 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoPilot: Training-Free Ultrasound Video Segmentation via Scale-Space Semantic Prompting and Reliability-Gated Memory
May 25, 2026Ultrasound video segmentation is clinically valuable yet difficult due to speckle noise, weak boundaries, and rapid anatomical deformation. Recent promptable foundation models enable point-guided segmentation, but their direct deployment in ultrasound remains unreliable: a single point provides insufficient spatial context to resolve scale ambiguity, and greedy memory updates amplify early errors into severe temporal drift. We present EchoPilot, a training-free framework for ultrasound video segmentation under sparse first-frame interaction, requiring only a single point click and an anatomical category name. EchoPilot orchestrates a frozen medical vision-language model (VLM) for semantic localization, a vision foundation model (VFM) for dense geometric feature extraction, and a promptable video segmentor for mask prediction and propagation. To resolve initialization ambiguity, we propose Scale-Space Semantic Prompting, which first selects an optimal contextual view via a parameter-free S.E.E.D. (Semantic Energy-Entropy Density) criterion, and then synthesizes geometrically precise auxiliary point prompts from dense foundation features without additional user interaction. To reduce propagation drift, a Reliability-Gated Memory update is further introduced to selectively freeze the segmentor's memory bank under uncertain predictions, preventing error accumulation. We also contribute the first dynamic fetal placenta ultrasound video segmentation dataset with 671 annotated frames. Across three ultrasound video datasets, EchoPilot achieves state-of-the-art performance under the sparse-interactive setting, consistently outperforming training-free baselines and finetuned specialists.
Seeing Inside the Storm: Improving Nowcasting by Integrating Meteorological Drivers
May 22, 2026Most nowcasting systems, built on radar reflectivity, focus on current precipitation, ignoring the atmospheric precursors -- such as low-level convergence, turbulent eddies, and latent heating -- that offer a fleeting window to foresee storm birth. We introduce MeteoLogist, a physics-inspired radar intelligence framework that models the full life cycle of convection -- from its precursors to organized storm evolution. However, exploiting these precursors is non-trivial: they originate from multiple meteorological drivers -- thermodynamic, kinematic, and microphysical -- that evolve asynchronously (C1) and remain spatially fragmented (C2). To this end, MeteoLogist designs three tightly integrated components. The Physics-Tailored Encoders process radar echoes according to their intrinsic physical scales and semantics, forming thermodynamic, kinematic, and microphysical streams that capture distinct dynamical regimes. The Temporal-Phase Aligner addresses C1 by leveraging causal temporal attention to capture when and how different drivers interact and activate. The Cross-Field Spatial Aggregator addresses C2 through cross-regional fusion, aligning weak and scattered precursors across neighboring cells to expose upstream triggers and enforce spatial coherence. Evaluated on 3D-NEXRAD (2020--2022, US-wide), MeteoLogist boosts high-impact detection (CSI40) by +9.7% over strong baselines, and achieves a remarkable 37.67% gain during the storm-developing stage -- demonstrating true foresight in sensing storms before they appear. The code can be found in the supplementary material.
FED-FSTQ: Fisher-Guided Token Quantization for Communication-Efficient Federated Fine-Tuning of LLMs on Edge Devices
Apr 28, 2026Federated fine-tuning provides a practical route to adapt large language models (LLMs) on edge devices without centralizing private data, yet in mobile deployments the training wall-clock is often bottlenecked by straggler-limited uplink communication under heterogeneous bandwidth and intermittent participation. Although parameter-efficient fine-tuning (PEFT) reduces trainable parameters, per-round payloads remain prohibitive in non-IID regimes, where uniform compression can discard rare but task-critical signals. We propose Fed-FSTQ, a Fisher-guided token quantization system primitive for communication-efficient federated LLM fine-tuning. Fed-FSTQ employs a lightweight Fisher proxy to estimate token sensitivity, coupling importance-aware token selection with non-uniform mixed-precision quantization to allocate higher fidelity to informative evidence while suppressing redundant transmission. The method is model-agnostic, serves as a drop-in module for standard federated PEFT pipelines, e.g., LoRA, without modifying the server aggregation rule, and supports bandwidth-heterogeneous clients via compact sparse message packing. Experiments on multilingual QA and medical QA under non-IID partitions show that Fed-FSTQ reduces cumulative uplink traffic required to reach a fixed quality threshold by 46x relative to a standard LoRA baseline, and improves end-to-end wall-clock time-to-accuracy by 52%. Furthermore, enabling Fisher-guided token reduction at inference yields up to a 1.55x end-to-end speedup on NVIDIA Jetson-class edge devices, demonstrating deployability under tight resource constraints.
