 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models Defining A New Era In Sensor-based Human Activity Recognition: A Survey And Outlook
Apr 03, 2026Sensor-based Human Activity Recognition (HAR) underpins many ubiquitous and wearable computing applications, yet current models remain limited by scarce labels, sensor heterogeneity, and weak generalization across users, devices, and contexts. Foundation models, which are generally pretrained at scale using self-supervised and multimodal learning, offer a unifying paradigm to address these challenges by learning reusable, adaptable representations for activity understanding. This survey synthesizes emerging foundation models for sensor-based HAR. We first clarify foundational concepts, definitions, and evaluation criteria, then organize existing work using a lifecycle-oriented taxonomy spanning input design, pretraining, adaptation, and utilization. Rather than enumerating individual models, we analyze recurring design patterns and trade-offs across nine technical axes, including modality scope, tokenization, architectures, learning paradigms, adaptation mechanisms, and deployment settings. From this synthesis, we identify three dominant development trajectories: (1) HAR-specific foundation models trained from scratch on large sensor corpora, (2) adaptation of general time-series or multimodal foundation models to sensor-based HAR, and (3) integration of large language models for reasoning, annotation, and human-AI interaction. We conclude by highlighting open challenges in data curation, multimodal alignment, personalization, privacy, and responsible deployment, and outline directions toward general-purpose, interpretable, and human-centered foundation models for activity understanding. A complete, continuously updated index of papers and models is available in our companion repository: https://github.com/zhaxidele/Foundation-Models-Defining-A-New-Era-In-Human-Activity-Recognition.
ActivityNarrated: An Open-Ended Narrative Paradigm for Wearable Human Activity Understanding
Apr 01, 2026Wearable HAR has improved steadily, but most progress still relies on closed-set classification, which limits real-world use. In practice, human activity is open-ended, unscripted, personalized, and often compositional, unfolding as narratives rather than instances of fixed classes. We argue that addressing this gap does not require simply scaling datasets or models. It requires a fundamental shift in how wearable HAR is formulated, supervised, and evaluated. This work shows how to model open-ended activity narratives by aligning wearable sensor data with natural-language descriptions in an open-vocabulary setting. Our framework has three core components. First, we introduce a naturalistic data collection and annotation pipeline that combines multi-position wearable sensing with free-form, time-aligned narrative descriptions of ongoing behavior, allowing activity semantics to emerge without a predefined vocabulary. Second, we define a retrieval-based evaluation framework that measures semantic alignment between sensor data and language, enabling principled evaluation without fixed classes while also subsuming closed-set classification as a special case. Third, we present a language-conditioned learning architecture that supports sensor-to-text inference over variable-length sensor streams and heterogeneous sensor placements. Experiments show that models trained with fixed-label objectives degrade sharply under real-world variability, while open-vocabulary sensor-language alignment yields robust and semantically grounded representations. Once this alignment is learned, closed-set activity recognition becomes a simple downstream task. Under cross-participant evaluation, our method achieves 65.3% Macro-F1, compared with 31-34% for strong closed-set HAR baselines. These results establish open-ended narrative modeling as a practical and effective foundation for real-world wearable HAR.
SPECTRA: An Efficient Spectral-Informed Neural Network for Sensor-Based Activity Recognition
Mar 27, 2026Real time sensor based applications in pervasive computing require edge deployable models to ensure low latency privacy and efficient interaction. A prime example is sensor based human activity recognition where models must balance accuracy with stringent resource constraints. Yet many deep learning approaches treat temporal sensor signals as black box sequences overlooking spectral temporal structure while demanding excessive computation. We present SPECTRA a deployment first co designed spectral temporal architecture that integrates short time Fourier transform STFT feature extraction depthwise separable convolutions and channel wise self attention to capture spectral temporal dependencies under real edge runtime and memory constraints. A compact bidirectional GRU with attention pooling summarizes within window dynamics at low cost reducing downstream model burden while preserving accuracy. Across five public HAR datasets SPECTRA matches or approaches larger CNN LSTM and Transformer baselines while substantially reducing parameters latency and energy. Deployments on a Google Pixel 9 smartphone and an STM32L4 microcontroller further demonstrate end to end deployable realtime private and efficient HAR.
