, through which we guide practitioners in developing HAR systems for real-world application scenarios. We provide a compendium for novices and experts alike, of methods that aim at finally solving the activity recognition problem.