PI-TTA: Physics-Informed Source-Free Test-Time Adaptation for Robust Human Activity Recognition on Mobile Devices
Apr 28, 2026Source-free test-time adaptation (TTA) is appealing for mobile and wearable sensing because it enables on-device personalization from unlabeled test streams without centralizing private data. However, sensor-based human activity recognition (HAR) poses challenges that are less pronounced in standard vision benchmarks: behavioral inertial streams are temporally correlated and often exhibit within-session shifts caused by sensor rotation, placement change, and sampling-rate drift. Under this streaming non-i.i.d. setting, widely used vision-style TTA objectives can become unstable, leading to overconfident errors, representation collapse, and catastrophic forgetting. We propose PI-TTA, a lightweight source-free adaptation framework that stabilizes online updates through three physics-consistent constraints: gravity consistency, short-horizon temporal continuity, and spectral stability. PI-TTA updates the same small parameter subset as strong source-free baselines and incurs only modest overhead, making it suitable for on-device deployment. Experiments on USCHAD, PAMAP2, and mHealth under long-sequence stress tests and factorized shift protocols show that PI-TTA mitigates the severe degradation observed in confidence-driven baselines and preserves stable adaptation under sustained streaming conditions. It improves long-sequence accuracy by up to 9.13% and reduces physical-violation rates by 27.5%, 24.1%, and 45.4% on USCHAD, PAMAP2, and mHealth, respectively. These results demonstrate that physics-informed adaptation can improve accuracy, stability, and deployment reliability for real-world mobile sensing systems.
Argus: Reorchestrating Static Analysis via a Multi-Agent Ensemble for Full-Chain Security Vulnerability Detection
Apr 08, 2026Recent advancements in Large Language Models (LLMs) have sparked interest in their application to Static Application Security Testing (SAST), primarily due to their superior contextual reasoning capabilities compared to traditional symbolic or rule-based methods. However, existing LLM-based approaches typically attempt to replace human experts directly without integrating effectively with existing SAST tools. This lack of integration results in ineffectiveness, including high rates of false positives, hallucinations, limited reasoning depth, and excessive token usage, making them impractical for industrial deployment. To overcome these limitations, we present a paradigm shift that reorchestrates the SAST workflow from current LLM-assisted structure to a new LLM-centered workflow. We introduce Argus (Agentic and Retrieval-Augmented Guarding System), the first multi-agent framework designed specifically for vulnerability detection. Argus incorporates three key novelties: comprehensive supply chain analysis, collaborative multi-agent workflows, and the integration of state-of-the-art techniques such as Retrieval-Augmented Generation (RAG) and ReAct to minimize hallucinations and enhance reasoning. Extensive empirical evaluation demonstrates that Argus significantly outperforms existing methods by detecting a higher volume of true vulnerabilities while simultaneously reducing false positives and operational costs. Notably, Argus has identified several critical zero-day vulnerabilities with CVE assignments.
Wi-Spike: A Low-power WiFi Human Multi-action Recognition Model with Spiking Neural Networks
Mar 15, 2026WiFi-based human action recognition (HAR) has gained significant attention due to its non-intrusive and privacy-preserving nature. However, most existing WiFi sensing models predominantly focus on improving recognition accuracy, while issues of power consumption and energy efficiency remain insufficiently discussed. In this work, we present Wi-Spike, a bio-inspired spiking neural network (SNN) framework for efficient and accurate action recognition using WiFi channel state information (CSI) signals. Specifically, leveraging the event-driven and low-power characteristics of SNNs, Wi-Spike introduces spiking convolutional layers for spatio-temporal feature extraction and a novel temporal attention mechanism to enhance discriminative representation. The extracted features are subsequently encoded and classified through spiking fully connected layers and a voting layer. Comprehensive experiments on three benchmark datasets (NTU-Fi-HAR, NTU-Fi-HumanID, and UT-HAR) demonstrate that Wi-Spike achieves competitive accuracy in single-action recognition and superior performance in multi-action recognition tasks. As for energy consumption, Wi-Spike reduces the energy cost by at least half compared with other methods, while still achieving 95.83% recognition accuracy in human activity recognition. More importantly, Wi-Spike establishes a new state-of-the-art in WiFi-based multi-action HAR, offering a promising solution for real-time, energy-efficient edge sensing applications.