Interpretable Multimodal Gesture Recognition for Drone and Mobile Robot Teleoperation via Log-Likelihood Ratio Fusion
Mar 05, 2026Human operators are still frequently exposed to hazardous environments such as disaster zones and industrial facilities, where intuitive and reliable teleoperation of mobile robots and Unmanned Aerial Vehicles (UAVs) is essential. In this context, hands-free teleoperation enhances operator mobility and situational awareness, thereby improving safety in hazardous environments. While vision-based gesture recognition has been explored as one method for hands-free teleoperation, its performance often deteriorates under occlusions, lighting variations, and cluttered backgrounds, limiting its applicability in real-world operations. To overcome these limitations, we propose a multimodal gesture recognition framework that integrates inertial data (accelerometer, gyroscope, and orientation) from Apple Watches on both wrists with capacitive sensing signals from custom gloves. We design a late fusion strategy based on the log-likelihood ratio (LLR), which not only enhances recognition performance but also provides interpretability by quantifying modality-specific contributions. To support this research, we introduce a new dataset of 20 distinct gestures inspired by aircraft marshalling signals, comprising synchronized RGB video, IMU, and capacitive sensor data. Experimental results demonstrate that our framework achieves performance comparable to a state-of-the-art vision-based baseline while significantly reducing computational cost, model size, and training time, making it well suited for real-time robot control. We therefore underscore the potential of sensor-based multimodal fusion as a robust and interpretable solution for gesture-driven mobile robot and drone teleoperation.
SImpHAR: Advancing impedance-based human activity recognition using 3D simulation and text-to-motion models
Jul 08, 2025
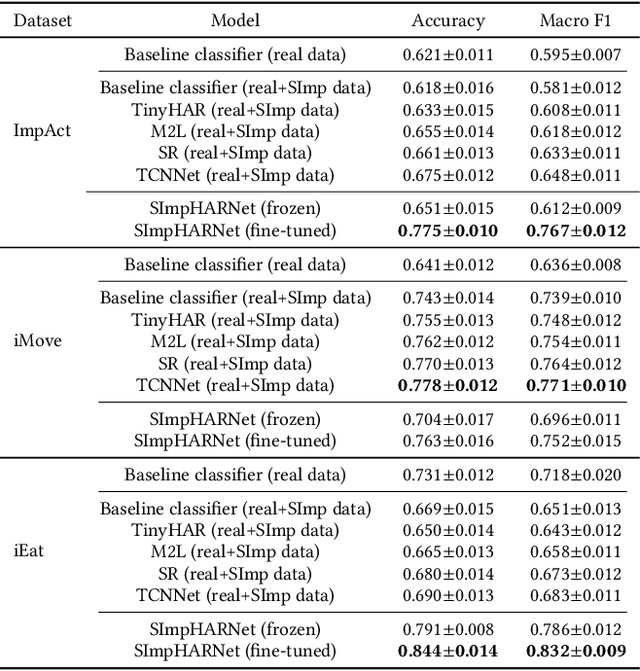


Human Activity Recognition (HAR) with wearable sensors is essential for applications in healthcare, fitness, and human-computer interaction. Bio-impedance sensing offers unique advantages for fine-grained motion capture but remains underutilized due to the scarcity of labeled data. We introduce SImpHAR, a novel framework addressing this limitation through two core contributions. First, we propose a simulation pipeline that generates realistic bio-impedance signals from 3D human meshes using shortest-path estimation, soft-body physics, and text-to-motion generation serving as a digital twin for data augmentation. Second, we design a two-stage training strategy with decoupled approach that enables broader activity coverage without requiring label-aligned synthetic data. We evaluate SImpHAR on our collected ImpAct dataset and two public benchmarks, showing consistent improvements over state-of-the-art methods, with gains of up to 22.3% and 21.8%, in terms of accuracy and macro F1 score, respectively. Our results highlight the promise of simulation-driven augmentation and modular training for impedance-based HAR.