CPMamba: Selective State Space Models for MIMO Channel Prediction in High-Mobility Environments
Dec 18, 2025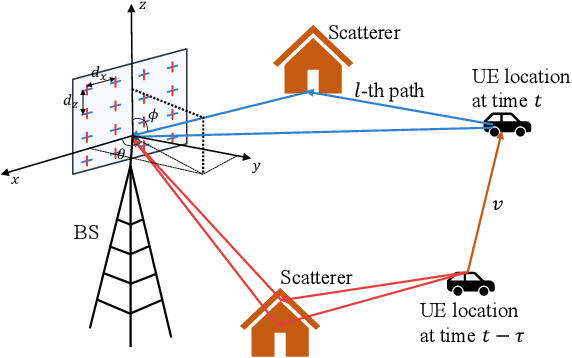
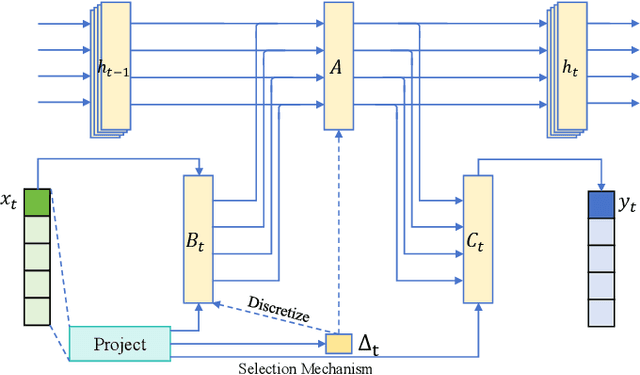
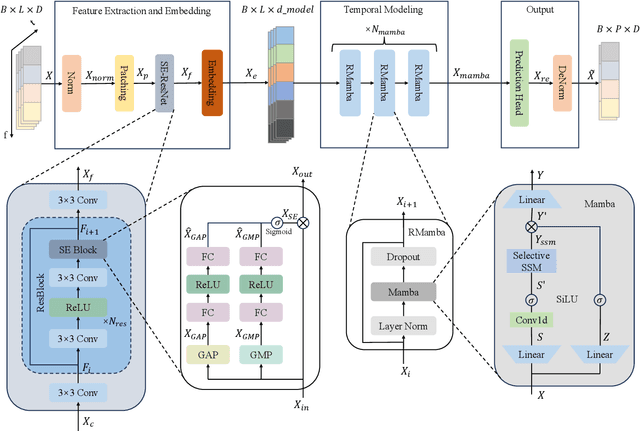
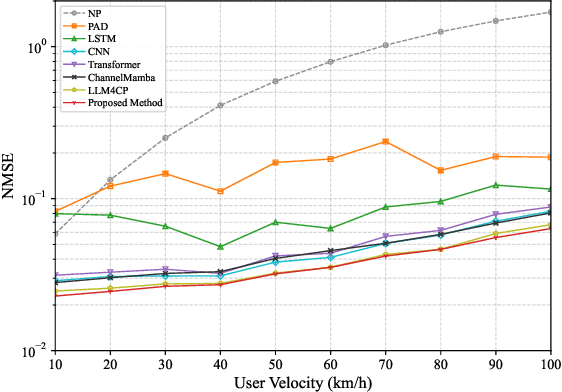
Channel prediction is a key technology for improving the performance of various functions such as precoding, adaptive modulation, and resource allocation in MIMO-OFDM systems. Especially in high-mobility scenarios with fast time-varying channels, it is crucial for resisting channel aging and ensuring communication quality. However, existing methods suffer from high complexity and the inability to accurately model the temporal variations of channels. To address this issue, this paper proposes CPMamba -- an efficient channel prediction framework based on the selective state space model. The proposed CPMamba architecture extracts features from historical channel state information (CSI) using a specifically designed feature extraction and embedding network and employs stacked residual Mamba modules for temporal modeling. By leveraging an input-dependent selective mechanism to dynamically adjust state transitions, it can effectively capture the long-range dependencies between the CSIs while maintaining a linear computational complexity. Simulation results under the 3GPP standard channel model demonstrate that CPMamba achieves state-of-the-art prediction accuracy across all scenarios, along with superior generalization and robustness. Compared to existing baseline models, CPMamba reduces the number of parameters by approximately 50 percent while achieving comparable or better performance, thereby significantly lowering the barrier for practical deployment.