TxP: Reciprocal Generation of Ground Pressure Dynamics and Activity Descriptions for Improving Human Activity Recognition
May 04, 2025
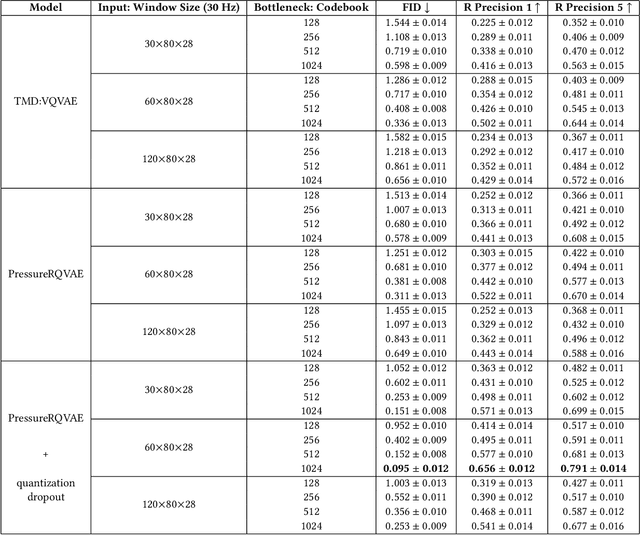


Sensor-based human activity recognition (HAR) has predominantly focused on Inertial Measurement Units and vision data, often overlooking the capabilities unique to pressure sensors, which capture subtle body dynamics and shifts in the center of mass. Despite their potential for postural and balance-based activities, pressure sensors remain underutilized in the HAR domain due to limited datasets. To bridge this gap, we propose to exploit generative foundation models with pressure-specific HAR techniques. Specifically, we present a bidirectional Text$\times$Pressure model that uses generative foundation models to interpret pressure data as natural language. TxP accomplishes two tasks: (1) Text2Pressure, converting activity text descriptions into pressure sequences, and (2) Pressure2Text, generating activity descriptions and classifications from dynamic pressure maps. Leveraging pre-trained models like CLIP and LLaMA 2 13B Chat, TxP is trained on our synthetic PressLang dataset, containing over 81,100 text-pressure pairs. Validated on real-world data for activities such as yoga and daily tasks, TxP provides novel approaches to data augmentation and classification grounded in atomic actions. This consequently improved HAR performance by up to 12.4\% in macro F1 score compared to the state-of-the-art, advancing pressure-based HAR with broader applications and deeper insights into human movement.
Initial Findings on Sensor based Open Vocabulary Activity Recognition via Text Embedding Inversion
Jan 13, 2025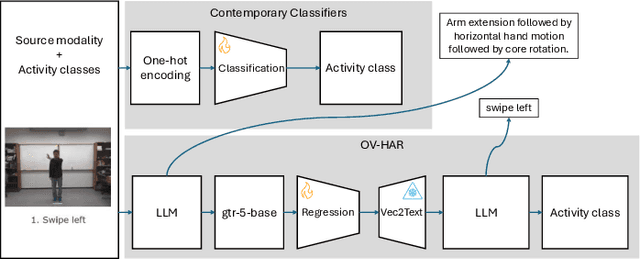
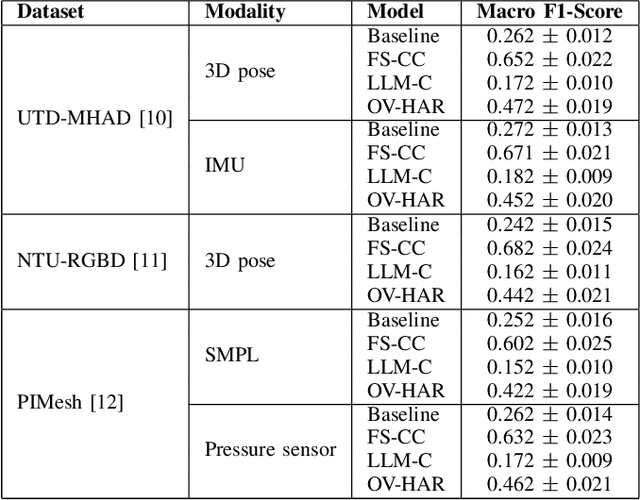
Conventional human activity recognition (HAR) relies on classifiers trained to predict discrete activity classes, inherently limiting recognition to activities explicitly present in the training set. Such classifiers would invariably fail, putting zero likelihood, when encountering unseen activities. We propose Open Vocabulary HAR (OV-HAR), a framework that overcomes this limitation by first converting each activity into natural language and breaking it into a sequence of elementary motions. This descriptive text is then encoded into a fixed-size embedding. The model is trained to regress this embedding, which is subsequently decoded back into natural language using a pre-trained embedding inversion model. Unlike other works that rely on auto-regressive large language models (LLMs) at their core, OV-HAR achieves open vocabulary recognition without the computational overhead of such models. The generated text can be transformed into a single activity class using LLM prompt engineering. We have evaluated our approach on different modalities, including vision (pose), IMU, and pressure sensors, demonstrating robust generalization across unseen activities and modalities, offering a fundamentally different paradigm from contemporary classifiers.
OV-HHIR: Open Vocabulary Human Interaction Recognition Using Cross-modal Integration of Large Language Models
Dec 31, 2024



Understanding human-to-human interactions, especially in contexts like public security surveillance, is critical for monitoring and maintaining safety. Traditional activity recognition systems are limited by fixed vocabularies, predefined labels, and rigid interaction categories that often rely on choreographed videos and overlook concurrent interactive groups. These limitations make such systems less adaptable to real-world scenarios, where interactions are diverse and unpredictable. In this paper, we propose an open vocabulary human-to-human interaction recognition (OV-HHIR) framework that leverages large language models to generate open-ended textual descriptions of both seen and unseen