SpectralAdapt: Semi-Supervised Domain Adaptation with Spectral Priors for Human-Centered Hyperspectral Image Reconstruction
Nov 17, 2025Hyperspectral imaging (HSI) holds great potential for healthcare due to its rich spectral information. However, acquiring HSI data remains costly and technically demanding. Hyperspectral image reconstruction offers a practical solution by recovering HSI data from accessible modalities, such as RGB. While general domain datasets are abundant, the scarcity of human HSI data limits progress in medical applications. To tackle this, we propose SpectralAdapt, a semi-supervised domain adaptation (SSDA) framework that bridges the domain gap between general and human-centered HSI datasets. To fully exploit limited labels and abundant unlabeled data, we enhance spectral reasoning by introducing Spectral Density Masking (SDM), which adaptively masks RGB channels based on their spectral complexity, encouraging recovery of informative regions from complementary cues during consistency training. Furthermore, we introduce Spectral Endmember Representation Alignment (SERA), which derives physically interpretable endmembers from valuable labeled pixels and employs them as domain-invariant anchors to guide unlabeled predictions, with momentum updates ensuring adaptability and stability. These components are seamlessly integrated into SpectralAdapt, a spectral prior-guided framework that effectively mitigates domain shift, spectral degradation, and data scarcity in HSI reconstruction. Experiments on benchmark datasets demonstrate consistent improvements in spectral fidelity, cross-domain generalization, and training stability, highlighting the promise of SSDA as an efficient solution for hyperspectral imaging in healthcare.
DACA-Net: A Degradation-Aware Conditional Diffusion Network for Underwater Image Enhancement
Jul 30, 2025Underwater images typically suffer from severe colour distortions, low visibility, and reduced structural clarity due to complex optical effects such as scattering and absorption, which greatly degrade their visual quality and limit the performance of downstream visual perception tasks. Existing enhancement methods often struggle to adaptively handle diverse degradation conditions and fail to leverage underwater-specific physical priors effectively. In this paper, we propose a degradation-aware conditional diffusion model to enhance underwater images adaptively and robustly. Given a degraded underwater image as input, we first predict its degradation level using a lightweight dual-stream convolutional network, generating a continuous degradation score as semantic guidance. Based on this score, we introduce a novel conditional diffusion-based restoration network with a Swin UNet backbone, enabling adaptive noise scheduling and hierarchical feature refinement. To incorporate underwater-specific physical priors, we further propose a degradation-guided adaptive feature fusion module and a hybrid loss function that combines perceptual consistency, histogram matching, and feature-level contrast. Comprehensive experiments on benchmark datasets demonstrate that our method effectively restores underwater images with superior colour fidelity, perceptual quality, and structural details. Compared with SOTA approaches, our framework achieves significant improvements in both quantitative metrics and qualitative visual assessments.
Period-LLM: Extending the Periodic Capability of Multimodal Large Language Model
May 30, 2025



Periodic or quasi-periodic phenomena reveal intrinsic characteristics in various natural processes, such as weather patterns, movement behaviors, traffic flows, and biological signals. Given that these phenomena span multiple modalities, the capabilities of Multimodal Large Language Models (MLLMs) offer promising potential to effectively capture and understand their complex nature. However, current MLLMs struggle with periodic tasks due to limitations in: 1) lack of temporal modelling and 2) conflict between short and long periods. This paper introduces Period-LLM, a multimodal large language model designed to enhance the performance of periodic tasks across various modalities, and constructs a benchmark of various difficulty for evaluating the cross-modal periodic capabilities of large models. Specially, We adopt an "Easy to Hard Generalization" paradigm, starting with relatively simple text-based tasks and progressing to more complex visual and multimodal tasks, ensuring that the model gradually builds robust periodic reasoning capabilities. Additionally, we propose a "Resisting Logical Oblivion" optimization strategy to maintain periodic reasoning abilities during semantic alignment. Extensive experiments demonstrate the superiority of the proposed Period-LLM over existing MLLMs in periodic tasks. The code is available at https://github.com/keke-nice/Period-LLM.