human interactions in open-world settings without being confined to a fixed vocabulary. Additionally, we create a comprehensive, large-scale human-to-human interaction dataset by standardizing and combining existing public human interaction datasets into a unified benchmark. Extensive experiments demonstrate that our method outperforms traditional fixed-vocabulary classification systems and existing cross-modal language models for video understanding, setting the stage for more intelligent and adaptable visual understanding systems in surveillance and beyond.
ALS-HAR: Harnessing Wearable Ambient Light Sensors to Enhance IMU-based Human Activity Recogntion
Aug 22, 2024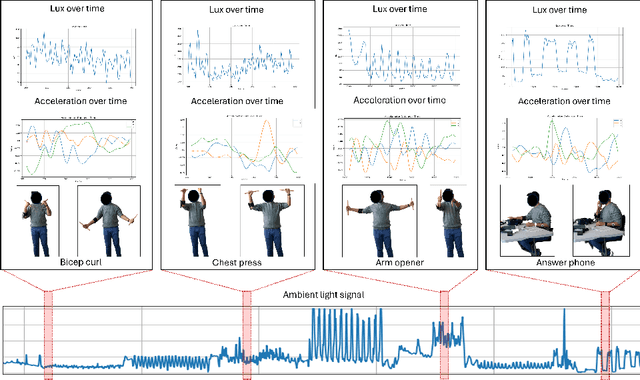
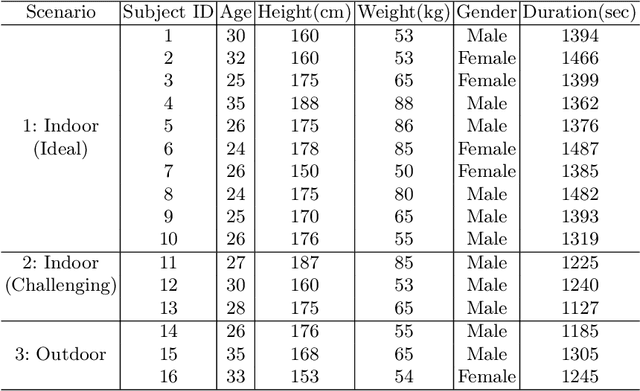
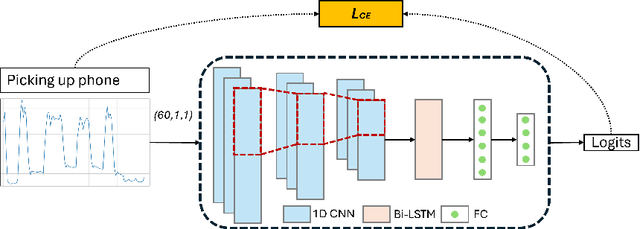
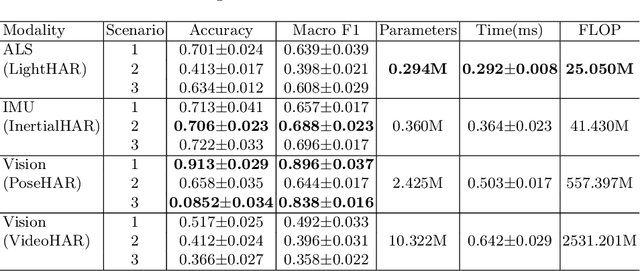
Despite the widespread integration of ambient light sensors (ALS) in smart devices commonly used for screen brightness adaptation, their application in human activity recognition (HAR), primarily through body-worn ALS, is largely unexplored. In this work, we developed ALS-HAR, a robust wearable light-based motion activity classifier. Although ALS-HAR achieves comparable accuracy to other modalities, its natural sensitivity to external disturbances, such as changes in ambient light, weather conditions, or indoor lighting, makes it challenging for daily use. To address such drawbacks, we introduce strategies to enhance environment-invariant IMU-based activity classifications through augmented multi-modal and contrastive classifications by transferring the knowledge extracted from the ALS. Our experiments on a real-world activity dataset for three different scenarios demonstrate that while ALS-HAR's accuracy strongly relies on external lighting conditions, cross-modal information can still improve other HAR systems, such as IMU-based classifiers.Even in scenarios where ALS performs insufficiently, the additional knowledge enables improved accuracy and macro F1 score by up to 4.2 % and 6.4 %, respectively, for IMU-based classifiers and even surpasses multi-modal sensor fusion models in two of our three experiment scenarios. Our research highlights the untapped potential of ALS integration in advancing sensor-based HAR technology, paving the way for practical and efficient wearable ALS-based activity recognition systems with potential applications in healthcare, sports monitoring, and smart indoor environments.
Enhancing Inertial Hand based HAR through Joint Representation of Language, Pose and Synthetic IMUs
Jun 03, 2024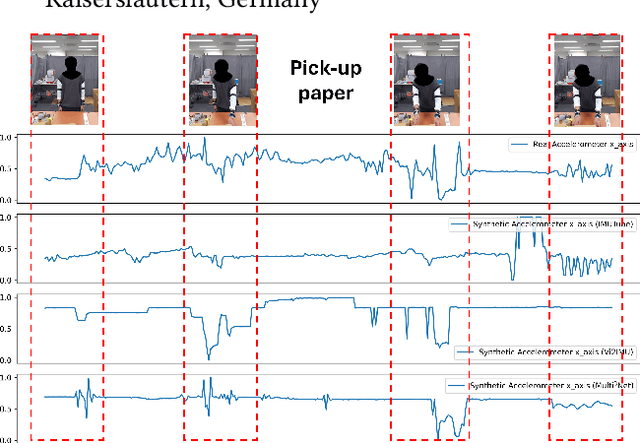
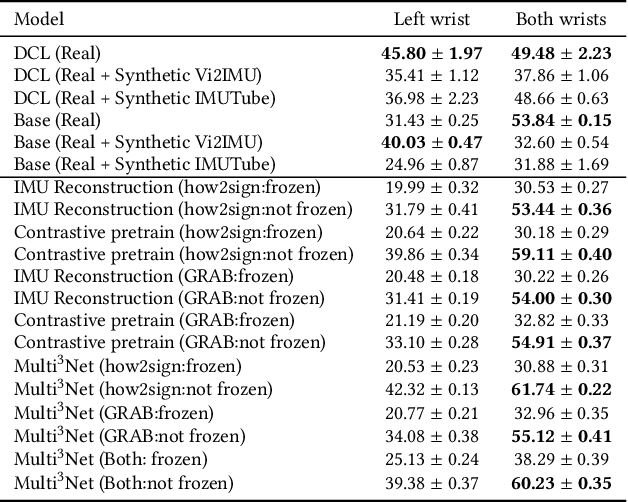
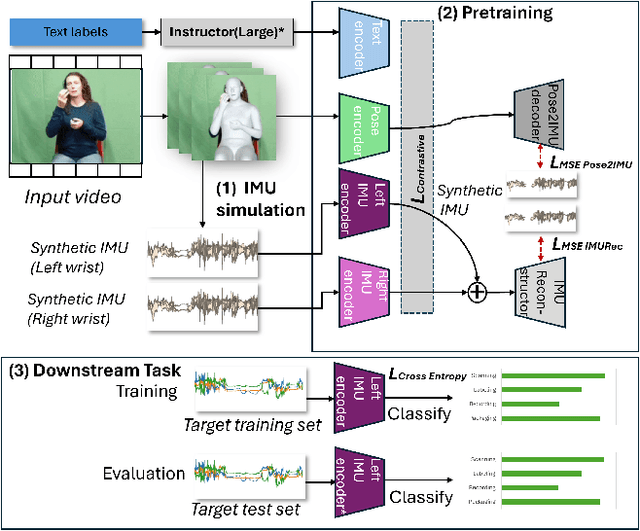
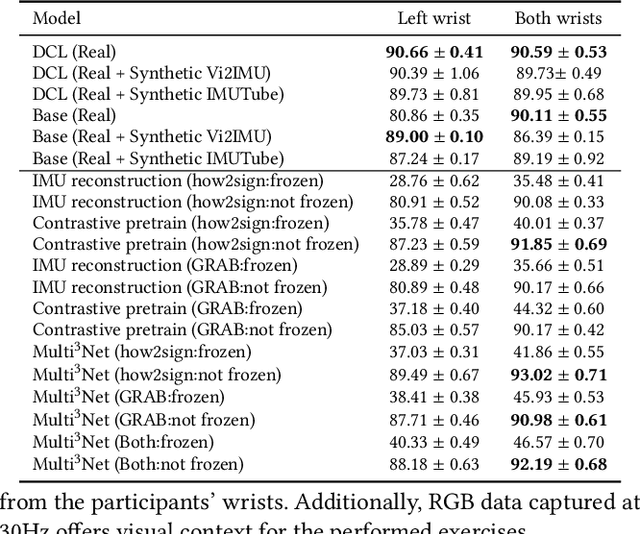
Due to the scarcity of labeled sensor data in HAR, prior research has turned to video data to synthesize Inertial Measurement Units (IMU) data, capitalizing on its rich activity annotations. However, generating IMU data from videos presents challenges for HAR in real-world settings, attributed to the poor quality of synthetic IMU data and its limited efficacy in subtle, fine-grained motions. In this paper, we propose Multi$^3$Net, our novel multi-modal, multitask, and contrastive-based framework approach to address the issue of limited data. Our pretraining procedure uses videos from online repositories, aiming to learn joint representations of text, pose, and IMU simultaneously. By employing video data and contrastive learning, our method seeks to enhance wearable HAR performance, especially in recognizing subtle activities.Our experimental findings validate the effectiveness of our approach in improving HAR performance with IMU data. We demonstrate that models trained with synthetic IMU data generated from videos using our method surpass existing approaches in recognizing fine-grained activities.